
A digital twin is a virtual representation of something else. This can be a physical thing, process or service. This post covers the benefits and IoT architectures of a Digital Twin in various industries and its relation to Apache Kafka, IoT frameworks and Machine Learning. Kafka is often used as central event streaming platform to build a scalable and reliable digital twin and digital thread for real time streaming sensor data.
I already blogged about this topic recently in detail: Apache Kafka as Digital Twin for Open, Scalable, Reliable Industrial IoT (IIoT). Hence that post covers the relation to Event Streaming and why people choose Apache Kafka to build an open, scalable and reliable digital twin infrastructure.
This article here extends the discussion about building an open and scalable digital twin infrastructure:
- Digital Twin vs. Digital Thread
- Relation between Event Streaming, Digital Twin and AI / Machine Learning
- IoT Architectures for a Digital Twin with Apache Kafka and other IoT Platforms
- Extensive slide deck and video recording
Key Take-Aways for Building a Digital Twin
Key Take-Aways:
- A digital twin merges the real world (often physical things) and the digital world
- Apache Kafka enables an open, scalable and reliable infrastructure for a Digital Twin
- Event Streaming complements IoT platforms and other backend applications / databases.
- Machine Learning (ML) and statistical models are used in most digital twin architectures to do simulations, predictions and recommendations.
Digital Thread vs. Digital Twin
The term ‘Digital Twin’ usually means the copy of a single asset. In the real world, many digital twins exist. The term ‘Digital Thread’ spans the entire life cycle of one or more digital twins. Eurostep has a great graphic explaining this:
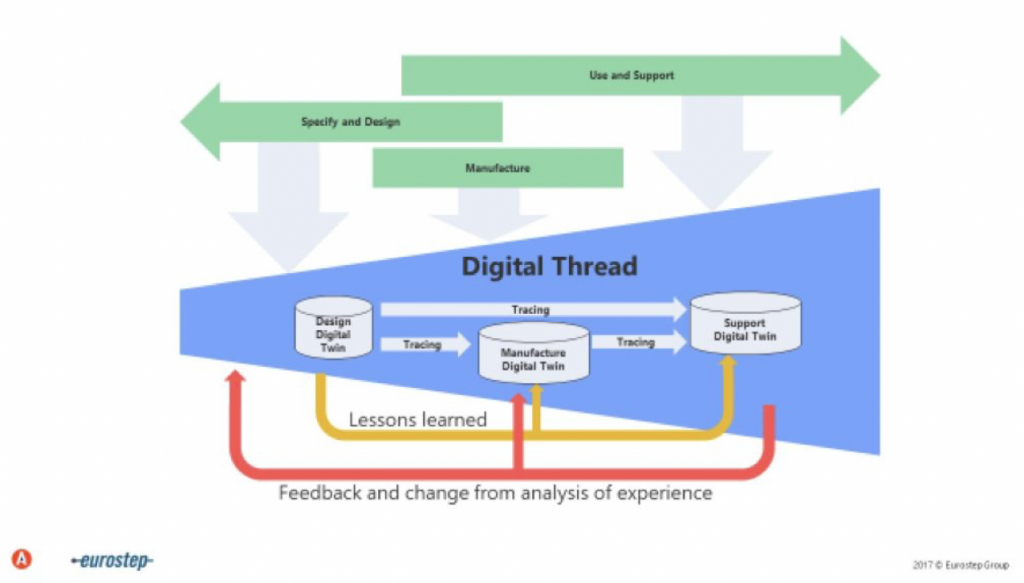
When we talk about ‘Digital Twin’ use cases, we almost always mean a ‘Digital Thread’.
Honestly, the same is true in my material. Both terms overlap, but ‘Digital Twin’ is the “agreed buzzword”. It is important to understand the relation and definition of both terms, though.
Use Cases for Digital Twin and Digital Thread
Use cases exist in many industries. Think about some examples:
- Downtime reduction
- Inventory management
- Fleet management
- What-if simulations
- Operational planning
- Servitization
- Product development
- Healthcare
- Customer experience
The slides and lecture (Youtube video) go into more detail discussing four use cases from different industries:
- Virtual Singapore: A Digital Twin of the Smart City
- Smart Infrastructure: Digital Solutions for Entire Building Lifecycle
- Connected Car Infrastructure
- Twinning the Human Body to Enhance Medical Care
The key message here is that digital twins are not just for automation industry. Instead, many industries and projects can add business value and innovation by building a digital twin.
