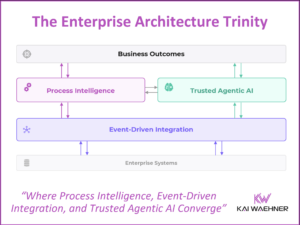
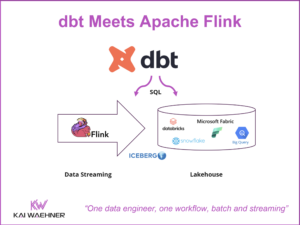
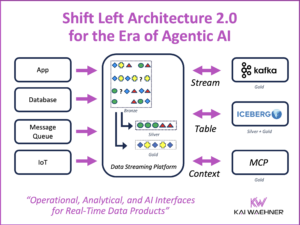
Modern enterprise architectures are evolving. Traditional batch data pipelines and centralized processing models are being replaced by more flexible, real-time systems. One of the driving concepts behind this change is the Shift Left approach. This blog compares Databricks’ Medallion Architecture with a Shift Left Architecture popularized by Confluent. It explains where each concept fits best—and how they can work together to create a more complete, flexible, and scalable architecture.

About the Confluent and Databricks Blog Series
This article is part of a blog series exploring the growing roles of Confluent and Databricks in modern data and AI architectures:
- Blog 1: The Past, Present and Future of Confluent (The Kafka Company) and Databricks (The Spark Company)
- Blog 2: Confluent Data Streaming Platform vs. Databricks Data Intelligence Platform for Data Integration and Processing
- Blog 3 (THIS ARTICLE): Shift-Left Architecture for AI and Data Warehousing with Confluent and Databricks
- Blog 4: Databricks and Confluent in Enterprise Software Environments (with SAP as Example)
- Blog 5: Databricks and Confluent Leading Data and AI Architectures – and How They Compare to Competitors
Learn how these platforms will affect data use in businesses in future articles. Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And download my free book about data streaming use cases, including more details about the shift left architecture with data streaming and lakehouses.
Medallion Architecture: Structured, Proven, but Not Always Optimal
The Medallion Architecture, popularized by Databricks, is a well-known design pattern for organizing and processing data within a lakehouse. It provides structure, modularity, and clarity across the data lifecycle by breaking pipelines into three logical layers:
- Bronze: Ingest raw data in its original format (often semi-structured or unstructured)
- Silver: Clean, normalize, and enrich the data for usability
- Gold: Aggregate and transform the data for reporting, dashboards, and machine learning
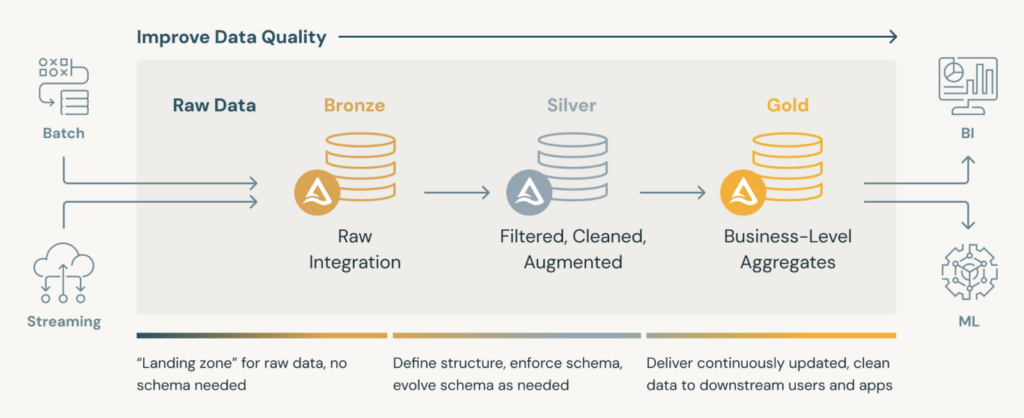
This layered approach is valuable for teams looking to establish governed and scalable data pipelines. It supports incremental refinement of data and enables multiple consumers to work from well-defined stages.
Challenges of the Medallion Architecture
The Medallion Architecture also introduces challenges:
- Pipeline delays: Moving data from Bronze to Gold can take minutes or longer—too slow for operational needs
- Infrastructure overhead: Each stage typically requires its own compute and storage footprint
- Redundant processing: Data transformations are often repeated across layers
- Limited operational use: Data is primarily at rest in object storage; using it for real-time operational systems often requires inefficient reverse ETL pipelines.
