Data streaming is now a strategic layer in modern data architecture. Real-time beats slow data across industries. From fraud detection in finance to personalization in retail to predictive maintenance in manufacturing, enterprises rely on a truly decoupled, event-driven architecture and continuous processing of data in motion. What began as open-source frameworks like Apache Kafka, Flink and Spark Streaming has evolved into a completely new software category: the Data Streaming Platform (DSP). A DSP connects to any system, streams and processes data at scale, and provides governance, security, and SLAs. This landscape for 2026 shows the current status of relevant vendors and cloud services, sorted by adoption, completeness, and deployment models.
What does your enterprise landscape for data streaming look like? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter. Make sure to download my free ebook about data streaming use cases and industry examples.
Disclaimer: The views and opinions expressed in this blog are strictly my own and do not necessarily reflect the official policy or position of my employer.
What Data Streaming Means in This Landscape
The term “data streaming” is often stretched to cover very different technologies. Some vendors equate it with simple event messaging. Others use it for analytical databases that refresh every few seconds. Some use it just as an ingestion layer into a data lake or lakehouse. This landscape applies a more focused definition.
Data streaming in the context of this landscape means a complete platform for data in motion. A Data Streaming Platform connects to diverse systems, continuously ingests and persists data, applies real-time processing and business logic, enforces governance, and delivers the results wherever they are needed. It combines connectivity, streaming, processing, and control into one strategic backbone.
This is why some technologies and solutions are out of scope:
- Messaging systems provide real-time transport but lack integration, processing, and end-to-end governance across entire data pipelines.
- Data ingestion components or separate tools/vendors move data into a data lake, but they are not a DSP. They provide just one step: ingestion, but not the goal to build an event-driven architecture with decoupled systems, application independent data products, operational microservices, etc.
- Analytical systems consume streaming data but are focused on analytics with the data at rest as a complementary tool in the stack.
- Streaming databases are promising, but adoption is early, as few use cases today require their specialized capabilities over a general-purpose data streaming platform.
The focus is on data streaming platforms that support business critical operations. Not just dashboards. Not just experimentation. Enterprises run their core processes on data streaming; at any scale, and across clouds and on-premise systems. Payment processing, fraud prevention, customer engagement, manufacturing control, and AI automation for transactional workloads all depend on it.
Kafka Protocol is THE De Facto Standard for Data Streaming
Apache Kafka is the foundation. The Kafka protocol has become the de facto standard for data streaming. Over 150,000 organizations use Kafka today. Almost every vendor in the landscape either builds directly on Apache Kafka or implements the Kafka protocol.

This standardization provides interoperability but also creates confusion. Kafka compatibility is not the same as Apache Kafka itself. Many offerings that claim Kafka compatibility leave out essential parts of the Apache Kafka ecosystem such as Kafka Streams, Kafka Connect, or core protocol features like exactly-once semantics and the Transaction API.
Enterprises must look beyond Kafka protocol support and assess whether a vendor provides the completeness of a Data Streaming Platform. To be clear: full Apache Kafka feature compatibility is a baseline requirement. It is table stakes for any platform that claims to be a data streaming platform. But it is only the starting point. A complete DSP must also deliver enterprise-grade processing, governance, security, observability, and seamless data mobility across cloud and on-premise environments.
Equally important is 24/7 enterprise support to ensure reliability at scale. Beyond that, deep consulting expertise is essential to design, scale, and optimize complex architectures. This includes guidance for multi-cloud strategies, disaster recovery, and security/compliance best practices. Some vendors even exclude Kafka support entirely from their offering while still claiming compatibility. That is not acceptable for serious enterprise deployments.
The Business Value of Data Streaming
Nobody buys technology for its own sake. Enterprises invest in data streaming to drive business outcomes. A new software category only becomes relevant when it enables new use cases and creates measurable value.
A data streaming platform opens opportunities across industries:
- Generate new revenue streams through personalization and real-time offers.
- Reduce costs with predictive maintenance and optimized supply chains.
- Lower risk through fraud detection and compliance monitoring.
- Improve customer experience with instant responses and seamless digital services.
- Accelerate time to market by decoupling systems and teams, enabling faster iteration and deployment.
