
Data engineers managing batch SQL pipelines on Snowflake, BigQuery – and increasingly Databricks – and streaming pipelines on Apache Flink face a familiar problem: two toolchains, two skill sets, two CI/CD pipelines. dbt is now extending into stream processing. This post explains what that means in practice, why it matters for data engineering teams, and what a concrete implementation looks like with Apache Flink on Confluent Cloud.
Stay informed about the latest thinking on data integration, process intelligence, and trusted agentic AI by subscribing to my newsletter and following me on LinkedIn or X. And download my free book, The Ultimate Data Streaming Guide, a practical resource covering data streaming use cases, architectures, and real-world industry case studies.
Data Streaming Meets the Lakehouse
Data lakes promised to solve the enterprise data problem. The reality has been messier. Batch pipelines produce stale information, and analytical workloads run hours after the business event occurred. By the time a query runs, the window for action is often already closed.
The lakehouse pattern improved matters. Apache Iceberg has become the dominant open table format, supported across Snowflake, Databricks, BigQuery, and a growing number of query engines. Teams can run SQL analytics directly on data in object storage without duplicating it into a proprietary warehouse.
But the lakehouse alone does not solve the real-time problem. Data still arrives as a batch, minutes or hours after the source event. That gap reflects a deeper architectural split. Data streaming with Apache Kafka and Flink is the operational layer: it handles critical SLAs, powers event-driven applications, and keeps business systems running in real time. The lakehouse is the analytical layer: it stores historical data for reporting, ML, and near real-time or batch analytics. These are two distinct workloads with different requirements regarding uptime, data loss, latency, and throughput. They need to coexist without forcing engineers to build and maintain two separate pipelines.
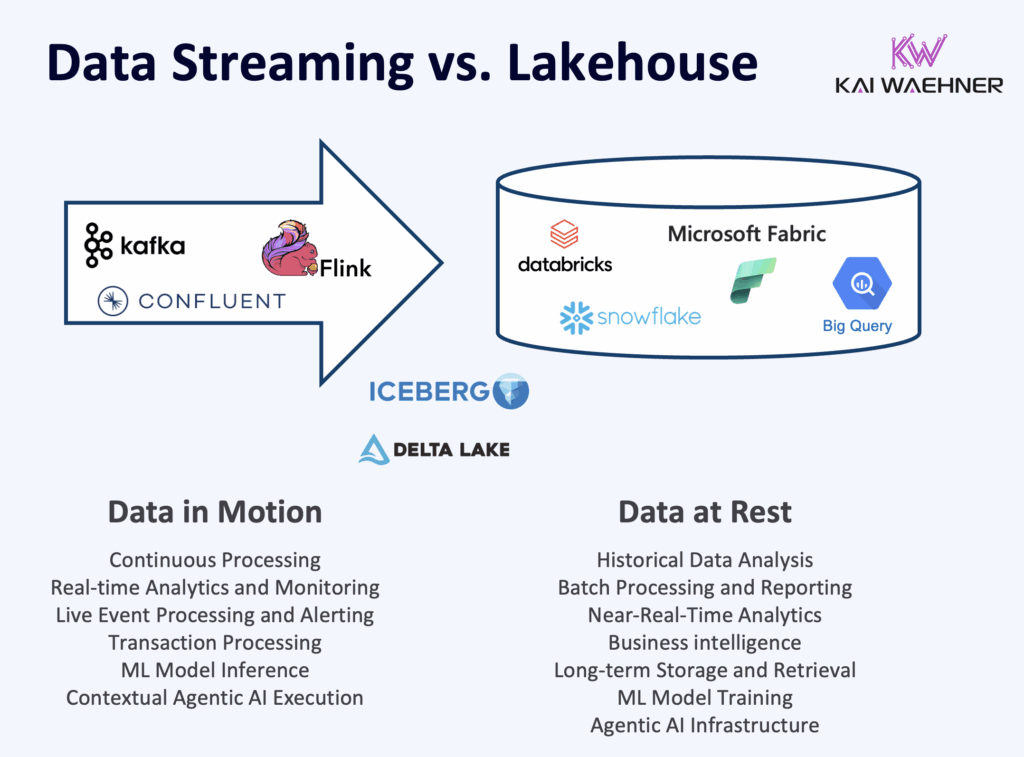
How Kafka, Flink, and Iceberg Work Together
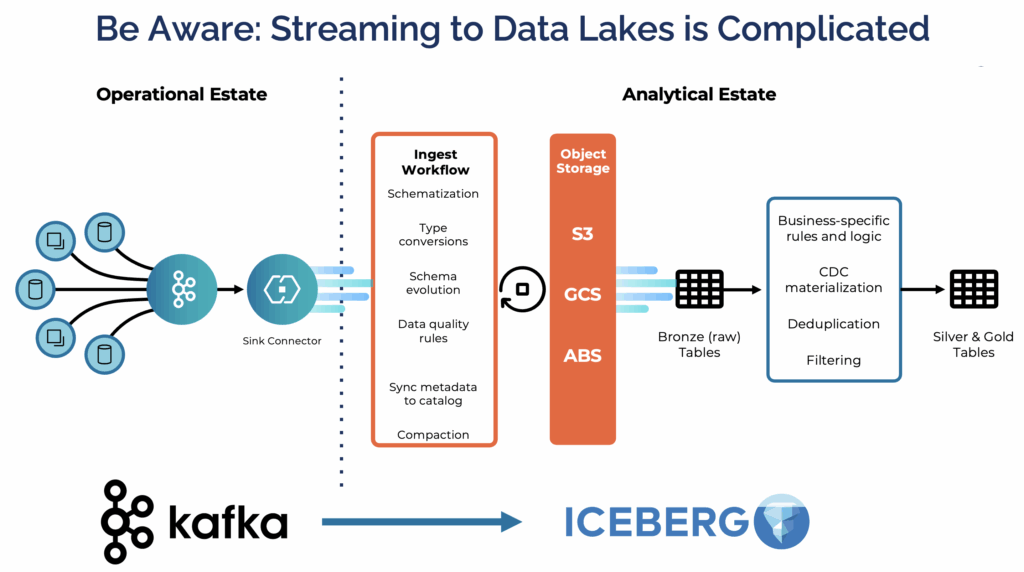
That is what the combination of Apache Kafka, Apache Flink, and Apache Iceberg addresses. Kafka captures every event at the source and serves as the operational backbone for real-time systems. Flink processes and enriches data in motion, supporting both immediate operational decisions and the preparation of data for downstream analytics. Iceberg stores the result as a governed, queryable table for any analytical engine, whether that is Snowflake, BigQuery, or Databricks.
A full treatment of this architecture, including schema evolution, compaction, and catalog integration, is covered here: Data Streaming Meets Lakehouse: Apache Iceberg for Unified Real-Time and Batch Analytics.