For use cases that demand real-time responsiveness and/or critical SLAs—such as fraud detection, personalized recommendations, or IoT alerting—this traditional batch-first model may fall short. In such cases, an event-driven streaming-first architecture, powered by a data streaming platform like Confluent, enables faster, more cost-efficient pipelines by performing validation, enrichment, and even model inference before data reaches the lakehouse.
Importantly, this data streaming approach doesn’t replace the Medallion pattern—it complements it. It allows you to “shift left” critical logic, reducing duplication and latency while still feeding trusted, structured data into Delta Lake or other downstream systems for broader analytics and governance.
In other words, shifting data processing left (i.e., before it hits a data lake or Lakehouse) is especially valuable when the data needs to serve multiple downstream systems—operational and analytical alike—because it avoids duplication, reduces latency, and ensures consistent, high-quality data is available wherever it’s needed.
Shift Left Architecture: Process Earlier, Share Faster
In a Shift Left Architecture, data processing happens earlier—closer to the source, both physically and logically. This often means:
- Transforming and validating data as it streams in
- Enriching and filtering in real time
- Sharing clean, usable data quickly across teams AND different technologies/applications
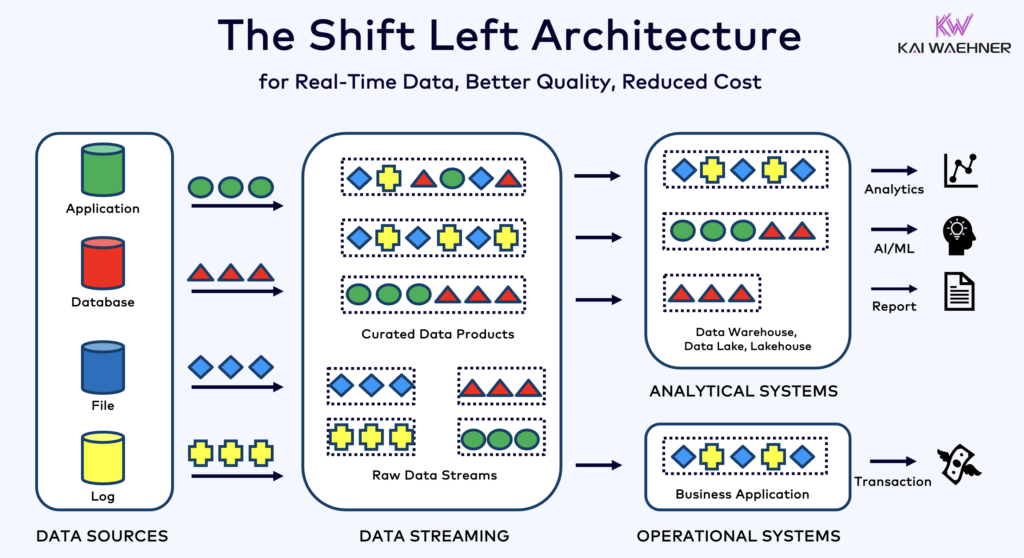
This is especially useful for:
- Reducing time to insight
- Improving data quality at the source
- Creating reusable, consistent data products
- Operational workloads with critical SLAs
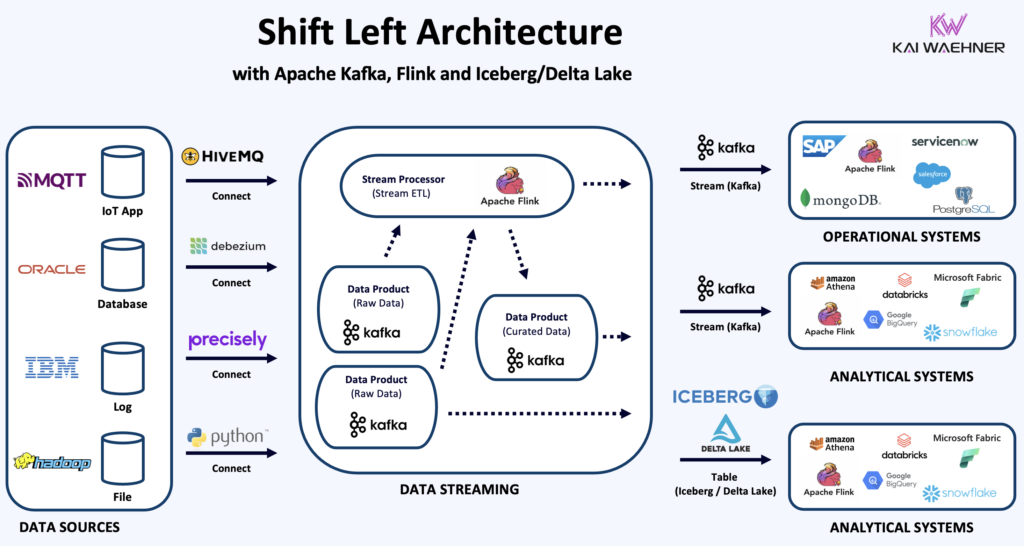
How Confluent Enables Shift Left with Databricks
In a Shift Left setup, Apache Kafka provides scalable, low-latency, and truly decoupled ingestion of data across operational and analytical systems, forming the backbone for unified data pipelines.