Relation between Event Streaming, Digital Twin and AI / Machine Learning
Digital Twin respectively Digital Thread and AI / Machine Learning (ML) are complementary concepts. You need to apply ML to do accurate predictions using a digital twin.
Digital Twin and AI
Melda Ulusoy from MathWorks shows in a Youtube video how different Digital Twin implementations leverage statistical methods and analytic models:
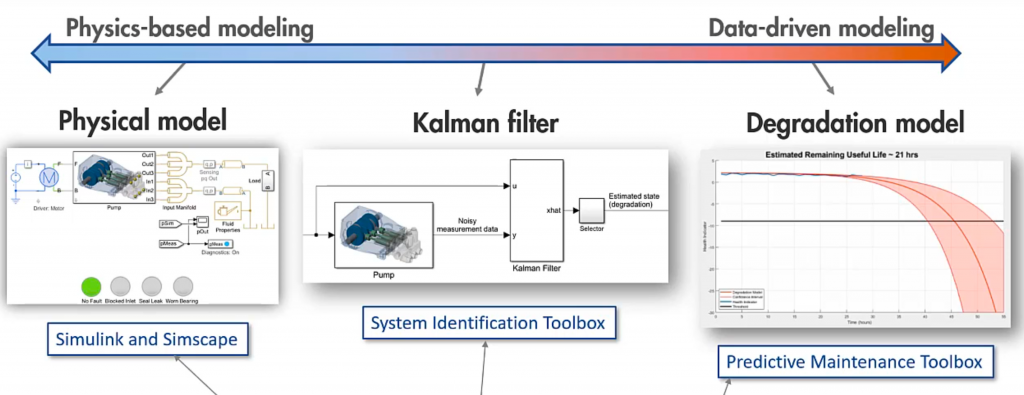
Examples include physics-based modeling to simulate what-if scenarios and data-driven modeling to estimate the RUL (Remaining Useful Life).
Digital Twin and Machine Learning both have the following in common:
- Continuous learning, monitoring and acting
- (Good) data is key for success
- The more data the better
- Real time, scalability and reliability are key requirements
Digital Twin, Machine Learning and Event Streaming with Apache Kafka
Real time, scalability and reliability are key requirements to build a digital twin infrastructure. This makes clear how Event Streaming and Apache Kafka fit into this discussion. I won’t cover what Kafka is or relation between Kafka and Machine Learning in detail here because there are so many other blog posts and videos about it. To recap, let’s take a look at a common Kafka ML architecture providing openness, real time processing, scalability and reliability for model training, deployment / scoring and monitoring:
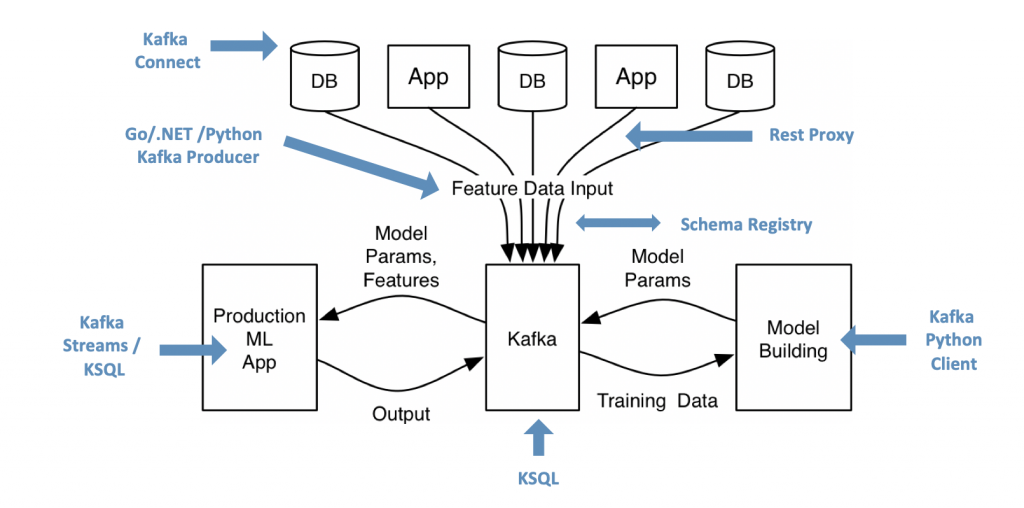
To get more details about Kafka + Machine learning, start with the blog post “How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka” and google for slides, demos, videos and more blog posts.