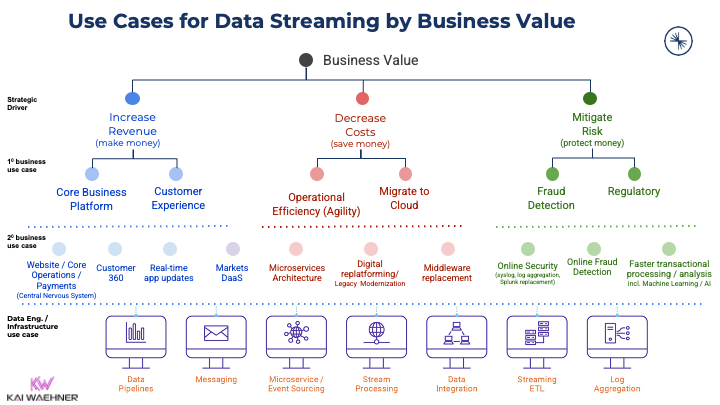
This focus on business value explains why more and more software vendors integrate Kafka support into their products. It is not only about moving data faster. It is about enabling a future-ready architecture that supports growth, efficiency, and resilience.
For concrete examples, see the book How Industry Leaders Leverage Data Streaming – The Use Case Book. It provides detailed case studies, business value scenarios, and architectures across industries, from financial services and automotive to telco and retail, showing how organizations turn streaming data into measurable business value.
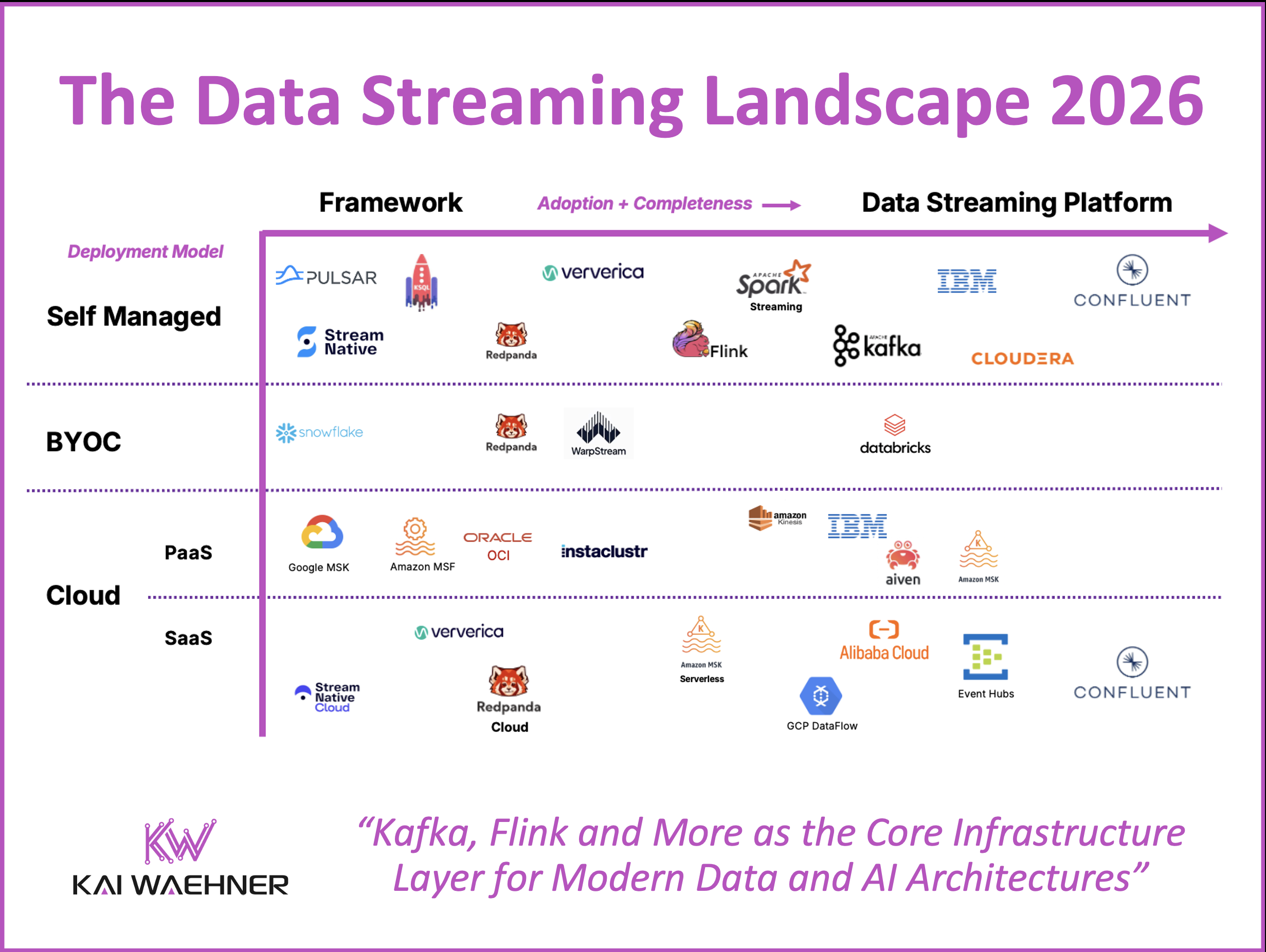
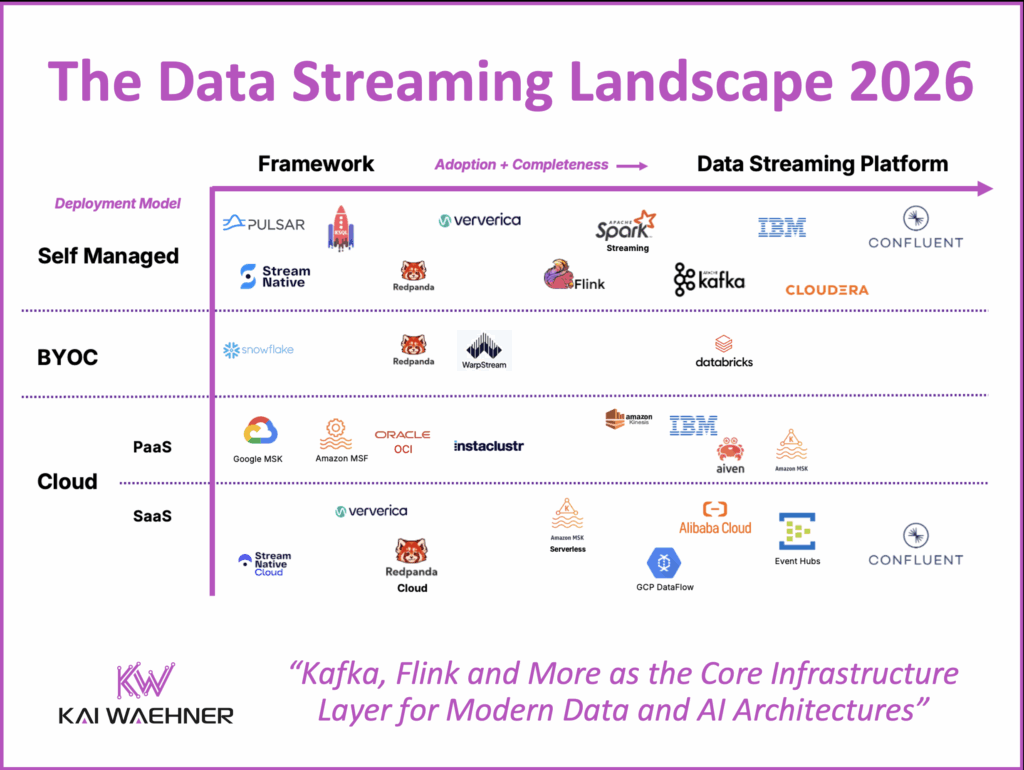
The Data Streaming Landscape 2026
Data streaming is a separate software category of data platforms. Many vendors built their entire business on it. At the same time, established players in the data space added streaming capabilities to their portfolios.
The Data Streaming Landscape focuses on adoption and completeness of data streaming platforms, along with the deployment models that define how enterprises operate them. It is not an exhaustive vendor list, but a reflection of what is actually seen in the field: with customers, partners, analysts, and the broader community.
The diagram below shows the Data Streaming Landscape 2026. Vendors and services are positioned by adoption and completeness (X-axis) and by deployment model (Y-axis).

Market Movements From 2025 to 2026
The 2026 update reflects significant shifts in vendor positioning, new entrants, and some removals. To highlight the evolution of the category, the following diagram shows the movements and changes from 2025 to 2026. It visualizes which vendors moved left or right on the adoption and completeness axis, which disappeared, and which entered the landscape.
