Apache Kafka became the de facto standard for data streaming. However, the combination of an event-driven architecture with request-response APIs is crucial for most enterprise architectures. This blog post explores how Tinybird innovates with a REST/HTTP layer on top of the open source analytics database ClickHouse in the cloud. Integrating Kafka with Tinybird, the benefits of fully managed services like Confluent Cloud, and customer stories from Factorial and FanDuel show why Kafka and analytics databases complement each other for more innovation and faster time-to-market.

Tinybird = ClickHouse Analytics + HTTP APIs
Tinybird is powered by the open source database ClickHouse, but differentiates itself in the analytics market by providing a platform for providing real-time analytics as API.
ClickHouse and the Overwhelming Analytics Market
ClickHouse is an open-source column-oriented database management system designed for handling large-scale analytical workloads. The internal architecture is optimized for high performance and scalability, particularly for real-time analytics and OLAP (Online Analytical Processing) queries.
ClickHouse supports SQL queries and is optimized for fast data ingestion and querying of large volumes of data. The database is commonly used for data warehousing, time-series data analysis, and ad hoc analytics in various industries, including e-commerce, finance, and telecommunications.
ClickHouse is a great technology. However, in the analytics space, each database solution competes with various other open source frameworks, commercial products and fully managed cloud services. If you evaluate ClickHouse, you probably also evaluate:
- Analytics services of the cloud providers (like Amazon Redshift, Azure Synapse Analytics, Google BigQuery, etc.)
- Open source frameworks like Apache Druid (Imply), Pinot (StarTree), and others
- Data analytics platforms like Snowflake, Databricks, et al.
The overlapping between these products is huge. Of course, sweet spots exist for each technology. But it is a mass market and often only the big players grow consumption significantly while small vendors end up in a niche.
Tinybird does NOT try to compete directly with all the other analytic databases. Instead, it added an intuitive layer on top of ClickHouse to differentiate its product offering.
Tinybird Adds APIs on Top of ClickHouse for Simple Integration and Publishing of Applications
Tinybird is a real-time data pipeline platform designed to help developers build and deploy scalable data products quickly and efficiently. It offers a range of tools and features for ingesting, processing, and serving real-time data streams, including data transformation, aggregation, and analytics.
Tinybird earns its reputation for simplicity and ease of use. It enables users to create custom data pipelines, applications, and APIs without the need for extensive coding or infrastructure setup. The analytics platform focuses on building operational and user-facing use cases with requirements for fresh data, fast queries, and high concurrency. Tinybird is NOT focused on traditional BI use cases served by data warehouses.
Tinybird differentiates from the competition by being more than just a managed database. The platform provides an underlying database powered by ClickHouse. It meets performance and scale needs while focusing on solving the pain around the database: data ingestion, data publication, and development workflow.
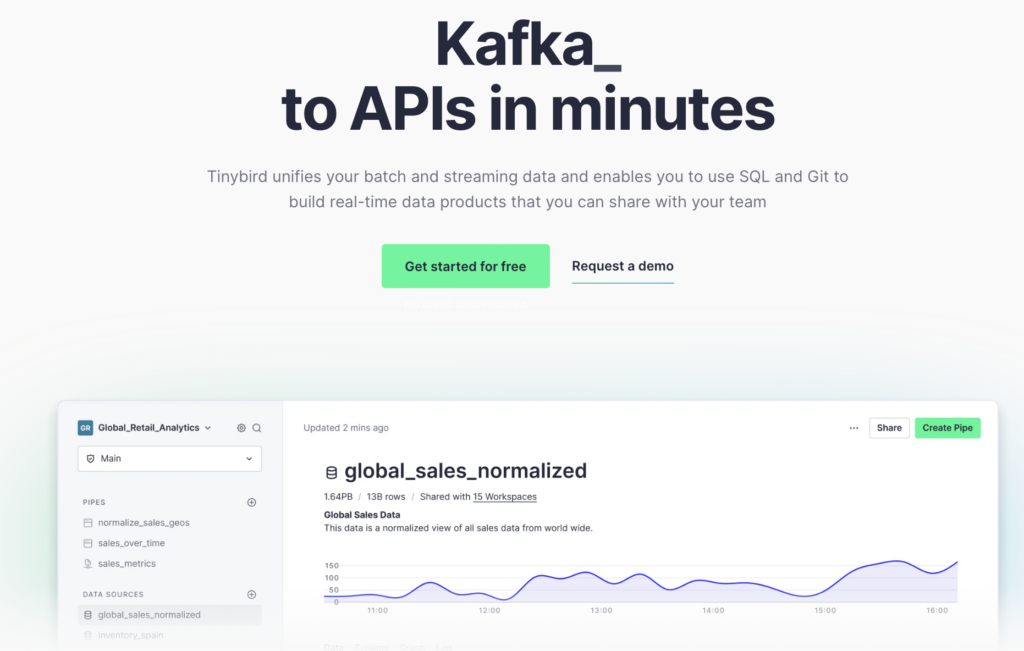