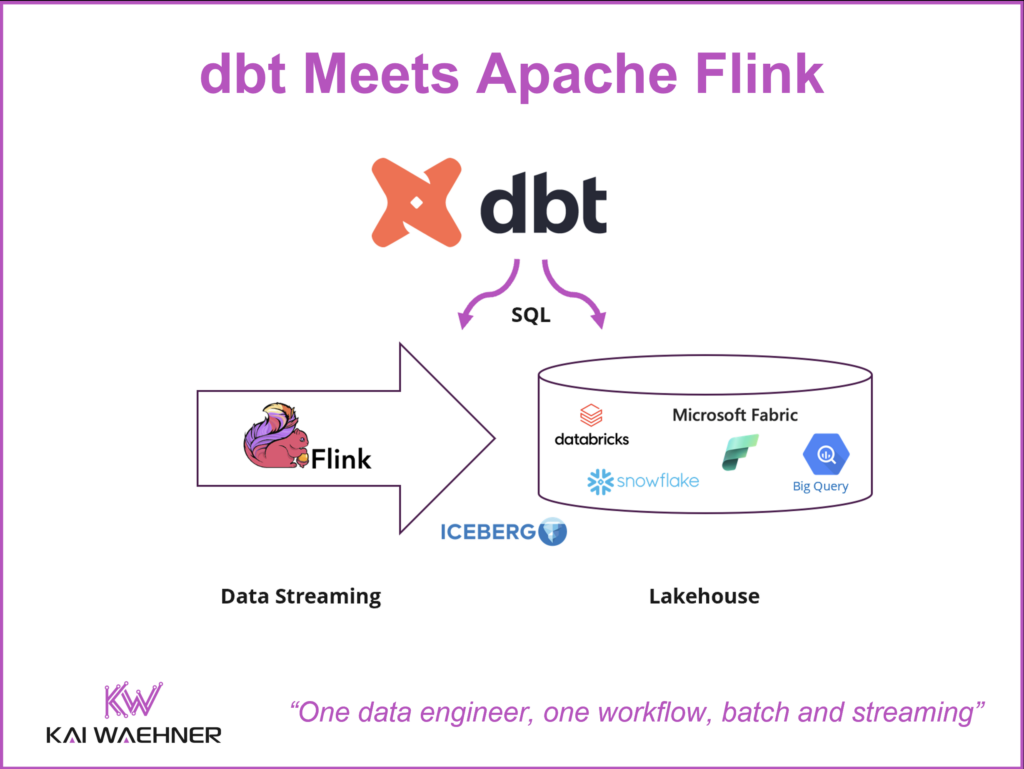
The question is no longer whether streaming and lakehouse architectures can coexist. They already do. The question is how data engineering teams can work across both without maintaining separate toolchains. That is where dbt enters the picture.
What Is dbt?
dbt, the data build tool, is an open-source framework for SQL-based data transformation. A dbt model is a SQL SELECT statement saved as a file. dbt infers execution order from how models reference each other using ref(). The standard commands cover the full engineering workflow: dbt run executes the SQL against the target platform, dbt test validates data quality, and dbt docs generate produces a browsable documentation catalog.
What made dbt successful is the discipline it brings to SQL work. Before dbt, transformation logic lived in scattered scripts and proprietary ETL tools. dbt replaced that with a code-first, version-controlled workflow with full lineage, testing, and documentation built in.
Snowflake and BigQuery are where most dbt adoption lives today. Both are SQL-native and optimized for the ELT pattern dbt was built around. Redshift is a strong third platform in AWS environments. Databricks has seen growing dbt adoption more recently, driven by investments in serverless SQL Warehousing, but its roots are in Spark and Python, making it a newer entrant in the dbt ecosystem.
dbt Labs crossed $100 million in ARR in early 2025, with over 5,000 paying customers. Around 90,000 dbt projects are running in production today. The Fivetran and dbt Labs merger, announced in October 2025, created a combined data infrastructure company with nearly $600 million in annual revenue — a clear signal that dbt has moved well beyond a popular open-source tool and into foundational enterprise data infrastructure.
dbt Meets Apache Flink: One Workflow for Data Engineers
Data engineering teams managing both batch and streaming today operate in two separate realities. Snowflake or BigQuery on one side: dbt models, version-controlled SQL, automated tests, generated docs. Apache Flink on the other: Terraform scripts, custom deployment code, or the Flink console. Skills and practices do not transfer between the two. That separation has a real cost. Streaming pipelines are harder to test, harder to document, and harder to hand over. Many teams compensate by keeping streaming logic minimal and pushing transformation work downstream into the warehouse, which reintroduces latency and undermines the point of streaming.