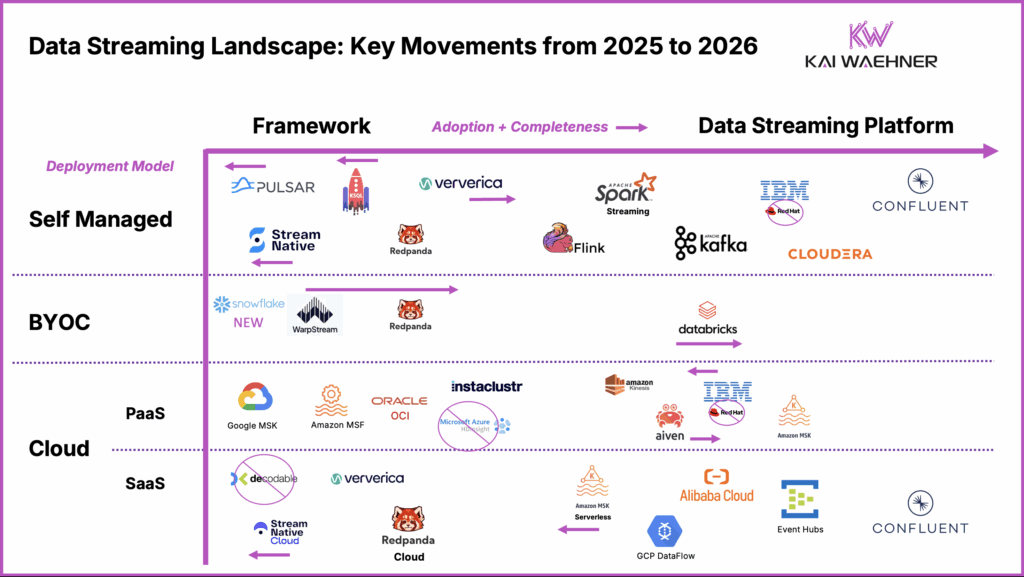
Together, these two visuals provide the snapshot for this year’s analysis. They reflect both technology evolution and strategic repositioning across the data streaming ecosystem.
Before diving into each deployment model and vendor position in more detail, here are the key movements to note:
- Removed Microsoft Azure HDInsight (legacy only). Still used in old Hadoop environments, but no enterprise should start new streaming projects on it anymore.
- Removed the Red Hat logo; Kafka and middleware are now part of IBM. The middleware teams were fully absorbed into IBM’s portfolio in 2025, so it no longer makes sense to show Red Hat separately.
- Moved ksqlDB left. The technology remains available and useful for Kafka-native SQL workloads, but Confluent has shifted its strategic focus to Apache Flink as the stream processing standard.
- Removed Decodable; acquired by Redis. Redis is building out a real-time platform with this acquisition, but it is too early to include Redis in the landscape.
- Moved Pulsar and StreamNative left. Adoption has stalled, and traction in the market is very limited. While still actively developed, Pulsar projects are not gaining ground compared to Kafka-based platforms.
- Moved WarpStream and Ververica right. Each showed incremental progress: WarpStream with traction in BYOC and many new customer references across industries, and Ververica with steady growth in Flink use in self-managed environments.
- Swapped IBM left and Aiven right in PaaS. Aiven has gained ground with its managed Kafka and Flink offerings across multiple clouds, while IBM’s streaming presence has become less prominent.
- Added Snowflake as a new entrant in PaaS. Streaming is not its core, but with SnowPipe Streaming, OpenFlow, and Dynamic Tables, Snowflake is now part of the streaming conversation.
- MSK Serverless was moved left due to limited visibility and low adoption. It’s important not to confuse this with Amazon MSK (the partially managed version), which remains solid. MSK continues to see strong adoption and has received a few improvements over the past year.
- Oracle’s OCI Streaming with Apache Kafka is now GA. The focus is on enterprise-grade security, disaster recovery, and large-scale contracts, positioning it alongside other PaaS services like MSK with a different value proposition.
Redpanda and the Shift to the “Agentic Data Plane”
Redpanda has rebranded itself as an AI platform, now calling its product the “Agentic Data Plane.” Kafka compatibility is still part of the product, but it has moved far into the background. You have to scroll quite a bit on Redpanda’s landing page before Kafka even shows up.
This shift raises questions. Is this a strategic evolution? Or a response to limited adoption and growth in the core data streaming space?
For now, Redpanda remains in the same position as last year in the data streaming landscape. Its new direction is unclear, and the platform’s role in enterprise-grade data streaming architectures is uncertain. The focus on AI and agents may open new use cases, but whether it can deliver the completeness and reliability required for business-critical data streaming remains to be seen.