Tinybird helps users to productize their data as HTTP APIs for integration with external systems (lakes, data mesh, user-facing applications). The product covers the entire end-to-end experience, from data ingestion to analytics to publishing APIs. An intuitive UI for interactive development and prototyping in conjunction with a full ‘data as config’ development life cycle makes the development of analytics applications straightforward. Data integration, analytics, and publication are defined as config files, stored in a Git repository. Tools help with automatic CI/CD for testing and deployment, plus a CLI and plugins for developer IDEs.
Relation of ClickHouse and Tinybird to Data Streaming with Apache Kafka
Data streaming with Apache Kafka refers to the process of ingesting, processing, and analyzing real-time data with a distributed streaming platform. Kafka enables the creation of real-time data pipelines that can handle high volumes of data from various sources, allowing for continuous data ingestion, processing, and delivery.
Kafka became the de facto standard protocol for data streaming, like Amazon S3 is the de facto standard for object storage. However…
Apache Kafka is NOT Complex Analytics
Apache Kafka is a database (even though many people disagree or don’t like this statement). But Kafka is not the right platform for complex analytics. Kafka is complementary to other databases like MySQL, MongoDB, Elasticsearch, ClickHouse, et al.
Learn more about this in my article “When NOT to use Apache Kafka” or the following lightboard video:
You are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
To be very clear: Data streaming also includes analytics capabilities. Stream processing enables continues processing of data in motion in real-time at scale. Use cases include simple stateless streaming ETL and advanced stateful computations, including embedding AI and machine learning into a stream processor. However, the workloads differ from analytical databases like ClickHouse. For a better understanding of when to use stream processing, check out my blog about the perfect match between Apache Kafka and stream processing with Kafka Streams or Apache Flink.
Apache Kafka is NOT Request-Response APIs
Request-response communication with REST / HTTP is simple, well understood, and supported by most technologies, products, and SaaS cloud services. Contrarily, data streaming with Apache Kafka is a fundamental change to process data continuously.
Data streaming with Apache Kafka and request-response APIs like HTTP/REST complement each other in most enterprise architectures. I wrote a lot about this in the past:
-
When and how to integrate Request-Response with Apache Kafka?
-
Request-Response with REST/HTTP vs. Data Streaming with Apache Kafka – Friends, Enemies, Frenemies?
-
Apache Kafka and API Management like MuleSoft, Apigee, Long: Competition for Kafka or not?
TL;DR: The question is not if you need Kafka or APIs, but how to combine them the best way in your architecture. Vendors like Confluent provide native HTTP APIs and connectors to produce and consume with the Kafka API using HTTP. But for more advanced use cases, solutions like Tinybird are perfect in combination with Kafka.
Apache Kafka + Tinybird = Streaming Analytics APIs
The Tinybird website explains the relation between data streaming with Kafka and Tinybird very well:
“Turn your Kafka Streams into actionable API Endpoints your teams can consume. Instead of building a new consumer every time you want to make sense of your Data Streams, write SQL queries and expose them as API endpoints. Easy to maintain. Always up-to-date. Fast as can be.”
