Real-time data beats slow data in almost all use cases. But as essential is data consistency across all systems, including non-real-time legacy systems and modern request-response APIs. Apache Kafka’s most underestimated feature is the storage component based on the append-only commit log. It enables loose coupling for domain-driven design with microservices and independent data products in a data mesh. This blog post explores how Kafka enables data consistency with a real-world case study from financial services.
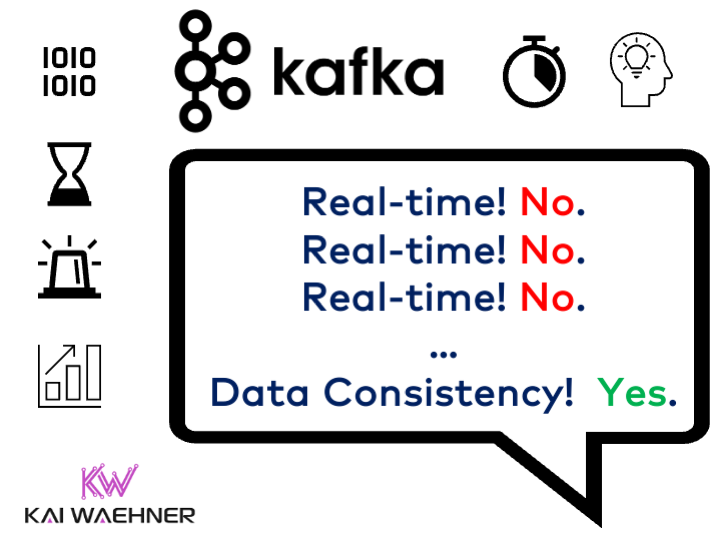
Apache Kafka = Real-time data streaming
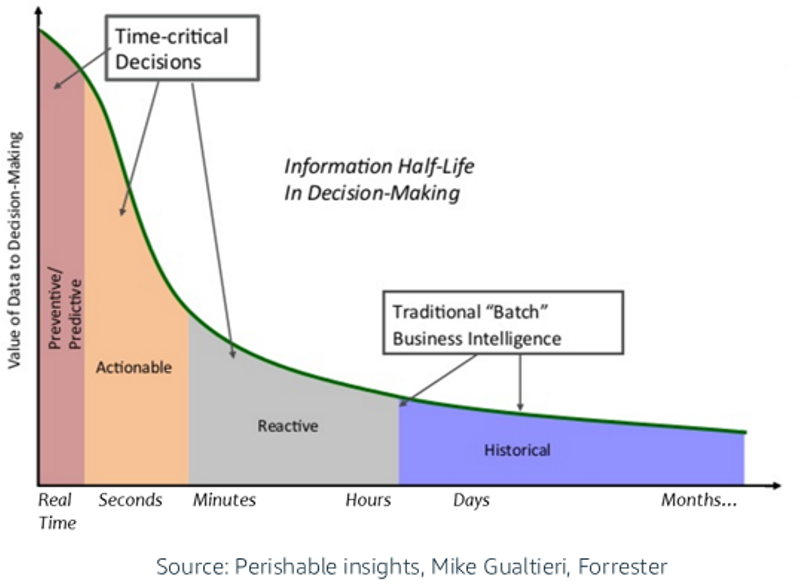
Real-time beats slow data. It is that easy in almost all use cases. Ask any executive or business person: What’s better? If you can consume and use information now or later? The value of data goes down over time:
Apache Kafka is the de facto standard for real-time data streaming. Check out the data streaming landscape 2023 to learn more about Kafka-related products and cloud services.
So far, so good. However, one valid question always comes up: “Why is Apache Kafka different from a real-time message broker like RabbitMQ, IBM MQ, NATS, or Amazon SQS?”
TL;DR: Message brokers provide real-time messaging capabilities to produce and consume messages. Apache Kafka is a data streaming platform that combines messaging, storage, data integration, and stream processing capabilities.