Characteristics of Digital Twin Technology
The following five characteristics describe common Digital Twin implementations:
- Connectivity
- Physical assets, enterprise software, customers
- Bidirectional communication to ingest, command and control
- Homogenization
- Decoupling and standardization
- Virtualization of information
- Shared with multiple agents, unconstrained by physical location or time
- Lower cost and easier testing, development and predictions
- Reprogrammable and smart
- Adjust and improve characteristics and develop new version of a product
- Digital traces
- Go back in time and analyse historical events to diagnose problems
- Modularity
- Design and customization of products and production modules
- Tweak modules of models and machines
There are plenty of options to implement these characteristics. Let’s take a look at some IoT platforms and how Event Streaming and Apache Kafka fit into the discussion.
IoT Platforms, Frameworks, Standards and Cloud Services
Plenty of IoT solutions are available on the market. IoT Analytics Research talks about over 600 IoT Platforms in 2019. All have their “right to exist” 🙂 In most cases, some of these tools are combined with each other. There is no need or good reason to choose just one single solution.
Let’s take a quick look at some offerings and their trade-offs.
Proprietary IoT Platforms
- Sophisticated integration for related IIoT protocols (like Siemens S7, Modbus, etc.) and standards (like OPC-UA)
- Not a single product (plenty of acquisitions, OEMs and different code bases are typically the foundation)
- Typically very expensive
- Proprietary (just open interfaces)
- Often limited scalability
- Examples: Siemens MindSphere, Cisco Kinetic, GE Digital and Predix
IoT Offerings from Cloud Providers
- Sophisticated tools for IoT management (devices, shadowing, …)
- Good integration with other cloud services (storage, analytics, …)
- Vendor lock-in
- No key focus on hybrid and edge (but some on premises products)
- Limited scalability
- Often high cost (beyond ’hello world’)
- Examples: All major cloud providers have IoT services, including AWS, GCP, Azure and Alibaba
Standards-based / Open Source IoT Platforms
- Open and standards-based (e.g. MQTT)
- Open source / open core business model
- Infrastructure-independent
- Different vendors contribute and compete behind the core technologies (competition means innovation)
- Sometimes less mature or non-existent connectivity (especially to legacy and proprietary protocols)
- Examples: Open source frameworks like Eclipse IoT, Apache PLC4X or Node-RED and standards like MQTT and related vendors like HiveMQ
- Trade-off: Solid offering for one standard (e.g. HiveMQ for MQTT) or diversity but not for mission-critical scale (e.g. Node-RED)
IoT Architectures for a Digital Twin / Digital Thread with Apache Kafka and other IoT Platforms
So, we learned that there are hundreds of IoT solutions available. Consequently, how does Apache Kafka fit into this discussion?
As discussed in the other blog post and in the below slides / video recording: There is huge demand for an open, scalable and reliable infrastructure for Digital Twins. This is where Kafka comes into play to provide a mission-critical event streaming platform for real time messaging, integration and processing.
Kafka and the 5 Characteristics of a Digital Twin
Let’s take a look at a few architectures in the following. Keep in mind the five characteristics of Digital Twins discussed above and its relation to Kafka:
- Connectivity – Kafka Connect provides connectivity as scale in real time to IoT interfaces, big data solutions and cloud services. The Kafka ecosystem is complementary, NOT competitive to other Middleware and IoT Platforms.
- Homogenization – Real decoupling between clients (i.e. producers and consumers) is one of the key strengths of Kafka. Schema management and enforcement leveraging different technologies (JSON Schema, Avro, Profobuf, etc.) enables data awareness and standardization.
- Reprogrammable and smart – Kafka is the de facto standard for microservice architectures for exactly this reason: Separation of concerns and domain-driven design (DDD). Deploy new decoupled applications and do versioning, A/B testing, canarying.
- Digital traces – Kafka is a distributed commit log. Events are appended, stored as long as you want (potentially forever with retention time = -1) and immutable. Seriously, what other technology could be used better to build a digital trace for a digital twin?
- Modularity – The Kafka infrastructure itself is modular and scalable. This includes components like Kafka brokers, Connect, Schema Registry, REST Proxy and client applications in different languages like Java, Scala, Python, Go, .NET, C++ and others. With this modularity, you can easily build the right Digital Twin architecture your your edge, hybrid or global scenarios and also combine the Kafka components with any other IoT solutions.