Adoption and Completeness of Data Streaming Platforms (X-Axis)
Data streaming is adopted more and more across all industries. The concept is not new. In “The Past, Present and Future of Stream Processing“, I explored how the data streaming journey started decades ago with research and the first purpose-built proprietary products for specific use cases like stock trading.
Open source stream processing frameworks emerged during the big data and Hadoop era to make at least the ingestion layer a bit more real-time. Is anyone still remembering (or even still using) Apache Storm?
Today, most enterprises are realizing the value of data streaming for both analytical and operational use cases across all verticals and for various use cases. The cloud has brought a transformative shift, enabling businesses to start streaming and processing data with just a click, using fully managed SaaS solutions, intuitive UIs, and consumption-based pricing.
Complete data streaming platforms now offer many built-in features that users previously had to develop themselves, including connectors, encryption, access control, governance, data sharing, and more.
Capabilities of a Data Streaming Platform (DSP)
The requirements for a DSP are much broader than real-time messaging. A complete platform provides:
- Messaging and durability: real-time transport with a persistence layer to enable reliable communication, decoupling between systems, and replay of events when needed.
- Data integration: connectors to legacy and cloud-native systems.
- Stream processing: stateless and stateful transformations, business logic, and enrichment.
- Operational controls: Central enforcement layer for security, compliance, and multi-tenancy; adds encryption and policy control without changing clients or Kafka clusters.
- AI capabilities: real-time model inference, streaming agents, integration with AI tools/standards (like MCP) and vector databases.
- Data governance: security, observability, lineage, and compliance.
- Tooling: APIs, SDKs, and UIs for developers, operators, and analysts.
- Operations: managed services or automation for scalability, resilience, and upgrades.
- SLAs and support: guarantees for mission-critical use cases.
Deployment Models for a Data Streaming Platform (Y-Axis)
The data streaming landscape organizes vendors by deployment model and platform completeness. The four deployment models are self-managed, bring your own cloud (BYOC), cloud platform as a service (Cloud PaaS), and fully managed software as a service (Cloud SaaS).
Many organizations use a combination of these deployment models to support different use cases or to enable hybrid and multi-cloud integration.
Self-Managed
This category includes both open-source frameworks and vendor products that customers run themselves. Deployment of self-managed data streaming is usually in their own data center, but it can also be in a cloud VPC or at the edge outside a traditional data center.

The open source frameworks Apache Kafka, Apache Flink, and Spark Streaming remain widely deployed in enterprises, often as part of cloud-native Kubernetes environments. The vendors Confluent, Cloudera, and IBM provide commercial packaging and tooling. These vendors lead self-managed Kafka deployments.
Redpanda offers a Kafka-compatible implementation written in C++. Ververica provides a commercial platform around stream processing with Apache Flink, including enterprise features, management tools, and support.
Pulsar and StreamNative continue to lose relevance. Their complexity and lack of traction move them further left. ksqlDB remains feature complete but is no longer evolving.
Bring Your Own Cloud (BYOC)
BYOC sits between self-managed and SaaS. The infrastructure runs in the customer’s cloud account, while parts of the control plane are managed by a vendor.
Different BYOC models exist, and not all are created equal. Some are less secure or harder to operate, for example when they do not follow zero trust principles for the data plane. Read more about BYOC and the reasons behind the different (sometimes hidden) deployment models in my blog post: BYOC Deployment Options for Apache Kafka.

WarpStream changed the perception of BYOC with its stateless zero trust architecture. Only stateless agents run in the customer VPC, while metadata and control remain in the vendor’s managed service. This provides security and sovereignty without giving the vendor full access to customer infrastructure.
Redpanda also offers BYOC but requires vendor access into the customer VPC, which weakens its security and compliance story.
Databricks also falls into this category. Spark Streaming and related tools provide near-real-time processing, but the company’s main focus remains on data engineering, analytics, and AI. Data streaming is not its core business, but an extension of the broader Databricks Intelligence Platform. The stream processing-like micro-batching features improved and the adoption grows.
Snowflake follows a similar path. Its brand is built on BI, analytics, and AI. Most of the platform is consumed as fully managed SaaS, but its newer streaming features, OpenFlow (based on Apache NiFi) and Snowpipe Streaming, extend data ingestion beyond batch. OpenFlow acts as a universal connector framework for Kafka, databases, and SaaS apps, while Snowpipe Streaming gives developers a low-latency SDK for direct event ingestion. Together with Dynamic Tables, these tools enable incremental data processing and continuous transformation. However, data streaming remains an extension mainly for data ingestion with various limitations, not Snowflake’s core platform focus.