My comparison of message brokers and data streaming explored the differences using ten characteristics. It is all about the storage component of Apache Kafka in the discussion of data consistency. Let’s explore why…
Real-time means many things…
… from deterministic systems with hard real-time up to minutes or even hours. Always define your requirements for real-time data processing and the end-to-end latency (not just the messaging component).
I clarified when to use Apache Kafka for real-time workloads in separate blog posts:
- When (not) to use Apache Kafka in financial services for core banking, trading, and fraud detection
- When (not) to use Apache Kafka in Industrial IoT and IT/OT edge environments
- When (not) to use Apache Kafka at all (because other tools are built for that purpose)?
Data consistency = The biggest challenge of the enterprise architecture
Data consistency refers to whether the same data kept at different places does or does not match. The data is processed in many ways across the enterprise architecture:
- Real-time: Message brokers or data streaming platforms transfer or process data when it is in motion.
- Near real-time: Platforms ingest data into data lakes and data warehouses in seconds or minutes.
- Batch: Reporting and analytics of historical data.
- Request-response: Interactive API or SQL queries to collect specific information.
- A point-in-time replay of historical data: Troubleshooting, incident management, regulatory reporting, and similar scenarios.
The applications and data platforms use very different (old and new) technologies, products, cloud services, and APIs. Integration and data consistency across the different communication paradigms is a massive challenge within the spaghetti architecture:
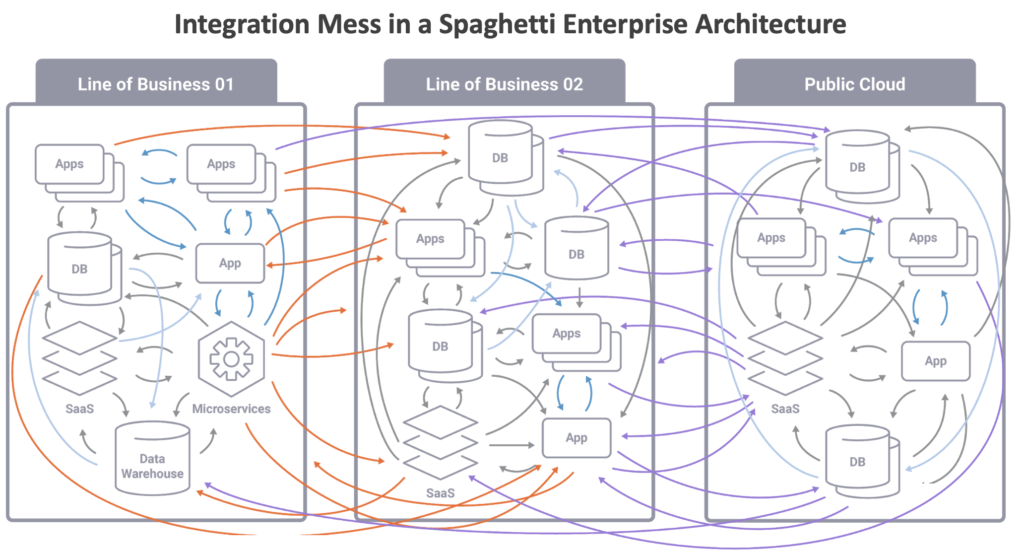
The consequence of inconsistent data is obvious:
- Bad customer experience, e.g., late notification about flight delays or cancellations.
- Revenue loss, e.g., inventory not up-to-date, missed or too late detection of fraud.
- Increased cost, e.g., slow or wrong decisions in logistics across the supply chain.
- Increased risk, e.g., unrecognized data breaches, compliance issues.
This is where the storage component of Apache Kafka makes the difference…
Apache Kafka = Streaming platform to decouple any application and communication paradigm
Kafka is an append-only commit log. Consumers are independent of each other and independent of producers. They interact at their own pace with their own communication paradigm and pull the information from the Kafka log.