Schema Registry and data governance policies enforce consistent, validated data across all streams, ensuring high-quality, secure, and compliant data delivery from the very beginning.
Apache Flink enables early data processing — closer to where data is produced. This reduces complexity downstream, improves data quality, and allows real-time decisions and analytics.
Data Quality Governance via Data Contracts and Schema Validation
Flink can enforce data contracts by validating incoming records against predefined schemas (e.g., using JSON Schema, Apache Avro or Protobuf with Schema Registry). This ensures structurally valid data continues through the pipeline. In cases where schema violations occur, records can be automatically routed to a Dead Letter Queue (DLQ) for inspection.
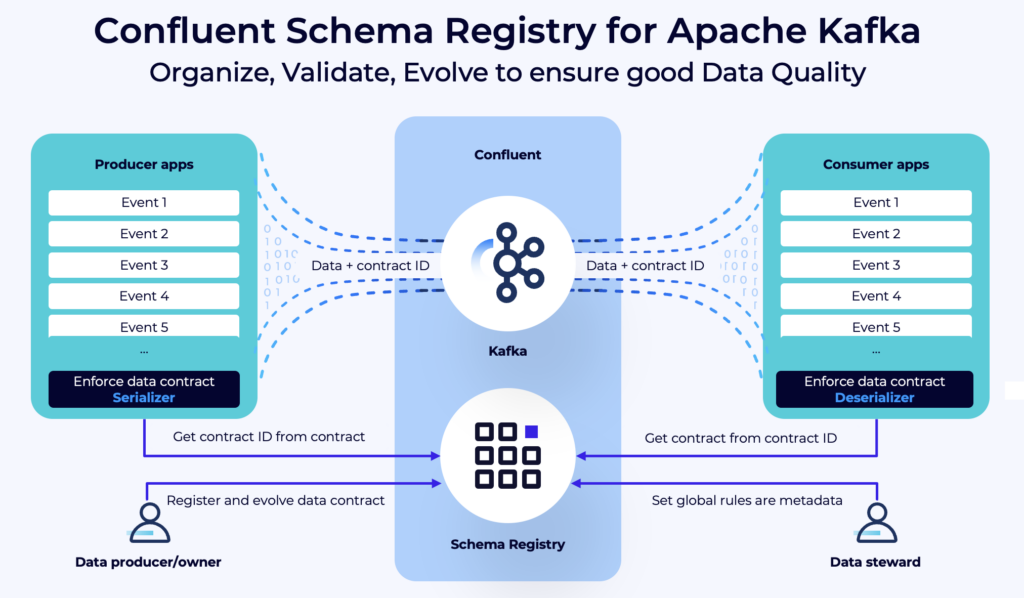
Additionally, data contracts can enforce policy-based rules at the schema level—such as field-level encryption, masking of sensitive data (PII), type coercion, or enrichment defaults. These controls help maintain compliance and reduce risk before data reaches regulated or shared environments.
Apache Flink for Continuous Stream Processing
Flink can perform the following tasks before data ever lands in a data lake or warehouse:
Filtering and Routing
Events can be filtered based on business rules and routed to the appropriate downstream system or Kafka topic. This allows different consumers to subscribe only to relevant data, optimizing both performance and cost.
Metric Calculation
Use Flink to compute rolling aggregates (e.g., counts, sums, averages, percentiles) over windows of data in motion. This is useful for business metrics, anomaly detection, or feeding real-time dashboards—without waiting for batch jobs.