Each of the following IoT architectures for a Digital Twin has its pros and cons. Depending on your overall enterprise architecture, project situation and many other aspects, pick and choose the right one:
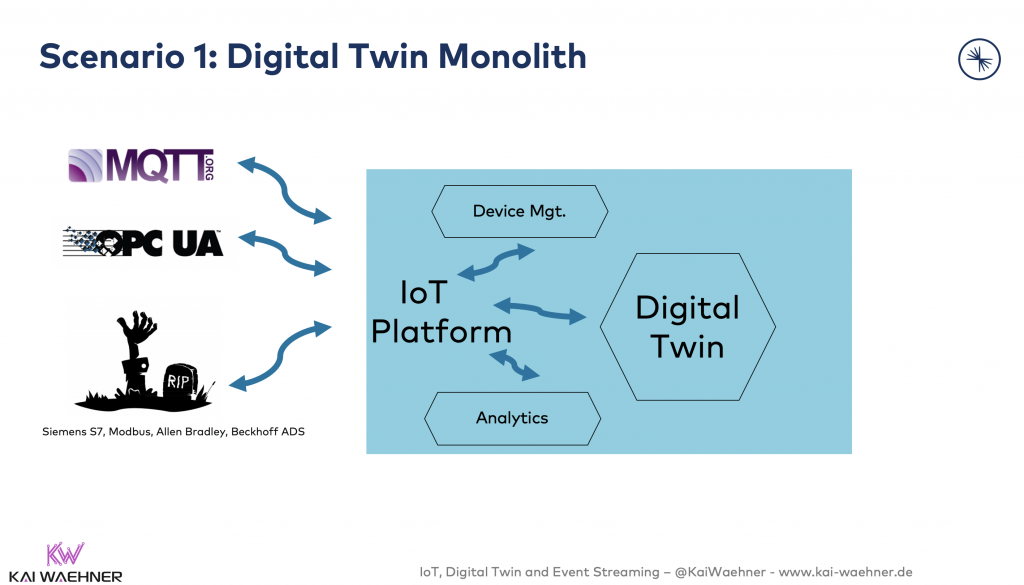
Scenario 1: Digital Twin Monolith
An IoT Platform is good enough for integration and building the digital twin. No need to use another database or integrate with the rest of the enterprise.
Scenario 2: Digital Twin as External Database
An IoT Platform is used for integration with the IoT endpoints. The Digital Twin data is stored in an external database. This can be something like MongoDB, Elastic, InfluxDB or a Cloud Storage. The database could be used just for storage and for additional tasks like processing, dashboards and analytics.
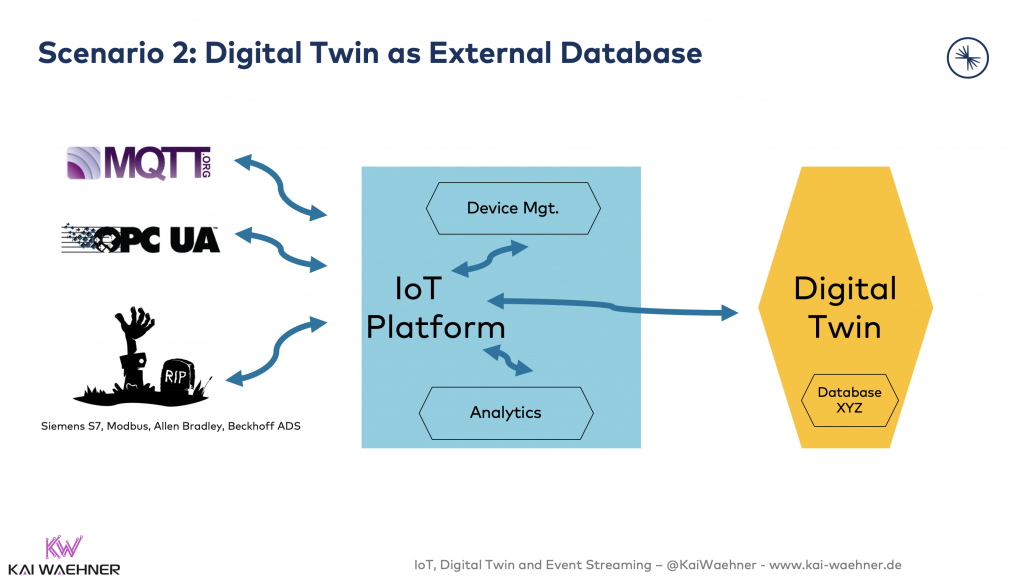
A combination with yet another product is also very common. For instance, a Business Intelligence (BI) tool like Tableau, Qlik or Power BI can use the SQL interface of a database for interactive queries and reports.
