
Event streaming with Apache Kafka at the edge is not cutting edge anymore. It is a common approach to providing the same open, flexible, and scalable architecture at the edge as in the cloud or data center. Possible locations for a Kafka edge deployment include retail stores, cell towers, trains, small factories, restaurants, etc. I already discussed the concepts and architectures in detail in the past: “Apache Kafka is the New Black at the Edge” and “Architecture patterns for distributed, hybrid, edge and global Apache Kafka deployments“. This blog post is an add-on focusing on use cases across industries for Kafka at the edge.
To be clear before you read on: Edge is NOT a data center.
And “Edge Kafka” is not simply yet another IoT project using Kafka in a remote location. Edge Kafka is actually an essential component of a streaming nervous system that spans IoT (or OT in Industrial IoT) and non-IoT (traditional data-center / cloud infrastructures).
The post’s focus is scenarios where the Kafka clients AND the Kafka brokers are running on the edge. This enables edge processing, integration, decoupling, low latency, and cost-efficient data processing.
Categories and Architectures for Kafka at the Edge
Some IoT projects are built like “normal Kafka projects”, i.e., built in the (edge) data center or cloud. For instance, bigger factories can provide infrastructure to deploy a reliable Kafka cluster with stable network connectivity to the cloud. Unfortunately, many IoT projects require real edge capabilities.
What’s different at the edge?
-
Offline business continuity is important even if the connection to the central data center or cloud is not available. Disconnected / offline sites do often not require or provide high availability (because it is not worth the efforts): Local pre-processing, real-time analytics with low latency, only online (i.e., connection to the data center or cloud) from time to time or with low bandwidth.
-
Often these projects need to deploy Kafka brokers across hundreds of locations. A single broker is often good enough, without high availability, but for back pressure and local processing. Use cases exist across industries, including retail stores, trains, restaurants, cell towers, small factories, etc.
-
Low-footprint, low-touch, little-or-no-DevOps-required installations of Kafka brokers (not just clients) are mandatory for many of these use-cases. In these cases, no IT experts are available “on-site” to operate Kafka. Hence, using certified OEM hardware is a great option to install and operate Kafka at the edge.
- Many edge use cases are all around sensor and telemetry data. This is not transactional data where every single message counts. An application that processes millions of messages per second is fine with losing a few of the messages as it does not affect the outcome of the calculation.
-
Hybrid and not cloud-only: Consumer IoT (CIoT) always includes the users in their smart home, ride-share, retail store, etc.), Industrial IoT (IIoT) always includes tangible good (cars, food, energy, …)
- Thousands and tens of thousands of connected interfaces: Sensors, machines, mobile devices, etc.
Using one single technical infrastructure enables building edge and hybrid architectures. No need for a ton of different frameworks and products is required. This is a huge benefit from a development, testing, operations, support point of view!
Use Cases Across Industries
Industries for Kafka at the Edge include manufacturing, pharma, carmakers, telecommunications, retailing, energy, restaurants, gaming, healthcare, public sector, aerospace, transportation, and others.
Architectures and use cases include data integration, pre-processing and replication to the cloud, big and small data edge processing, and analytics, disconnected offline scenarios, very low footprint scenarios with hundreds of locations, scenarios without the high-availability, and others.
Scenarios for Edge Computing with Kafka
Various examples for Kafka deployments at the edge exist. Almost all of these use cases are related to several of the above categories and requirements, such as low hardware footprint, disconnected offline processing, hundred of locations, and hybrid architectures.
I have worked with enterprises across industries and the globe on the following scenarios:
- Public Sector: Local administration in each city, smart city projects incl. public transportation, traffic management, integration of various connected car platforms from different carmakers, cybersecurity (including IoT use cases such as capturing and processing camera images)
- Transportation / Logistics / Railway / Aviation: Track&Trace, Kafka in the trains for offline and local processing / storage, traveller information (delayed or canceled flight / train / bus), real-time loyalty platforms (class upgrade, lounge access)
- Manufacturing (Automotive, Aerospace, Semiconductors, Chemical, Food, and others): IoT aftermarket customer services, OEM in machines and vehicles, embedding into standard software such as ERP or MES systems, cybersecurity, a digital twin of devices/machines/production lines/processes, production line monitoring in factories for predictive maintenance/quality control/production efficiency, operations dashboards and line wellness (on-site for the plant manager, and aggregated global KPIs for executive management), track&trace and geofencing on the shop floor
- Energy / Utility / Oil&Gas: Smart home, smart buildings, smart meters, monitoring of remote machines (e.g., for drilling, windmills, mining), pipeline and refinery operations (e.g., predictive failure or anomaly detection)
- Telecommunications / Media: OSS real-time monitoring/problem analysis/metrics reporting/root cause analysis/action response of the network devices and infrastructure (routers, switches, other network devices), BSS customer experience and OTT services (mobile app integration for millions of users), 5G edge (e.g., street sensors)
- Healthcare: Track&trace in the hospital, remote monitoring, machine sensor analytics
- Retailing / Food / Restaurants / Banking: Customer communication, cross-/up-selling, loyalty system, payments in retail stores, perpetual inventory, Point-of-Sale (PoS) integration for (local) payments and (remote) CRM integration, EFTPOS (Electronic funds transfer at point of sale)
A great practical example of edge computing in retailing is fast-food chain Chick-fil-A. They deployed a Kubernetes cluster in each of their 2000 restaurants for real-time analytics at the edge without an internet connection. The hardware is pretty small and provides an Intel quadcore processor with 8 GB RAM and SSD:

Example Architecture: Kafka in Transportation and Logistics
Let’s make this “Kafka at the edge” thing more clear with a specific example. In this case, I use the railway and transportation industry. But this can easily be mapped to your industry and use case.