Cloud PaaS
Platform-as-a-Service (PaaS) offerings reduce operational burden but still require customer involvement in scaling, upgrades, and tuning.

Amazon MSK is by far the largest of these partially managed services and continues to improve with features such as Tiered Storage and Express Brokers. However, MSK still excludes Kafka support (make sure to read the terms and conditions) and does not support in-place Kafka Cluster upgrades from ZooKeeper to KRaft.
Google offers a similar Kafka PaaS, still in very early stage of the maturity lifecycle. Oracle’s OCI Kafka service is now generally available, focusing on security and disaster recovery for enterprise contracts; but also not a mature product yet.
Aiven and Instaclustr provide Kafka and Flink as partially managed services across clouds. Aiven sees some momentum in the community with its diskless Kafka efforts. IBM remains in the landscape with Kafka on OpenShift and added features like ZooKeeper-less KRaft and Tiered Storage.
Amazon also extends its streaming portfolio with Managed Service for Apache Flink (MSF). While it brings native integration with AWS data services, the offering is still relatively immature. Users must handle much of the configuration, scaling, and operational tuning themselves, with limited automation and few enterprise-grade enhancements. In many ways, MSF today resembles MSK in its early days: functional, but requiring significant hands-on management to reach production-grade reliability.
Cloud SaaS
Fully managed Software-as-a-Service (SaaS) is the most attractive option for most enterprises (if security and compliance allow the usage of serverless offerings). Vendors take over scaling, resilience, and upgrades. Customers focus only on data pipelines and applications, paying with consumption-based, predictable pricing.
Confluent Cloud remains the most complete Data Streaming Platform. It combines Kafka and Flink with built-in governance, security, and deep connectivity to enterprise and cloud-native systems leveraging connectors, APIs, and native integration from the partner ecosystem. The platform delivers enterprise-grade SLAs, elastic scaling, and multi-region resilience across edge, hybrid and multi-cloud deployments. With by far the strongest customer base in the market for cloud-native offerings, Confluent also leads in public case studies across industries, showing how real-time data streaming drives measurable business outcomes at scale. Confluent’s Tableflow capability also tackles one of the toughest architectural problems: unifying operational and analytical workloads. By deeply integrating Apache Iceberg and Delta Lake with streaming data, it enables governed, low-latency delivery of streaming data into analytic tables, going far beyond what traditional Open Table Format connectors offer. My blog post “Data Streaming Meets Lakehouse: Apache Iceberg for Unified Real-Time and Batch Analytics” explores this challenge in more detail.
Azure Event Hubs, Amazon MSK Serverless, and Google Dataflow continue as specialized SaaS offerings with narrower focus. While Azure Event Hubs and Google Dataflow steadily grow in adoption, MSK Serverless has seen limited traction. Most AWS customers still prefer the MSK PaaS model for some reason. My assumption would be the limited features and too high cost of MSK Serveless.
Redpanda Cloud offers a fully managed, Kafka-compatible service focused on high performance and low latency, but adoption of Redpanda’s SaaS offering remains limited and niche, mostly in specialized edge and performance-critical use cases. StreamNative Cloud provides a similar managed service for Apache Pulsar, though adoption is still smaller and focused mainly on a few early enterprise users exploring Pulsar-based architectures.
Ververica provides Flink as a managed service with similar positioning. It is available and functional, yet with relatively small market adoption.
Data Streaming Contenders to Consider
The following startups are too early for broad adoption but show the ongoing innovation around the Kafka protocol and streaming databases. Worth to consider but not yet mature and adopted enough to be placed in the data streaming landscape 2026. Maybe in 2027?
- Bufstream: Focused on high-performance, diskless Kafka implementations. Promises lower infrastructure costs and simplified scaling, but still early in production maturity and enterprise adoption.
- AutoMQ: Open-source alternative built for cloud object storage. Available in different deployment options. Gains attention for cost efficiency and elasticity but remains in early testing phases outside of China.
- Decodable (acquired by Redis): Redis acquired Decodable to add real-time stream processing to its data platform. Integration is still in progress, and it’s unclear how deeply Flink-based streaming will fit into Redis’s core ecosystem.