The vision is straightforward: one SQL workflow for both. The engineer who builds dbt models on Snowflake or BigQuery should be able to apply the same approach to an Apache Flink streaming pipeline, without switching tools or rebuilding CI/CD from scratch. Two toolchains means two testing strategies, two documentation systems, and two skill sets to hire and retain. Governance enforcement becomes inconsistent across the two environments.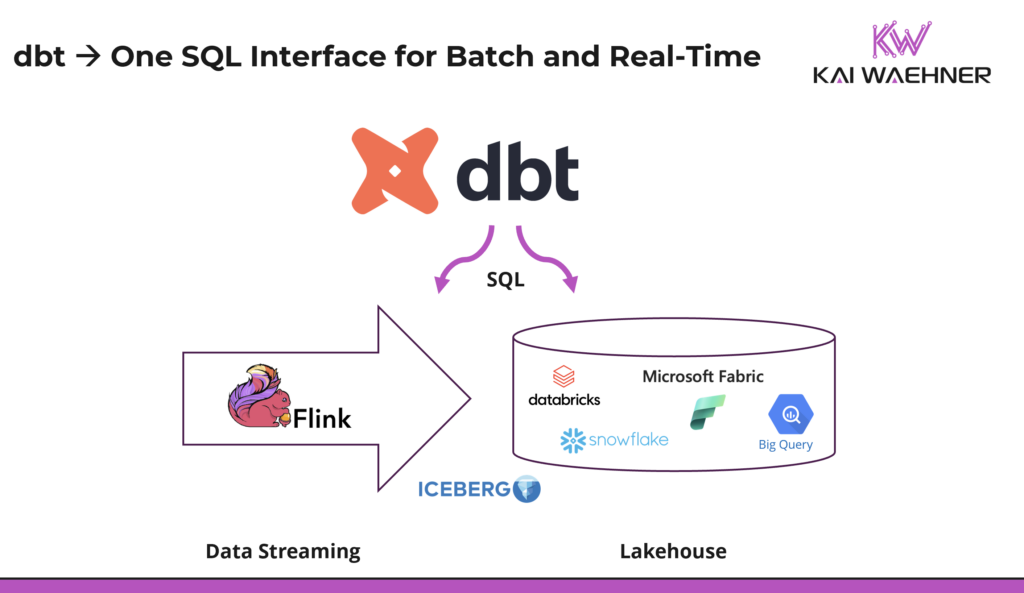
SQL is the shared foundation that makes this realistic. Flink SQL is mature and production-proven. Snowflake and BigQuery are SQL-native. Apache Iceberg tables are queryable via SQL across multiple engines. dbt wraps SQL with engineering discipline. The model files look the same. The ref() dependency resolution works the same way. Tests and documentation generation work through the same commands. Organizations do not need to hire separate Flink infrastructure specialists. The existing data engineering team can own both sides.
Apache Iceberg connects the two worlds at the storage layer. A Flink pipeline writes structured, governed events into an Iceberg table in the organization’s own S3 bucket. That same table is immediately readable by Snowflake, BigQuery, or Databricks without any additional ETL step. dbt can model data across the full pipeline: shaping it as it streams through Flink, and transforming it again when it lands in the warehouse for analytics.
This is also a direct enabler of the Shift Left Architecture 2.0. The Shift Left approach moves data integration logic closer to the source, applying quality checks, enrichment, and governance in the streaming layer before data lands in the lakehouse. Until now, that required streaming-specific skills most dbt-native teams did not have. dbt for Flink lowers that barrier considerably.
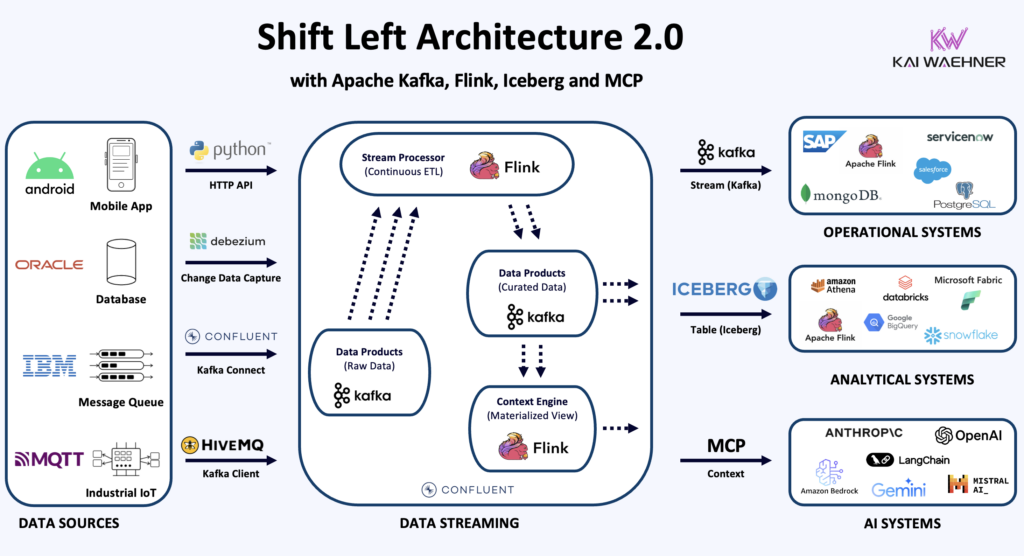
The full architectural detail is covered here: The Shift Left Architecture 2.0: Operational, Analytical and AI Interfaces for Real-Time Data Products.
Concrete Example: dbt on Confluent Cloud with Apache Flink
The most concrete implementation available today is the dbt-confluent adapter, released by Confluent alongside the confluent-sql Python driver. Both are open source and available on PyPI and GitHub.
Data engineers define streaming pipelines as dbt models and deploy them to Flink compute pools using the standard dbt run command.
Getting started is a single step:
pip install dbt-confluent
Three materializations are supported: view for a virtual Flink SQL view over a Kafka topic, streaming_table for a continuous always-current result set, and streaming_source for defining a Kafka topic as a dbt source. Testing is deterministic, using Confluent Cloud’s snapshot query capability to return bounded point-in-time results rather than silently passing on timeout. Documentation generation works through INFORMATION_SCHEMA integration, producing the same browsable catalog that Snowflake and BigQuery projects generate.
The underlying confluent-sql driver is DB-API v2 compliant, meaning any compatible tool can connect directly to Confluent Cloud Flink: Airflow and Dagster for orchestration, Pandas for snapshot queries, Streamlit for live dashboards, and LangChain for AI agent workflows.
For data engineers already working in dbt, this means the skills and practices built around Snowflake or BigQuery transfer directly to the streaming side of the architecture.
The Data Engineer Owns Batch and Streaming with dbt
The separation between batch and streaming engineering has always been more organizational than technical. Both worlds use SQL. Both require testing, documentation, and reliable deployment. The tools just never bridged the gap, so organizations staffed and operated two distinct engineering disciplines.
dbt extending to Apache Flink changes that equation. The data engineer who runs dbt on Snowflake or BigQuery today can apply the same mental model, the same commands, and the same CI/CD pipeline to Flink streaming pipelines. No Flink infrastructure specialization required. They write SQL models, define tests, generate documentation, and deploy, exactly as they do for batch.
The implication is straightforward. The investment in dbt skills and tooling now extends further into the architecture. Streaming can be adopted incrementally by the same data engineering teams already trusted for batch. One team, one tool, one governance standard, across both operational and analytical workloads.
The Flink adapter for dbt is earlier in maturity compared to dbt on Snowflake or BigQuery, and teams should expect to work with an evolving ecosystem. But the foundation is solid, the direction is clear, and the core architectural components are already running in production at scale across multiple industries. The demand from data engineering teams is real and growing.
Stay informed about the latest thinking on data integration, process intelligence, and trusted agentic AI by subscribing to my newsletter and following me on LinkedIn or X. And download my free book, The Ultimate Data Streaming Guide, a practical resource covering data streaming use cases, architectures, and real-world industry case studies.