This enables independent consumption and processing of data consistently. It does not matter what technology or communication paradigm the downstream consumer application uses:
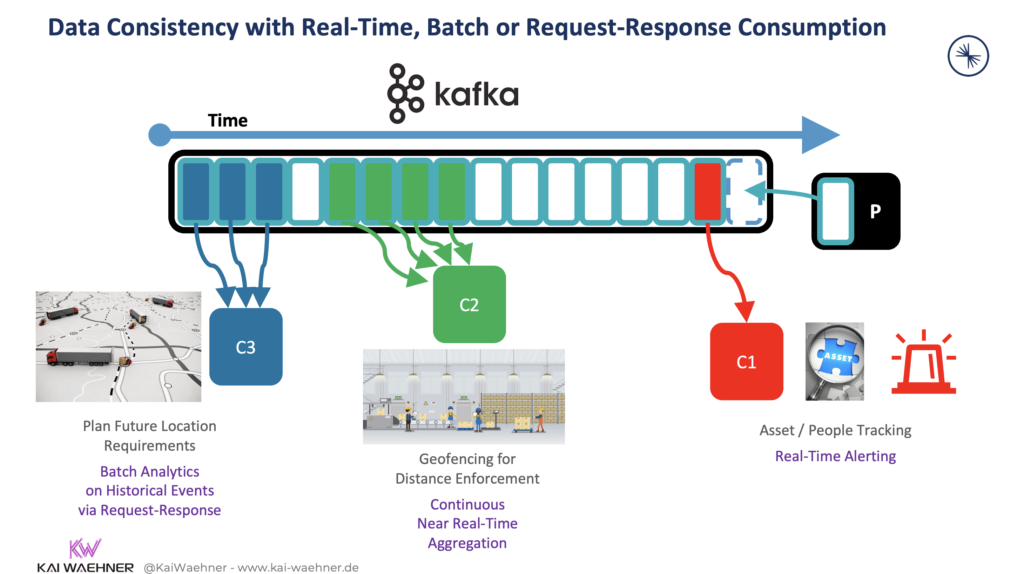
This example of a real-time locating system (RTLS) for asset tracking can be built with Kafka straightforwardly. Downstream applications consume events in real-time, near real-time, batch, or via request-response HTTP/REST APIs. With other technologies, like real-time message queues, you need to add additional platforms for storage, integration, and data processing. Data streaming provides a single (scalable and reliable) platform.
Apache Kafka enables domain-driven design and data mesh architectures
Domain-driven Design (DDD) needs decoupled applications. Push-based message brokers or HTTP/REST web services enforce tight coupling between the systems. This creates the above spaghetti architecture.
On the other side, Apache Kafka truly decouples the domains, no matter what technologies or communication paradigms each domain uses. Loose coupling is the norm with Kafka:
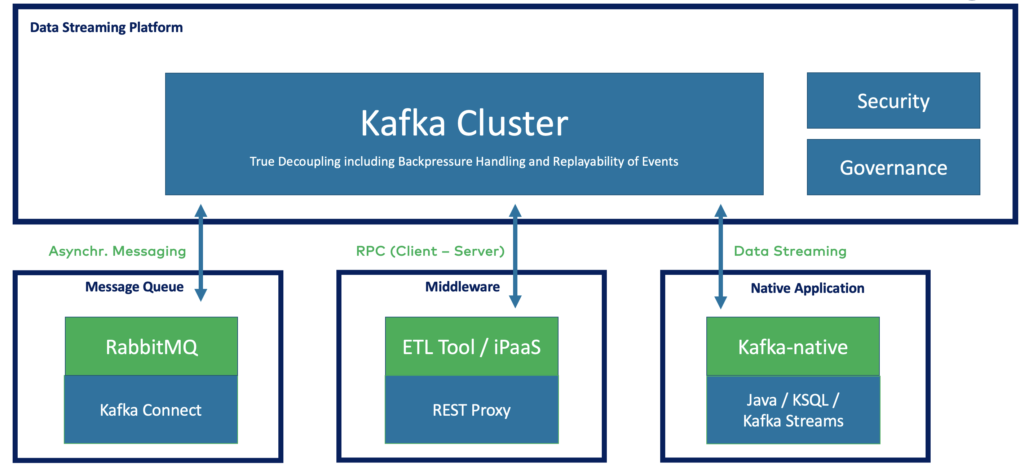
This is why the storage component using the combination of real-time messaging and a distributed commit log enables data consistency across technologies and communication paradigms.