- RisingWave: A PostgreSQL-compatible streaming database that blends SQL simplicity with real-time analytics. Technically solid but still building a developer community and enterprise customer base.
- Materialize: Offers incremental, streaming SQL built on differential dataflow. Backed by strong engineering talent and VC funding but adoption remains limited to advanced analytics teams.
- DeltaStream: Started as a Flink-focused offering; likely similar adoption challenges like Decodable. Now rebranded as Fusion, a unified platform “built for the streaming-first era” that combines streaming (Flink), batch (Spark), and analytics (ClickHouse). Promising, but still very early in enterprise adoption.
Responsive, a startup that originally focused on stream processing with Kafka Streams, has shifted its focus to cloud native observability. Hence, it is not worth considering for data streaming anymore.
This reflects how difficult the market is for vendors offering stream processing only. Stream processing always depends on an event-driven architecture and a backbone like Kafka and does not work in isolation.
Using a separate vendor adds technical overhead and commercial friction. You need a separate contract, pay another vendor, and manage a different support agreement. Integrated platforms remove that complexity by offering streaming and processing in one solution.
Key Data Streaming Trends in 2026
Every year the landscape is followed by a separate blog post on data streaming trends. The trends piece takes a broader view across industries, vendors, and community developments. Last year’s edition, Top Trends for Data Streaming with Apache Kafka and Flink in 2025, can be found here. The 2026 version will be published shortly.
For now, here are the most relevant themes already visible in the market:
- Enterprise-Grade SLAs for Zero Data Loss (RPO=0): Streaming powers mission-critical workloads where downtime or data loss is unacceptable. Enterprises demand RPO=0, governance, and simpler, automated disaster recovery because they shift data streaming platforms toward full operational resilience.
- Regional Cloud Partnerships and Data Sovereignty: Data privacy rules drive regional Kafka deployments through local cloud partners. Vendors like Confluent expand via Alibaba, Jio, and Saudi Telecom, balancing compliance, sovereignty, and performance.
- Diskless Kafka and Apache Iceberg Integration: Diskless Kafka and Iceberg redefine storage with cloud-native, cost-efficient architectures that unify real-time and historical data. This convergence reduces duplication and simplifies governance.
- Analytics Moves into the Streaming Layer: Analytics is merging with streaming. A data streaming platform can process both real-time and historical data, blurring the line between batch and stream processing and enabling unified insights for operations and AI.
- Data Streaming for Agentic AI: Real-time data becomes the backbone for generative and agentic AI. Streaming feeds models and agents with fresh context via MCP protocols, making DSPs the core infrastructure for intelligent systems.
- Market Consolidation Around Proven Platforms: The market narrows to mature platforms with strong ecosystems. Startups struggle, while leaders like Confluent and Databricks deepen partnerships and integrations across enterprise environments.
The full write-up on data streaming trends will follow the landscape release. Subscribe to my newsletter so you don’t miss it.
The Road Ahead for Data Streaming Platforms
Enterprises face a wide range of deployment choices. Self-managed frameworks provide flexibility but increase operational risk. BYOC is now credible thanks to WarpStream’s stateless zero trust model, but it should mainly be considered when sovereignty or compliance demand it. For most organizations, fully managed SaaS remains the most efficient path, with Confluent setting the benchmark for what a complete Data Streaming Platform should deliver. PaaS offerings such as Amazon MSK or Oracle OCI Kafka reduce some burden but still require active management.
Decisions should not be driven by cost alone. Business outcomes matter more: new revenue through personalization, risk reduction via fraud detection, or improved customer experience through instant services. The completeness of the platform, including connectivity, governance, and SLAs, is what ensures these outcomes.
Looking ahead, the market will continue to consolidate. Some projects, like Pulsar and ksqlDB, may vanish from the picture. Diskless Kafka is likely to become mainstream, bringing cost efficiency and elasticity. Streaming databases may find their niche as a separate category, or fade if adoption stalls. It may also take many years before broad enterprise demand makes them a true requirement.
Most importantly, expect tighter integration between data streaming and AI. AI only creates real business value when it runs on fresh, contextual data in operational environments. That requires unifying operational and analytical workloads on a single backbone. Enterprises will evolve from tactical pipelines toward strategic DSP adoption, with real-time, governed, hybrid and multi-cloud data streaming forming the foundation for next-generation applications and AI agents.
What does your enterprise landscape for data streaming look like? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter. Make sure to download my free ebook about data streaming use cases and industry examples.