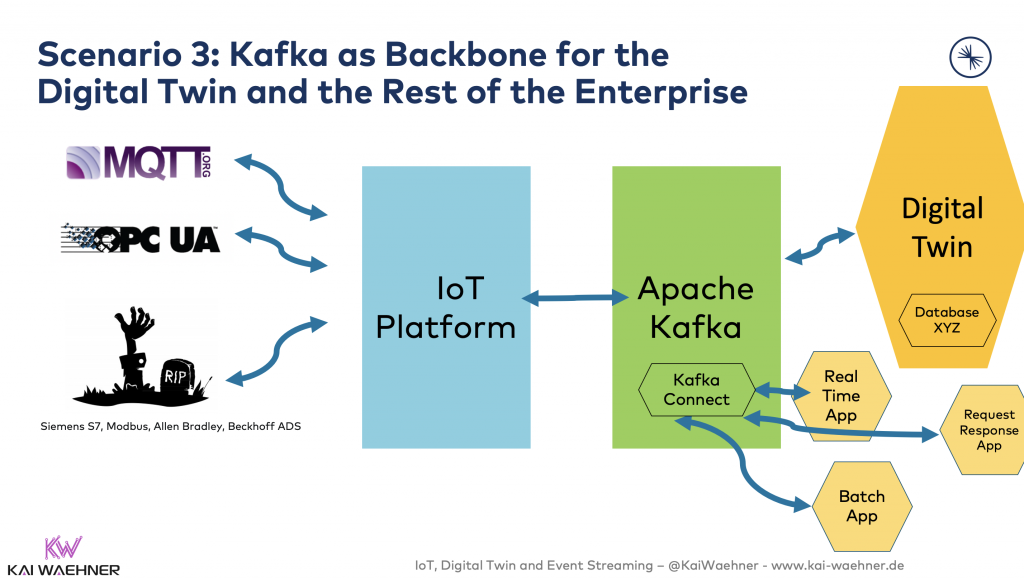
Scenario 3: Kafka as Backbone for the Digital Twin and the Rest of the Enterprise
The IoT Platform is used for integration with the IoT endpoints. Kafka is the central event streaming platform to provide decoupling between the other components. As a result, the central layer is open, scalable and reliable. The database is used for the digital twin (storage, dashboards, analytics). Other applications also consume parts of the data from Kafka (some real time, some batch, some request-response communication).
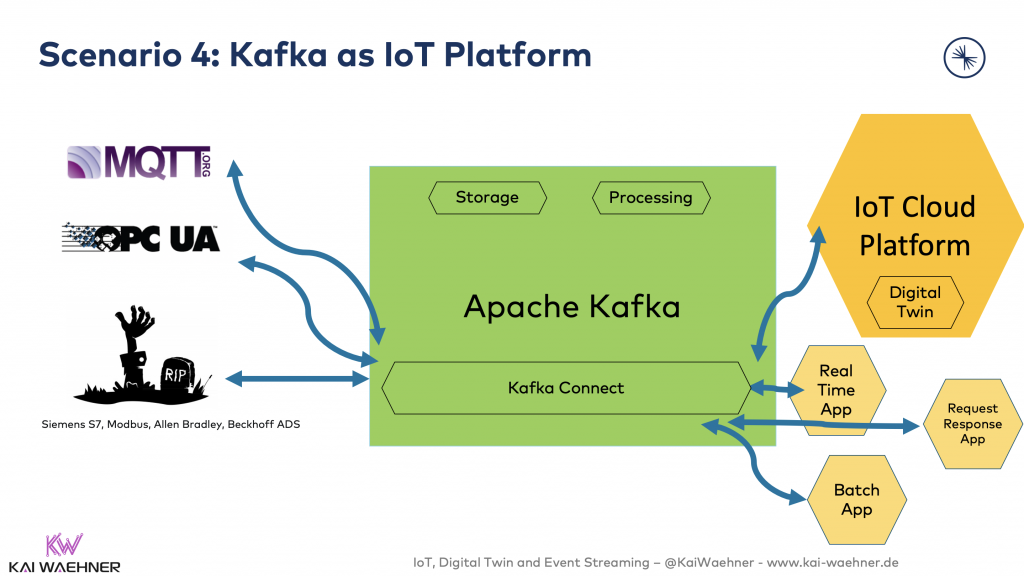
Scenario 4: Kafka as IoT Platform
Kafka is the central event streaming platform to provide a mission-critical real time infrastructure and the integration layer to the IoT endpoints and other applications. The digital twin is implemented in its own solution. In this example, it does not use a database like in the examples above, but a Cloud IoT Service like Azure Digital Twins.