With Tiered Storage for Kafka, storage and compute are separated to enable long-term storage in Kafka for the replayability of historical data. This is not needed for every use case. Kafka does not replace your favorite database. But it is beneficial for some use cases, e.g., model training with TensorFlow and Kafka to leverage machine learning with a Kappa architecture.
Domain-driven design is the foundation of modern microservice architecture or data mesh. For that reason, many cloud-native enterprise architectures are built using Kafka as the heart of the infrastructure for real-time data sharing plus loose coupling between the data products.
Let’s look at a practical real-world example where the added value of Kafka was not its real-time capability but enabling data consistency across systems…
Erste Group Bank: A case study for data consistency with Apache Kafka
Erste Group Bank AG (Erste Group) is an Austrian financial service provider in Central and Eastern Europe serving 15.7 million clients in over 2,700 branches in seven countries. The bank presented its data streaming journey at Confluent’s Data in Motion 2022 tour in Zurich.
Having a strong mission to increase its customer experience, Erste Group is putting more and more data into action. Making this happen can be summarized as a race for consistency across our channels, squaring the circle between latency and data volumes.
The digital transformation at Erste Group required challenging integration across different technologies and communication paradigms. The following sections describe why Apache Kafka was chosen.
Hyper-personalized mobile banking
A great user experience in the new mobile app “Georg” is a crucial strategic component of Erste Group’s digital transformation to increase customer experience and revenue.
Here is how Erste Group promotes its mobile app: “For 8 million people in 6 countries, banking has a name. George. George empowers everyone to understand, manage, and improve their financial health. Simple. Intelligent. Personal. Unique.”
The following diagram shows the positive and negative reviews of customers, including Erste Group’s mobile app “George” and competitive banking apps:
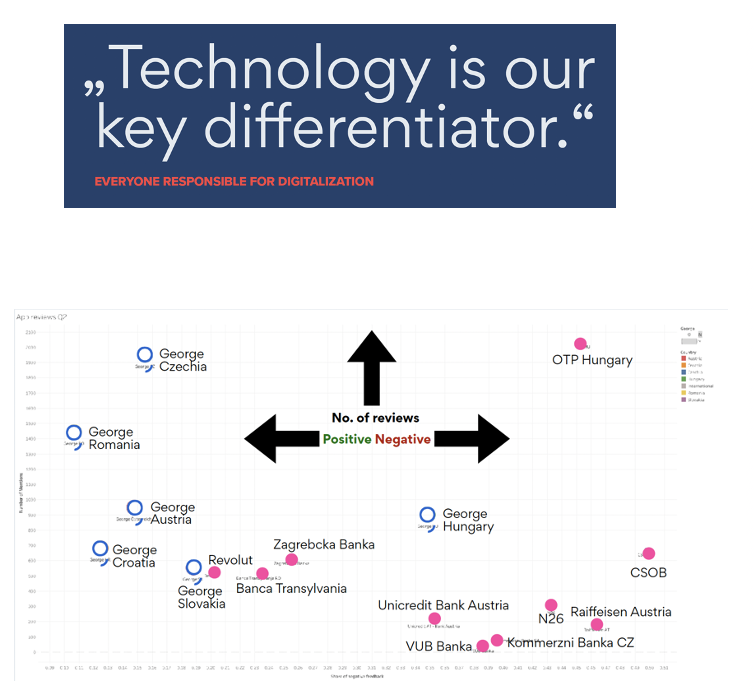
A great mobile app user experience requires the combination of many technologies in the backend. Data streaming enables the foundation in the backend to build an intuitive mobile app across various European countries.