Real-Time Joins and Enrichment
Flink supports both stream-stream and stream-table joins. This enables real-time enrichment of incoming events with contextual information from reference data (e.g., user profiles, product catalogs, pricing tables), often sourced from Kafka topics, databases, or external APIs.
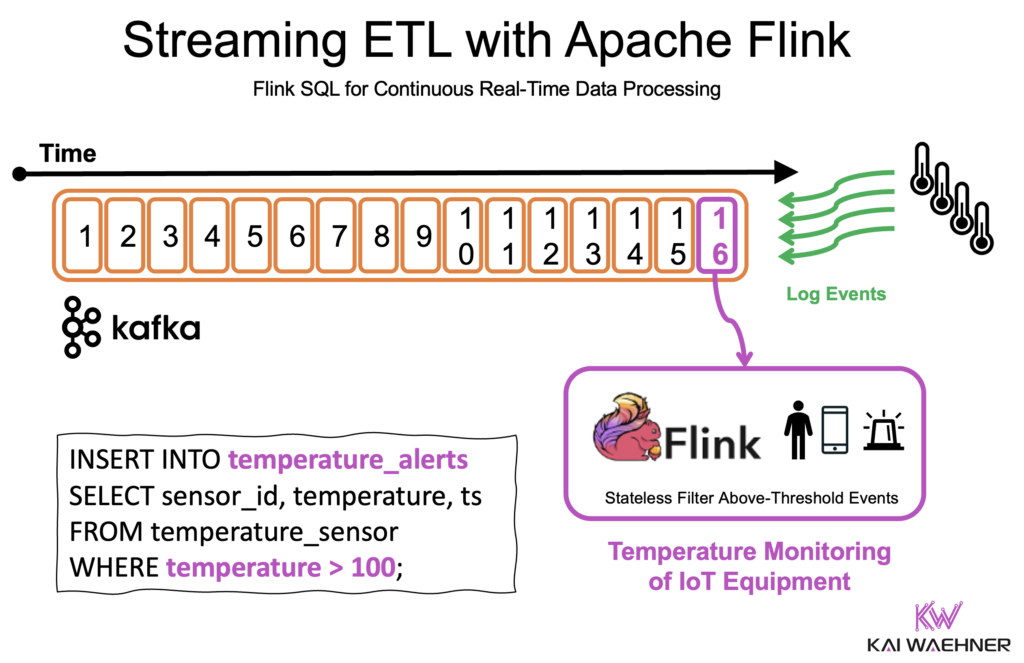
By shifting this logic to the beginning of the pipeline, teams can reduce duplication, avoid unnecessary storage and compute costs in downstream systems, and ensure that data products are clean, policy-compliant, and ready for both operational and analytical use—as soon as they are created.
Example: A financial application might use Flink to calculate running balances, detect anomalies, and enrich records with reference data before pushing to Databricks for reporting and training analytic models.
In addition to enhancing data quality and reducing time-to-insight in the lakehouse, this approach also makes data products immediately usable for operational workloads and downstream applications—without building separate pipelines.
Learn more about stateless and stateful stream processing in real-time architectures using Apache Flink in this in-depth blog post.
Combining Shift Left with Medallion Architecture
These architectures are not mutually exclusive. Shift Left is about processing data earlier. Medallion is about organizing data once it arrives.
You can use Shift Left principles to:
- Pre-process operational data before it enters the Bronze layer
- Ensure clean, validated data enters Silver with minimal transformation needed
- Reduce the need for redundant processing steps between layers
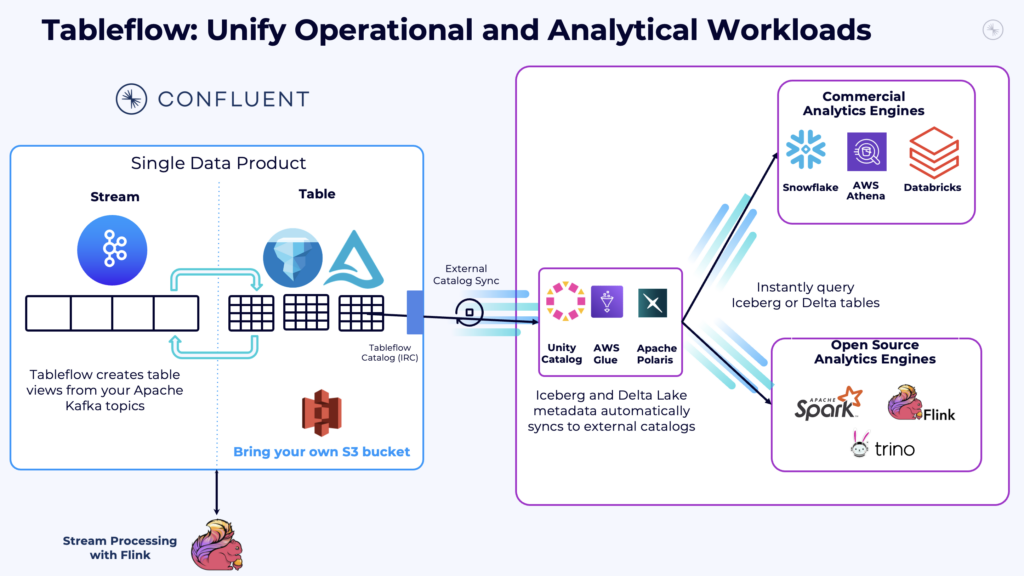
Confluent’s Tableflow bridges the two worlds. It converts Kafka streams into Delta tables, integrating cleanly with the Medallion model while supporting real-time flows.