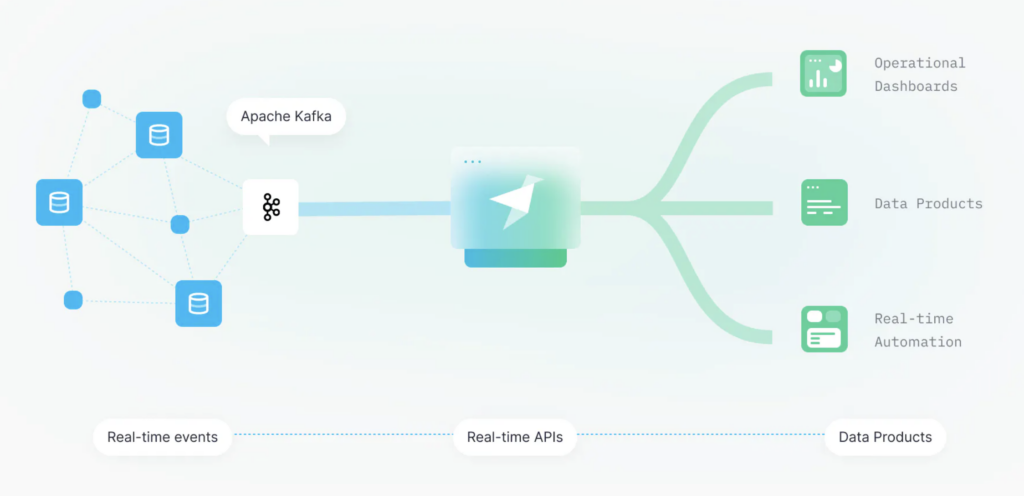
The Tinybird application development process is very simple:
- Connect to Kafka Topics via out-of-the-box Kafka integration.
- Store the events in a managed, columnar data source with schemas and a data contract for good data quality.
- Query the events with SQL to filter, aggregate, join and enrichments for fast and scalable analytics.
- Publish queries as dynamic, low-latency REST/HTTP APIs that scale.
Fully Managed Cloud Services for Streaming Analytics: Confluent Cloud + Tinybird
Fully managed cloud services offer simplified operations, scalability, high availability, security, compliance, cost savings, and performance optimization. They streamline infrastructure management, ensure reliability, enhance security, reduce costs, and optimize performance for businesses. Project teams focus on business logic and much faster time-to-market of new products and innovation.
Working for Confluent, I enjoy our fast growing “Connect with Confluent” partner program to see how customers build innovative applications in a cloud-native fully managed environment, including end-to-end integration and data governance.
Confluent Cloud has fully integrated Tinybird. Developers build new applications with HTTP APIs on top of data streaming with Kafka faster than ever before. Check out this screencast to learn how you can publish an API from a Kafka stream in four minutes leveraging Confluent Cloud and Tinybird.
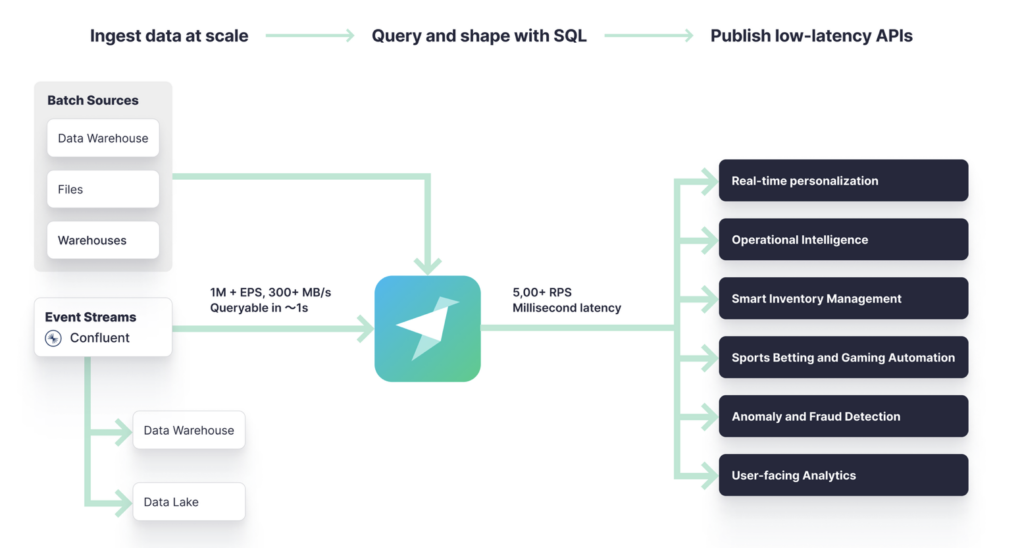
Data streaming truly decoupled the business domains. In the above diagram, you see a very common scenario: various consumers of the same business information (i.e., a single Kafka Topic). Some in real-time (like Tinybird), some in near real-time or batch (like Snowflake or Databricks).
