
Most financial service institutions operate their core banking platform on legacy mainframe technologies. The monolithic, proprietary, inflexible architecture creates many challenges for innovation and cost-efficiency. This blog post explores an open, elastic, and scalable solution powered by Apache Kafka can look like to solve these problems. Three cloud-native real-world banking solutions show how transactional and analytical workloads can be built at any scale in real-time for traditional business processes like payments or regulatory reporting and innovative new applications like crypto trading.

What is core banking?
Core banking is a banking service provided by networked bank branches. Customers may access their bank accounts and perform basic transactions from member branch offices or connected software applications like mobile apps. Core banking is often associated with retail banking, and many banks treat retail customers as their core banking customers. Wholesale banking is a business conducted between banks. Securities trading involves the buying and selling of stocks, shares, and so on.
Businesses are usually managed via the corporate banking division of the institution. Core banking covers the basic depositing and lending of money. Standard core banking functions include transaction accounts, loans, mortgages, and payments.
Typical business processes of the banking operating system include KYC (“Know Your Customer”), product opening, credit scoring, fraud, refunds, collections, etc.
Banks make these services available across multiple channels like automated teller machines, Internet banking, mobile banking, and branches. Banking software and network technology allow a bank to centralize its record-keeping and allow access from any location.
Automatic analytics for regulatory reporting, flexible configuration to adjust workflows and innovate, and an open API to integrate with 3rd party ecosystems are crucial for modern banking platforms.
Transactional vs. analytical workloads in core banking
Workloads for analytics and transactions have very unlike characteristics and requirements. The use cases differ significantly. Most core banking workflows are transactional.
SLAs are very different and are crucial to understanding to guarantee the proper behavior in case of infrastructure issues and for disaster recovery:
- RPO (Recovery Point Objective): The actual data loss you can live within the case of a disaster
- RTO (Recovery Time Objective): The actual recovery period (i.e., downtime) you can live within the case of a disaster
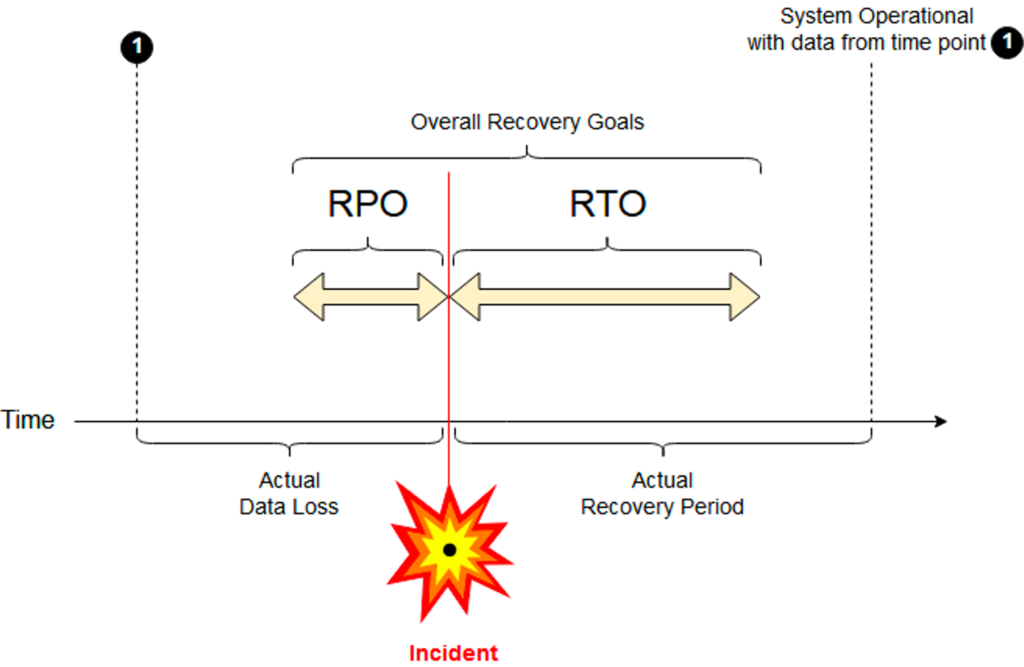
While downtime or data loss are not good in analytics use cases, they are often acceptable when the cost and risk are compared for guaranteeing an RTO and RPO close to zero. Hence, if the reporting function for end-users is down for an hour or even worse a few reports are lost, then life goes on.