Scenario 5: Kafka as IoT Platform
Kafka is used to implement the digital twin. No other components or databases are involved. Other consumers consume the raw data and the digital twin data.
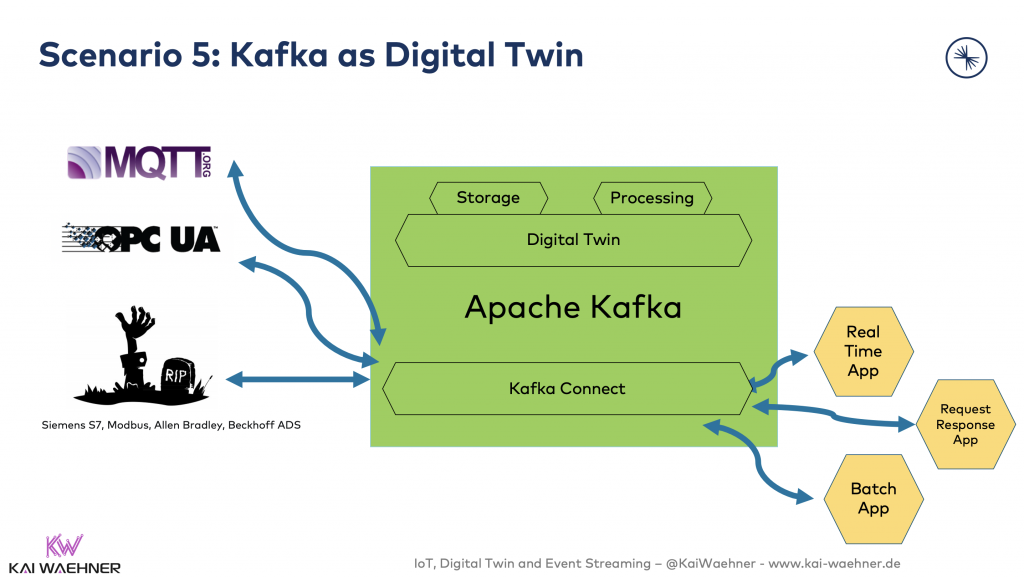
Like all the other architectures, this has pros and cons. The main question in this approach is if Kafka can really replace a database and how you can query the data. First if all, Kafka can be used as database (check out the detailed discussion in the linked blog post), but it will not replace other databases like Oracle, MongoDB or Elasticsearch.
Having said this, I have already seen several deployments of Kafka for Digital Twin infrastructures in automation, aviation, and even banking industry.
Especially with “Tiered Storage” in mind (a Kafka feature currently discussed in a KIP-405 and already implemented by Confluent), Kafka gets more and more powerful for long-term storage.
Slides and Video Recording – IoT Architectures for a Digital Twin with Apache Kafka
This section provides a slide deck and video recording to discuss Digital Twin use cases, technologies and architectures in much more detail.
The agenda for the deck and lecture:
- Digital Twin – Merging the Physical and the Digital World
- Real World Challenges
- IoT Platforms
- Apache Kafka as Event Streaming Solution for IoT
- Spoilt for Choice for a Digital Twin
- Global IoT Architectures
- A Digital Twin for 100000 Connected Cars
Slides
Here is the long version of the slides (with more content than the slides used for the video recording):
https://www.slideshare.net/KaiWaehner/iot-architectures-for-a-digital-twin-with-apache-kafka-iot-platforms-and-machine-learning/KaiWaehner/iot-architectures-for-a-digital-twin-with-apache-kafka-iot-platforms-and-machine-learning
Video Recording
The video recording covers a “lightweight version” of the above slides:
You are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
