
Data Streaming is one of the most relevant buzzwords in tech to build scalable real-time applications in the cloud and innovative business models. Do you wonder about my predicted TOP 5 data streaming trends in 2023 to set data in motion? Check out the following presentation and learn what role Apache Kafka plays. Learn about decentralized Data Mesh, cloud-native lakehouse, data sharing, improved user experience, and advanced data governance.
Some followers might notice that this became a series with past posts about the top 5 data streaming trends for 2021 and the top 5 for 2022. Data streaming with Apache Kafka is a journey and evolution to set data in motion. Trends change over time, but the core value of a scalable real-time infrastructure as the central data hub stays.

Gartner Top Strategic Technology Trends for 2023
The research and consulting company Gartner defines the top strategic technology trends every year. This time, the trends are more focused on particular niche concepts. On a higher level, it is all about optimizing, scaling, and pioneering. Here is what Gartner expects for 2023:

It is funny (but not surprising): Gartner’s predictions overlap and complement the five trends I focus on for data streaming with Apache Kafka looking forward to 2023. I explore how data streaming enables better time to market with decentralized optimized architectures, cloud-native infrastructure for elastic scale, and pioneering innovative use cases to build valuable data products.
Hence, here you go with the top 5 trends in data streaming for 2023.
The top 5 data streaming trends for 2023
I see the following topics coming up more regularly in conversations with customers, prospects, and the broader Kafka community across the globe:
- Cloud-native lakehouses
- Decentralized data mesh
- Data sharing in real-time
- Improved developer and user experience
- Advanced data governance and policy enforcement
The following sections describe each trend in more detail. The end of the article contains the complete slide deck. The trends are relevant for various scenarios. No matter if you use open source Apache Kafka, a commercial platform, or a fully-managed cloud service like Confluent Cloud.
Kafka as data fabric for cloud-native lakehouses
Many data platform vendors pitch the lakehouse vision today. That’s the same story as the data lake in the Hadoop era with few new nuances. Put all your data into a single data store to save the world and solve every problem and use case:

In the last ten years, most enterprises realized this strategy did not work. The data lake is great for reporting and batch analytics, but not the right choice for every problem. Besides technical challenges, new challenges emerged: data governance, compliance issues, data privacy, and so on.
Applying a best-of-breed enterprise architecture for real-time and batch data analytics using the right tool for each job is a much more successful, flexible, and future-ready approach:
Data platforms like Databricks, Snowflake, Elastic, MongoDB, BigQuery, etc., have their sweet spots and trade-offs.
Data streaming increasingly becomes the real-time data fabric between all the different data platforms and other business applications leveraging the real-time Kappa architecture instead of the much more batch-focused Lamba architecture.
Decentralized data mesh with valuable data products
Focusing on business value by building data products in independent domains with various technologies is key to success in today’s agile world with ever-changing requirements and challenges. Data mesh came to the rescue and emerged as a next-generation design pattern, succeeding service-oriented architectures and microservices.
Two main proposals exist by vendors for building a data mesh: Data integration with data streaming enables fully decentralized business products. On the other side, data virtualization provides centralized queries:
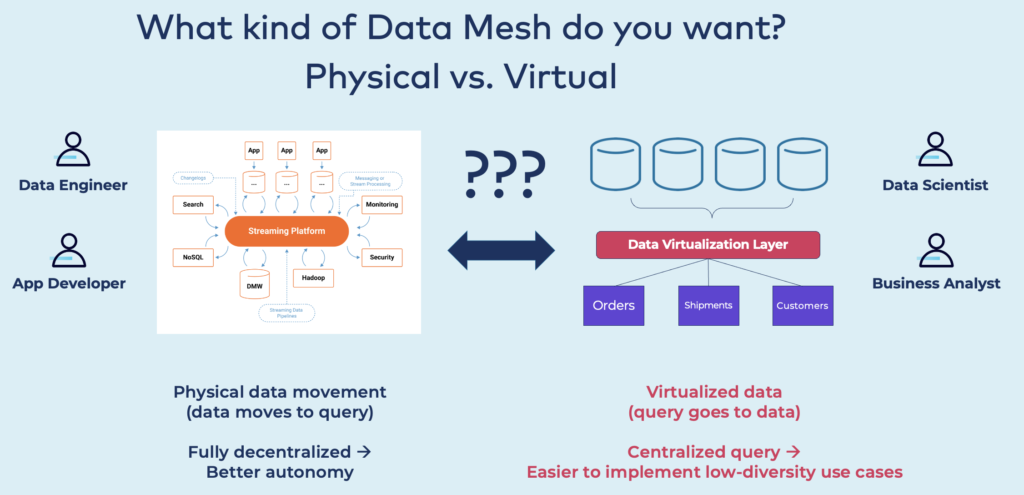
Centralized queries are simple but do not provide a clean architecture and decoupled domains and applications. It might work well to solve a single problem in a project. However, I highly recommend building a decentralized data mesh with data streaming to decouple the applications, especially for strategic enterprise architectures.