In transactional workloads within a core banking platform, RTO and RPO need to be as close to zero as possible, even in the case of a disaster (e.g., if a complete data center or cloud region is down). If the core banking platform loses payment transactions or other events required for compliance processing, then the bank is in huge trouble.
Legacy core banking platforms
Advancements in the Internet and information technology reduced manual work in banks and increased efficiency. Computer software was developed decades ago to perform core banking operations like recording transactions, passbook maintenance, interest calculations on loans and deposits, customer records, the balance of payments, and withdrawal.
Banking software running on a mainframe
Most core banking platforms of traditional financial services companies still run on mainframes. The machines, operating systems, and applications still do a great job. SLAs like RPO and RTO are not new. If you look at IBM’s mainframe products and docs, the core concepts are similar to cutting-edge cloud-native technologies. Downtime, data loss, and similar requirements need to be defined.
The solving architecture provided the needed guarantees. IBM DB2, IMS, CICS, and Cobol code still operate transactional workloads very stable. A modern IBM z15 mainframe, announced in 2019, provides up to 40TB RAM and 190 Core. That’s very impressive.
Monolithic, proprietary, inflexible mainframe applications
So, what’s the problem with legacy core banking platforms running on a mainframe or similar other infrastructure?
- Monolithic: Legacy mainframe applications are extreme monolithic applications. This is not comparable to a monolithic web application from the 2000s running on IBM WebSphere or another J2EE. / Java EE application server. It is much worse.
- Proprietary: IMS, CICS, MQ, DB2, et al. are very mature technologies. However, next-generation decision makers, cloud architects, and developers expect open APIs, open-source core infrastructure, best-of-breed solutions and SaaS with independent freedom of choice for each problem.
- Inflexible: Most legacy core banking applications do their job for decades. The Cobol code runs. However, it is not understood or documented. Cobol developers are scarce, too. The only option is to extend existing applications. Also, the infrastructure is not elastic to scale up and down in a software-defined manner. Instead, companies have to buy hardware for millions of dollars (and still pay an additional fortune for the transactions).
Yes, the mainframe supports up-to-date technologies such as DB2, MQ, WebSphere, Java, Linux, Web Services, Kubernetes, Ansible, Blockchain! Nevertheless, this does not solve the existing problems. This only helps when you build new applications. However, new applications are usually made with modern cloud-native infrastructure and frameworks instead of relying on legacy concepts.
Optimization and cost reduction of existing mainframe applications
The above sections looked at the enterprise architecture with RPO/RTO in mind to guarantee uptime and no data loss. This is crucial for decision-makers responsible for the business unit’s risk and revenue.
However, the third aspect besides revenue and risk is cost. Beyond providing an elastic and flexible infrastructure for the next-generation core banking platform, companies also move away from legacy solutions for cost reasons.
Enterprises save millions of dollars by just offloading data from a mainframe to modern event streaming:
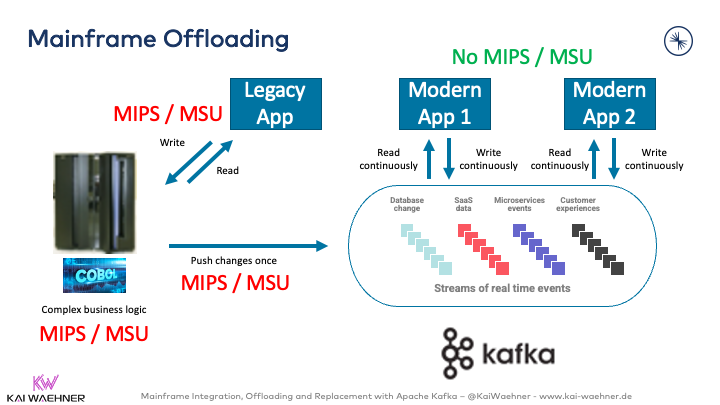
For instance, streaming data empowers the Royal Bank of Canada (RBC) to save millions of dollars by offloading data from the mainframe to Kafka. Here is a quote from RBC:
“… rescue data off of the mainframe, in a cloud-native, microservice-based fashion … [to] … significantly reduce the reads on the mainframe, saving RBC fixed infrastructure costs (OPEX). RBC stayed compliant with bank regulations and business logic, and is now able to create new applications using the same event-based architecture.”
Read my dedicated blog post if you want to learn more about mainframe offloading, integration, and migration to Apache Kafka.