Shift Left with Delta Lake, Iceberg, and Tableflow
Confluent Tableflow makes it easy to publish Kafka streams into Delta Lake or Apache Iceberg formats. These can be discovered and queried inside Databricks via Unity Catalog.
This integration:
- Simplifies integration, governance and discovery
- Enables live updates to AI features and dashboards
- Removes the need to manage Spark streaming jobs
This is a natural bridge between a data streaming platform and the lakehouse.
AI Use Cases for Shift Left with Confluent and Databricks
The Shift Left model benefits both predictive and generative AI:
- Model training: Real-time data pipelines can stream features to Delta Lake
- Model inference: In some cases, predictions can happen in Confluent (via Flink) and be pushed back to operational systems instantly
- Agentic AI: Real-time event-driven architectures are well suited for next-gen, stateful agents
Databricks supports model training and hosting via MosaicML. Confluent can integrate with these models, or run lightweight inference directly from the stream processing application.
Data Warehouse Use Cases for Shift Left with Confluent and Databricks
- Batch reporting: Continue using Databricks for traditional BI
- Real-time analytics: Flink or real-time OLAP engines (e.g., Apache Pinot, Apache Druid) may be a better fit for sub-second insights
- Hybrid: Push raw events into Databricks for historical analysis and use Flink for immediate feedback
Where you do the data processing depends on the use case.
Architecture Benefits Beyond Technology
Shift Left also brings architectural benefits:
- Cost Reduction: Processing early can lower storage and compute usage
- Faster Time to Market: Data becomes usable earlier in the pipeline
- Reusability: Processed streams can be reused and consumed by multiple technologies/applications (not just Databricks teams)
- Compliance and Governance: Validated data with lineage can be shared with confidence
These are important for strategic enterprise data architectures.
Bringing in New Types of Data
Shift Left with a data streaming platform supports a wider range of data sources:
- Operational databases (like Oracle, DB2, SQL Server, Postgres, MongoDB)
- ERP systems (SAP et al)
- Mainframes and other legacy technologies
- IoT interfaces (MQTT, OPC-UA, proprietary IIoT gateway, etc.)
- SaaS platforms (Salesforce, ServiceNow, and so on)
- Any other system that does not directly fit into the “table-driven analytics perspective” of a Lakehouse
With Confluent, these interfaces can be connected in real time, enriched at the edge or in transit, and delivered to analytics platforms like Databricks.
This expands the scope of what’s possible with AI and analytics.