Each developer can use different programming languages, databases, or SaaS analytics platforms. Apache Kafka unifies operational and analytical workloads. As a result, a Tinybird application aggregates transactional and analytical workloads to build new APIs.
Customer Stories using Kafka in Confluent Cloud and Tinybird for Real-Time Analytics
This section explores a few real world case studies that combine Apache Kafka and ClickHouse under the hood of Confluent Cloud’s and Tinybird’s SaaS cloud solutions.
Factorial Human Resources (HR) Software: Data Freshness for Users
Factorial is provides human resources (HR) software solutions for over 8000 small and medium-sized businesses. Their platform offers features such as employee onboarding, time tracking, leave management, performance reviews, and HR analytics. Factorial streamlines HR processes, boosts employee productivity, and allows businesses to effectively manage their workforce. People leaders can focus on people, not paperwork.
With data streaming and real-time analytics leveraging fully managed cloud services from Confluent and Tinybird, Factorial has improved its data freshness and reduced query latency, leading to significantly faster user feature launches. Read the detailed success story on the Confluent blog.
FanDuel: Customer Personalization and Fraud Prevention in Gambling and Sports Betting
FanDuel is operating in the online gambling and sports betting industry in the United States. I had the pleasure of hosting the company as guest speakers at executive dinner events in London.
FanDuel is a popular sports betting and daily fantasy sports company. It provides online platforms and mobile apps for users to place bets on various sports events and take part in fantasy sports contests. FanDuel has gained a reputation for its user-friendly interface, a wide range of betting options, and innovative features in the online gambling market.
The entire gambling and betting industry leverages data streaming for real-time data procession, transactional payment processing, fraud detection, customer loyalty platforms, and many other use cases. Read more about this topic in the state of data streaming for the betting industry and Kafka case studies for betting.
FanDuel leverages the combination of Confluent Cloud and Tinybird for real-time analytics use cases with user-facing applications and mobile apps.
Fanduel’s case study quotes: “Fanduel uses Confluent and Tinybird to power real-time personalization across all their sports betting solutions to improve time-to-first-bet and reduce the risk of fraud.”
If you need APIs on Top of Data Streaming and Analytics, choose Kafka and Tinybird
… and if you want a fully managed end-to-end data pipeline with out-of-the-box connectivity, critical SLAs and cloud-native elasticity and pricing, go with Confluent Cloud and Tinybird. Of course, the data streaming landscape 2024 is broad. Absolutely fine to evaluate other vendors, too. 🙂
The conversations I had with FanDuel at our customer dinner showed that the real world challenge is not choosing the right technologies, but making them easy to use for fast time-to-market and elastic scale with reliable fully managed cloud services.
The motivation for this blog post were my meetings with these joint customers. I will do similar customer dinners in the next months with other Confluent partners like Rockset and StarTree. I can’t wait to hear from joint customers about their benefits of leveraging a specific analytics engine together with a fully managed data streaming platform for product innovation and better customer experiences.
Do you already use Tinybird together with Kafka? Or how do you build scalable real-time APIs on top of your favorite analytics database? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.