Collaboration within and across organizations in real-time
Collaborating within and outside the organization with data sharing using Open APIs, streaming data exchange, and cluster linking enable many innovative business models:
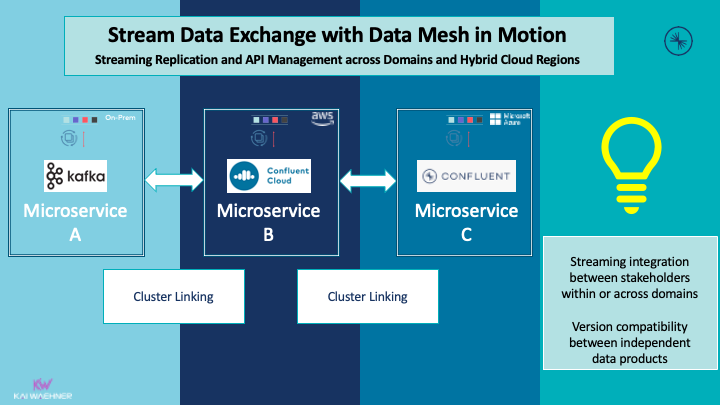
The difference between data streaming to a database, data warehouse, or data lake is crucial: All these platforms enable data sharing at rest. The data is stored on a disk before it is replicated and shared within the organization or with partners. This is not real-time. You cannot connect a real-time consumer to data at rest.
However, real-time data beats slow data. Hence, sharing data in real-time with data streaming platforms like Apache Kafka or Confluent Cloud enables accurate data as soon as a change happens. A consumer can be real-time, near real-time, or batch. A streaming data exchange puts data in motion within the organization or for B2B data sharing and Open API business models.
AsyncAPI spec for Apache Kafka API schemas
AsyncAPI allows developers to define the interfaces of asynchronous APIs. It is protocol agnostic. Features include:
- Specification of OpenAPI contracts (= schemas in the data streaming world)
- Documentation of APIs
- Code generation for many programming languages
- Data governance
- And much more…
Confluent Cloud recently added a feature for generating an AsyncAPI specification for Apache Kafka clusters.
We don’t know yet where the market is going. Will AsynchAPI become the standard for OpenAPI in data streaming? Maybe. I see increasing demand for this specification by customers. Let’s review the status of AsynchAPI in a few quarters or years. But it has the potential.
Improved developer experience with low-code / no-code tools for Apache Kafka
Many analysts and vendors pitch low code/no code tools. Visual coding is nothing new. Very sophisticated, powerful, and easy-to-use solutions exist as IDE or cloud applications. The significant benefit is time-to-market for developing applications and easier maintenance. At least in theory.
These tools support various personas like developers, citizen integrators, and data scientists. At least in theory.
The reality is that:
- Code is king
- Development is about evolution
- Open platforms win
Low code/no code is great for some scenarios and personas. But it is just one option of many. Let’s look at a few alternatives for building Kafka-native applications:
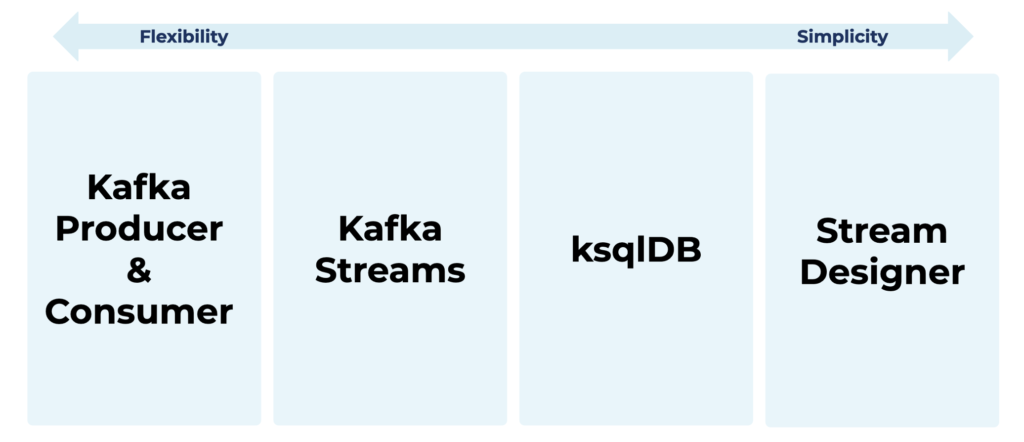
These Kafka-native technologies have their trade-offs. For instance, the Confluent Stream Designer is perfect for building streaming ETL pipelines between various data sources and sinks. Just click the pipeline and transformations together. Then deploy the data pipeline into a scalable, reliable, and fully-managed streaming application. The difference to separate tools like Apache Nifi is that the generated code run in the same streaming platform, i.e., one infrastructure end-to-end. This makes ensuring SLAs and latency requirements much more manageable and the whole data pipeline more cost-efficient.
However, the simpler a tool is, the less flexible it is. It is that easy. No matter which product or vendor you look at. This is not just true for Kafka-native tools.
And you are flexible with your tool choice per project or business problem. Add your favorite non-Kafka stream processing engine to the stack, for instance, Apache Flink. Or use a separate iPaaS middleware like Dell Boomi or SnapLogic.
Domain-driven design with dumb pipes and smart endpoints
The real benefit of data streaming is the freedom of choice for your favorite Kafka-native technology, open-source stream processing framework, or cloud-native iPaaS middleware.
Choose the proper library, tool, or SaaS for your project. Data streaming enables a decoupled domain-driven design with dumb pipes and smart endpoints:
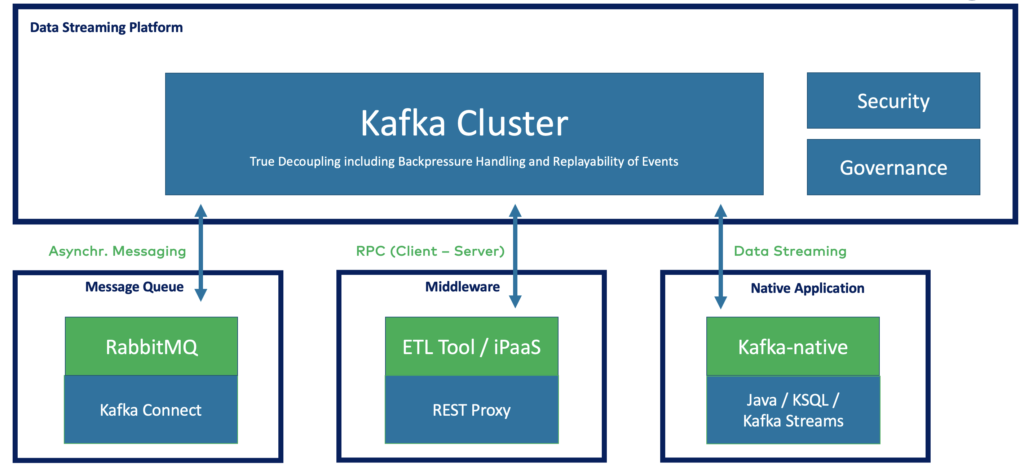
Data streaming with Apache Kafka is perfect for domain-driven design (DDD). On the contrary, often used point-to-point microservice architecture HTTP/REST web service or push-based message brokers like RabbitMQ create much stronger dependencies between applications.
Data governance across the data streaming pipeline
An enterprise architecture powered by data streaming enables easy access to data in real-time. Many enterprises leverage Apache Kafka as the central nervous system between all data sources and sinks.
The consequence of being able to access all data easily across business domains is two conflicting pressures on organizations: Unlock the data to enable innovation versus Lock up the data to keep it safe.
Achieving data governance across the end-to-end data streams with data lineage, event tracing, policy enforcement, and time travel to analyze historical events is critical for strategic data streaming in the enterprise architecture. Data governance on top of the streaming platform is required for end-to-end visibility, compliance, and security:
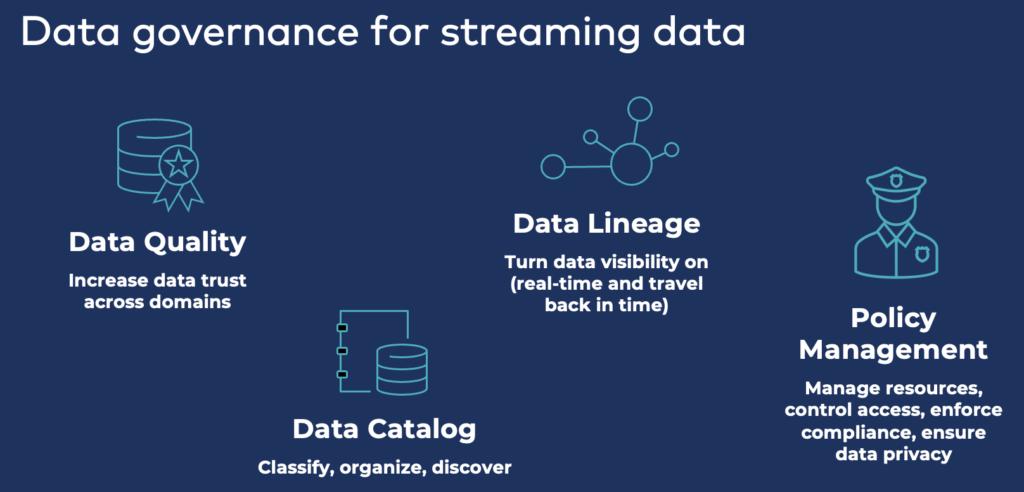
Policy enforcement with schemas and API contracts
The foundation for data governance is the management of API contracts (so-called schemas in data streaming platforms like Apache Kafka). Solutions like Confluent enforce schemas along the data pipeline, including data producer, server, and consumer:
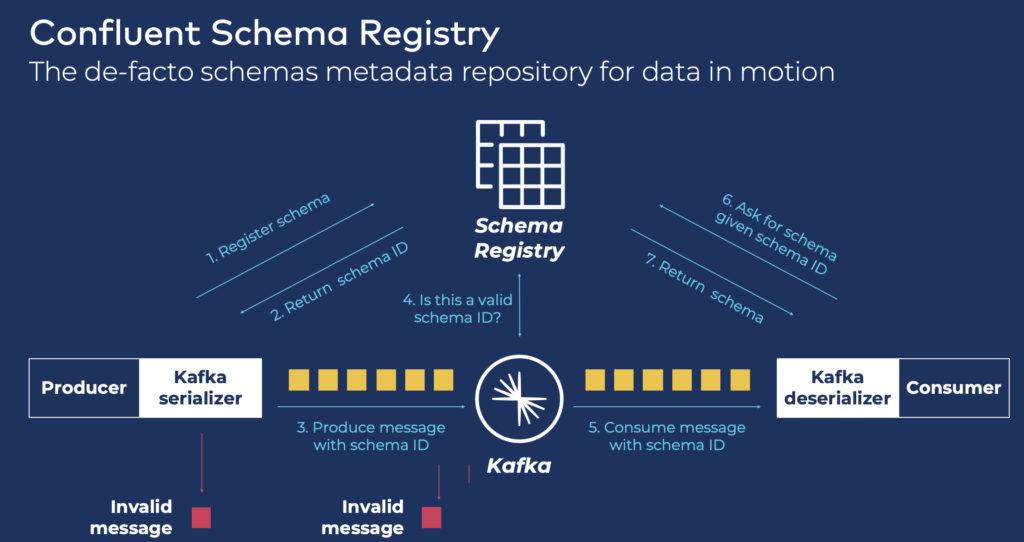
Additional data governance tools like data lineage, catalog, or police enforcement are built on this foundation. The recommendation for any serious data streaming project is to use schema from the beginning. It is unnecessary for the first pipeline. But the following producers and consumers need a trusted environment with enforced policies to establish a decentralized data mesh architecture with independent but connected data products.
Slides and Video for Data Streaming Use Cases in 2023
Here is the slide deck from my presentation:
Fullscreen ModeAnd here is the free on-demand video recording:

Data streaming goes up in the maturity curve in 2023
It is still an early stage for data streaming in most enterprises. But the discussion goes beyond questions like “when to use Kafka?” or “which cloud service to use?”… In 2023, most enterprises look at more sophisticated challenges around their numerous data streaming projects.
The new trends are often related to each other. A data mesh enables the building of independent data products that focus on business value. Data sharing is a fundamental requirement for a data mesh. New personas access the data stream. Often, citizen developers or data scientists need easy tools to pioneer new projects. The enterprise architecture requires and enforces data governance across the pipeline for security, compliance, and privacy reasons.
Scalability and elasticity need to be there out of the box. Fully-managed data streaming is a brilliant opportunity for getting started in 2023 and moving up in the maturity curve from single projects to a central nervous system of real-time data.
What are your most relevant and exciting trends for data streaming and Apache Kafka in 2023 to set data in motion? What are your strategy and timeline? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