Shift Left Using ONLY Databricks
A shift left architecture only with Databricks is possible, too. A Databricks consultant took my Shift Left slide and adjusted it that way:
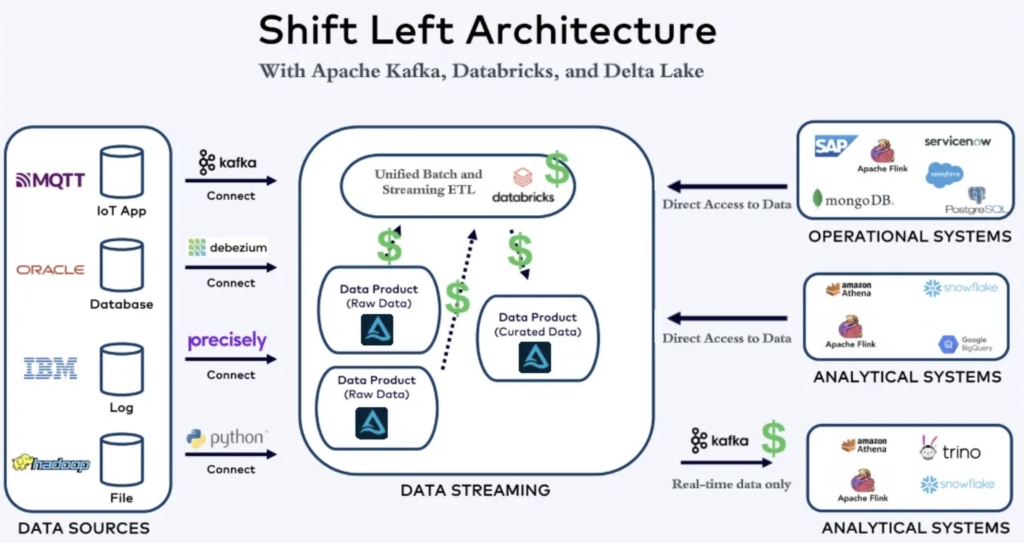
Relying solely on Databricks for a “Shift Left Architecture” can work if all workloads (should) stay within the platform — but it’s a poor fit for many real-world scenarios.
Databricks focuses on ELT, not true ETL, and lacks native support for operational workloads like APIs, low-latency apps, or transactional systems. This forces teams to rely on reverse ETL tools – a clear anti-pattern in the enterprise architecture – just to get data where it’s actually needed. The result: added complexity, latency, and tight coupling.
The Shift Left Architecture is valuable, but in most cases it requires a modular approach, where streaming, operational, and analytical components work together — not a monolithic platform.
That said, shift left principles still apply within Databricks. Processing data as early as possible improves data quality, reduces overall compute cost, and minimizes downstream data engineering effort. For teams that operate fully inside the Databricks ecosystem, shifting left remains a powerful strategy to simplify pipelines and accelerate insight.
Meesho: Scaling a Real-Time Commerce Platform with Confluent and Databricks
Many high-growth digital platforms adopt a shift-left approach out of necessity—not as a buzzword, but to reduce latency, improve data quality, and scale efficiently by processing data closer to the source.
Meesho, one of India’s largest online marketplaces, relies on Confluent and Databricks to power its hyper-growth business model focused on real-time e-commerce. As the company scaled rapidly, supporting millions of small businesses and entrepreneurs, the need for a resilient, scalable, and low-latency data architecture became critical.
To handle massive volumes of operational events — from inventory updates to order management and customer interactions — Meesho turned to Confluent Cloud. By adopting a fully managed data streaming platform using Apache Kafka, Meesho ensures real-time event delivery, improved reliability, and faster application development. Kafka serves as the central nervous system for their event-driven architecture, connecting multiple services and enabling instant, context-driven customer experiences across mobile and web platforms.
Alongside their data streaming architecture, Meesho migrated from Amazon Redshift to Databricks to build a next-generation analytics platform. Databricks’ lakehouse architecture empowers Meesho to unify operational data from Kafka with batch data from other sources, enabling near real-time analytics at scale. This migration not only improved performance and scalability but also significantly reduced costs and operational overhead.
With Confluent managing real-time event processing and ingestion, and Databricks providing powerful, scalable analytics, Meesho is able to:
- Deliver real-time personalized experiences to customers
- Optimize operational workflows based on live data
- Enable faster, data-driven decision-making across business teams
By combining real-time data streaming with advanced lakehouse analytics, Meesho has built a flexible, future-ready data infrastructure to support its mission of democratizing online commerce for millions across India.
Shift Left: Reducing Complexity, Increasing Value for the Lakehouse (and other Operational Systems)
Shift Left is not about replacing Databricks. It’s about preparing better data earlier in the pipeline—closer to the source—and reducing end-to-end complexity.
- Use Confluent for real-time ingestion, enrichment, and transformation
- Use Databricks for advanced analytics, reporting, and machine learning
- Use Tableflow and Delta Lake to govern and route high-quality data to the right consumers
This architecture not only improves data quality for the lakehouse, but also enables the same real-time data products to be reused across multiple downstream systems—including operational, transactional, and AI-powered applications.
The result: increased agility, lower costs, and scalable innovation across the business.
Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And download my free book about data streaming use cases, including more details about the shift left architecture with data streaming and lakehouses.