Apache Kafka for Data Consistency (and Real-Time Data Streaming)
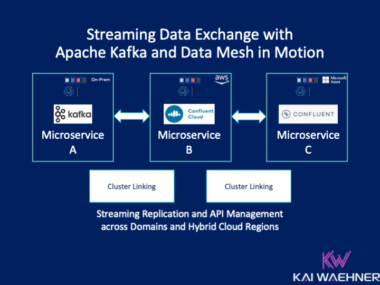
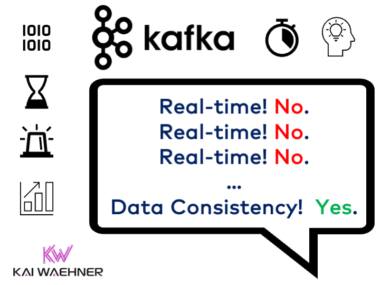
Real-time data beats slow data in almost all use cases. But as essential is data consistency across all systems, including non-real-time legacy systems and modern request-response APIs. Apache Kafka’s most underestimated feature is the storage component based on the append-only commit log. It enables loose coupling for domain-driven design with microservices and independent data products in a data mesh. This blog post explores how Kafka enables data consistency with a real-world case study from financial services.