Modern cloud-native core banking platforms
This post is not just about offloading and integration. Instead, we look at real-world examples where cloud-native core banking replaced existing legacy mainframes or enabled new FinTech companies to start in a cutting-edge real-time cloud environment from scratch to compete with the traditional FinServ contenders.
Requirements for a modern banking platform?
Here are the requirements I here regularly on the wish list of executives and lead architects from financial services companies for new banking infrastructure and applications:
- Real-time data processing
- Scalable infrastructure
- High availability
- True decoupling and backpressure handling
- Cost-efficient cost model
- Flexible architecture for agile development
- Elastic scalability
- Standards-based interfaces and open APIs
- Extensible functions and domain-driven separation of concerns
- Secure authentication, authorization, encryption, and audit logging
- Infrastructure-independent deployments across an edge, hybrid, and multi-region / multi-cloud environments
What are cloud-native infrastructure and applications?
And here are the capabilities of a genuinely cloud-native infrastructure to build a next-generation core banking system:
- Real-time data processing
- Scalable infrastructure
- High availability
- True decoupling and backpressure handling
- Cost-efficient cost model
- Flexible architecture for agile development
- Elastic scalability
- Standards-based interfaces and open APIs
- Extensible functions and domain-driven separation of concerns
- Secure authentication, authorization, encryption, and audit logging
- Infrastructure-independent deployments across an edge, hybrid, and multi-region / multi-cloud environments
I think you get my point here: Adopting cloud-native infrastructure is critical for success in building next-generation banking software. No matter if you
- are on-premise or in the cloud
- are a traditional player or a startup
- focus on a specific country or language, or operate across regions or even globally
Apache Kafka = cloud-native infrastructure for real-time transactional workloads
Many people think that Apache Kafka is not built for transactions and should only be used for big data analytics. This blog post explores when and how to use Kafka in resilient, mission-critical architectures and when to use the built-in Transaction API.
Kafka is a distributed, fault-tolerant system that is resilient by nature (if you deploy and operate it correctly). No downtime and no data loss can be guaranteed, like in your favorite database, mainframe, or other core platforms.
Elastic scalability and rolling upgrades allow a flexible and reliable data streaming infrastructure for transactional workloads to guarantee business continuity. The architect can even stretch a cluster across regions with tools such as Confluent Multi-Region Clusters. This setup ensures zero data loss and zero downtime even in case of a disaster where a data center is entirely down.
The post “Global Kafka Deployments” explores the different deployment options and their trade-offs in more detail. Check out my blog post about transactional vs. analytical workloads with Apache Kafka for more information.
Apache Kafka in banking and financial services
The rise of event streaming in financial services is growing like crazy. Continuous real-time data integration and processing are mandatory for many use cases. Many business departments in the financial services sector deploy Apache Kafka for mission-critical transactional workloads and big data analytics, including core banking. High scalability, high reliability, and an elastic open infrastructure are the critical reasons for Kafka’s success.
To learn more about different use cases, architectures, and real-world examples in the FinServ sector check out the post “Apache Kafka in the Financial Services Industry“. Use cases include
- Wealth management and capital markets
- Market and credit risk
- Cybersecurity
- IT Modernization
- Retail and corp banking
- Customer experience
Modern cloud-native core banking solutions powered by Kafka
Now, let’s explore the specific example of cloud-native core banking solutions built with Apache Kafka. The following subsections show three real-world examples.
Thought Machine – Correctness and scale in a single platform
Thought Machine is an innovative and flexible core banking operating system. The core capabilities of Thought Machine’s solution include
- Cloud-native core banking software
- Transactional workloads (24/7, zero data loss)
- Flexible product engine powered by smart contracts (not blockchain)
The cloud-native core banking operating system enables a bank to achieve a wide scale of customization without having to change anything on the underlying platform. This is highly advantageous and a crucial part of how its architecture is a counterweight to the “spaghetti” that arises in other systems when customization and platform functionality are not separated.
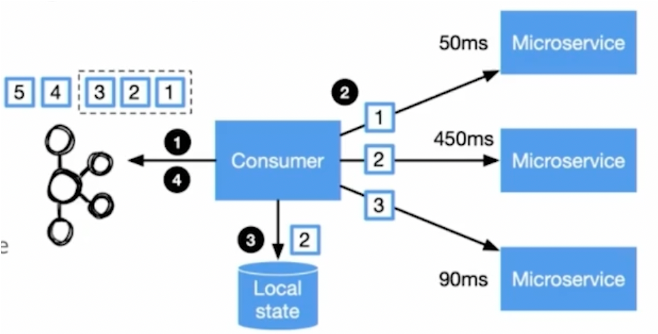
Thought Machine’s Kafka Summit talk from 2021 explores how Thought Machine’s core banking system ‘Vault’ was built in a cloud-first manner with Apache Kafka at its heart. It leverages event streaming to enable asynchronous and parallel processing at scale, specifically focusing on the architectural patterns to ensure ‘correctness’ in such an environment.