Scalability and accurate information at the right time in the right context make the difference:
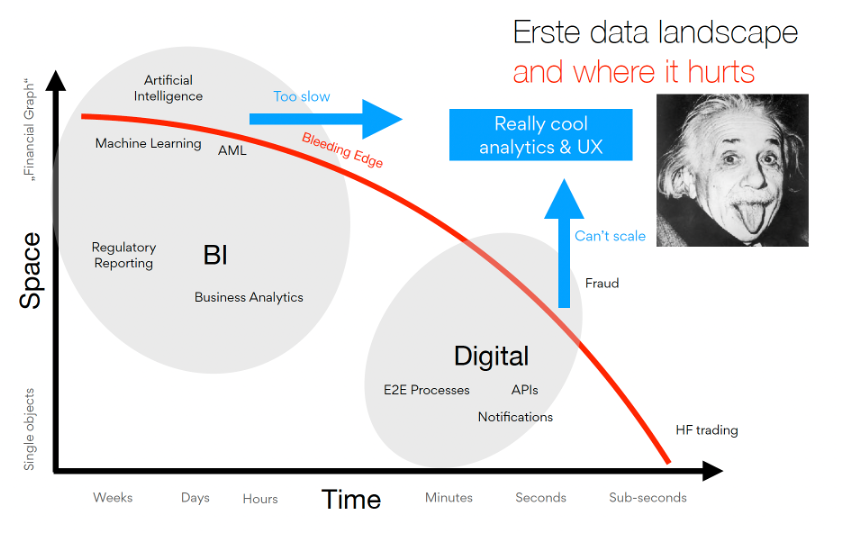
Fully managed data streaming for omnichannel data consistency
Here comes the surprising part of why I chose this case study for the blog post: While the real-time capability of Apache Kafka at any scale is essential, the critical aspect of the technology choice was data consistency across platforms and communication paradigms:

Erste Group built an enterprise architecture with data streaming to enable asynchronous decoupled domains with event sourcing. The responsibility is split across cross-functional teams like Digital and Business Intelligence. However, consistent data is served in different ways for various downstream consumers:
- Stream processing for real-time subscriptions
- A serving layer for API integration via request-response protocols like HTTP/REST
- Tiered Storage for long-term replayability of historical data to enable analytical queries
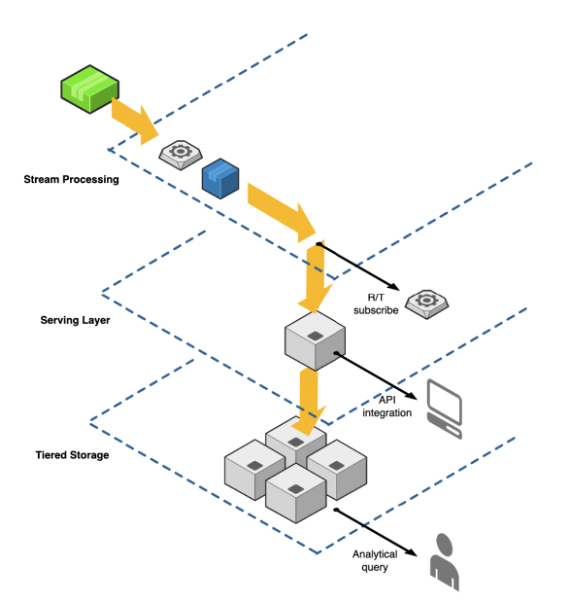
The infrastructure is fully managed in Confluent Cloud to enable focusing on business problems and innovation. DevOps and MLOps automate the development and monitoring lifecycle of the applications.
Data consistency is as critical as real-time data
Apache Kafka is the de facto standard for real-time data streaming. In addition, most enterprise architectures leverage the append-only commit log for loosely coupling to enable agile and elastic microservice architectures. The vision of building data products in a decentralized data mesh is made possible with Apache Kafka.
This post showed the case study of Erste Group to enable data consistency across domains and technologies with fully managed Kafka in the cloud. Obviously, we just explored the foundation. Data sharing across organizations and enforced data governance, including access control, encryption, and audit logging, are mandatory to realize a data mesh in the real world. I discussed these topics in my overview of the top 5 trends for data streaming in 2023.
Let’s connect on LinkedIn and discuss it! Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter.