Databricks and Confluent in the World of Enterprise Software (with SAP as Example)
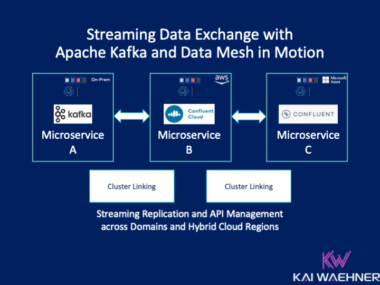
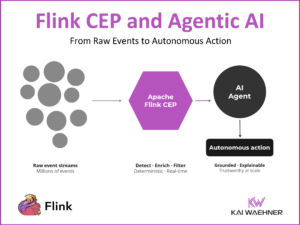
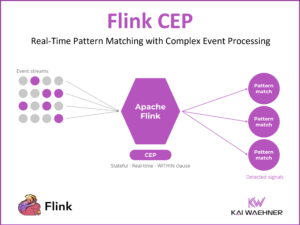
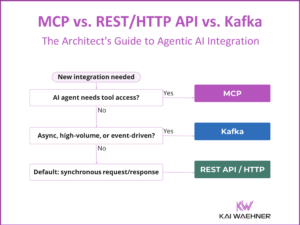
Enterprise data lives in complex ecosystems—SAP, Oracle, Salesforce, ServiceNow, IBM Mainframes, and more. This article explores how Confluent and Databricks integrate with SAP to bridge operational and analytical workloads in real time. It outlines architectural patterns, trade-offs, and use cases like supply chain optimization, predictive maintenance, and financial reporting, showing how modern data streaming unlocks agility, reuse, and AI-readiness across even the most SAP-centric environments.