10x Banking – Channel agnostic transactions in real-time
10X Banking provides a cloud-native core banking platform. In their Kafka Summit talk, they talked about the history of core banking and how they leverage Apache Kafka in conjunction with other open-source technologies within their commercial platform.
Kafka is a data hub within the comprehensive platform for real-time analytics, transactions, and cybersecurity. Apache Kafka is not the silver bullet for every problem. Hence, 10x chose a best-of-breed approach to combine different open-source frameworks, commercial products, and SaaS offerings to build the cloud-native banking framework.
Here is how 10X Banking built a cloud-native core banking platform to enable real-time and batch analytics with a single data streaming pipeline leveraging the Kappa architecture:
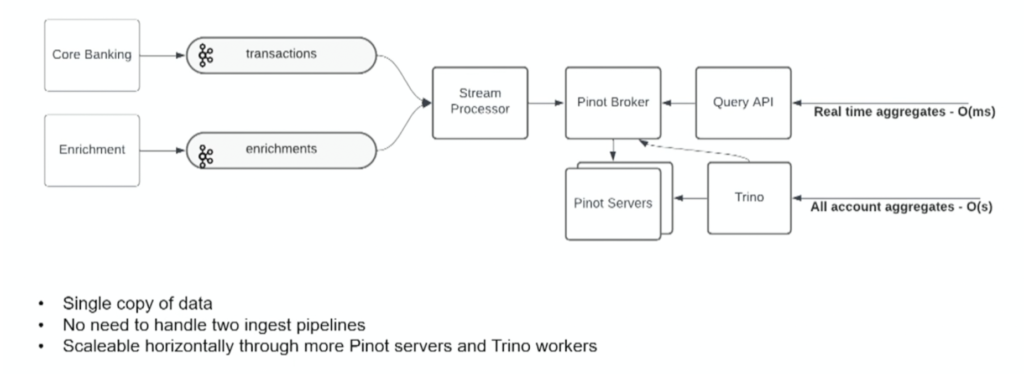
The key components include Apache Kafka for data streaming, plus Apache Pinot and Trino for analytics.
Custodigit – Secure crypto investments with stateful data streaming and orchestration
Custodigit is a modern banking platform for digital assets and cryptocurrencies. It provides crucial features and guarantees for seriously regulated crypto investments:
- Secure storage of wallets
- Sending and receiving on the blockchain
- Trading via brokers and exchanges
- Regulated environment (a key aspect and no surprise as this product is coming from the Swiss – a very regulated market)
Kafka is the central core banking nervous system of Custodigit’s microservice architecture. Stateful Kafka Streams applications provide workflow orchestration with the “distributed saga” design pattern for the choreography between microservices. Kafka Streams was selected because of:
- lean, decoupled microservices
- metadata management in Kafka
- unified data structure across microservices
- transaction API (aka exactly-once semantics)
- scalability and reliability
- real-time processing at scale
- a higher-level domain-specific language for stream processing
- long-running stateful processes
I covered Custodigit and other blockchains/crypto platforms in a separate blog post: Apache Kafka as Data Hub for Crypto, DeFi, NFT, Metaverse – Beyond the Buzz.
Cloud-native core banking provides elastic scale for transactional workloads
Modern core banking software needs to be elastic, scalable, and real-time. This is true for transactional workloads like KYC or credit scoring and analytical workloads, like regulatory reporting. Apache Kafka enables processing transactional and analytical workloads in many modern banking solutions.
Thought Machine, 10X Banking, and Custodigit are three cloud-native examples powered by the Apache Kafka ecosystem to enable the next generation of banking software in real-time. Open Banking is achieved with open APIs to integrate with other 3rd party services.
The integration, offloading, and later replacement of legacy technologies such as mainframe with modern data streaming technologies prove the business value in many organizations. Kafka is not a silver bullet, but the central and mission-critical data hub for real-time data integration and processing.
How do you leverage data streaming for analytical or transactional workloads? What architecture does your platform use? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