The following example shows an edge and hybrid solution for railways to improve the customer experience and increase the revenue of the railway company. It leverages offline edge processing for customer communication, replication to the cloud for analytics, and integration with 3rd party interfaces and APIs from partners.
Hybrid Architecture – From Edge to Cloud
Local processing at the edge is happening on the train. But each train also replicates relevant data in real-time to the cloud – if there are internet connectivity and free network resources. If the train is not online, Kafka is handling the backpressure and replicating to the cloud when online again:
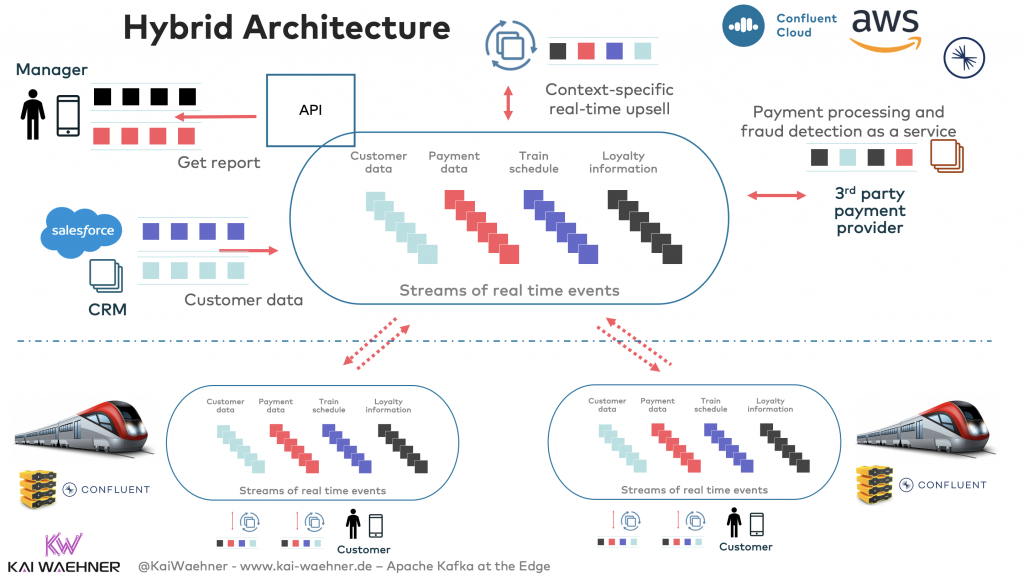
Event Streaming in the Train with Kafka
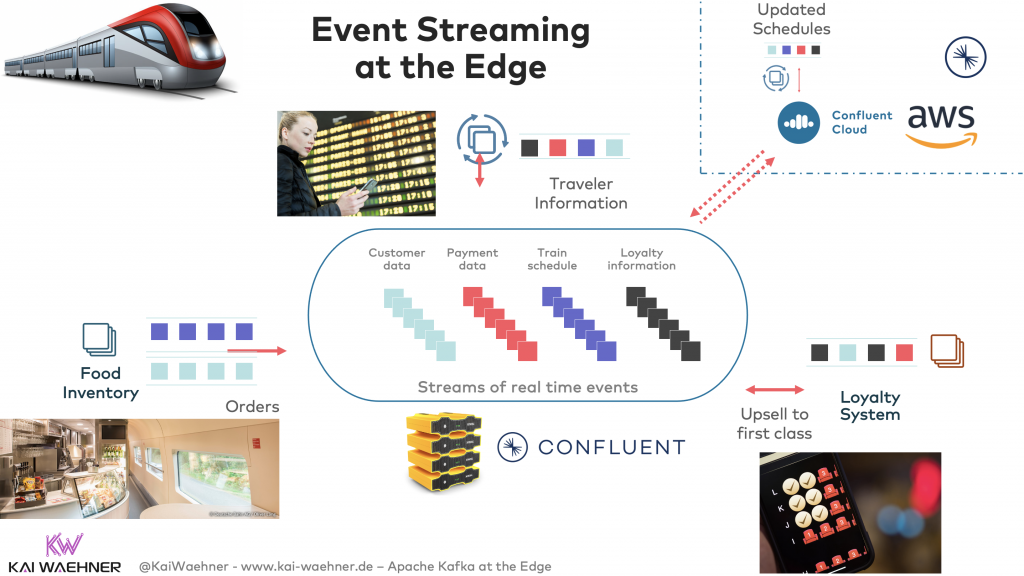
Kafka on the train is NOT just used for real-time messaging and handling backpressure. These are already great reasons for using Kafka at the edge. Still, the even bigger value is created when Kafka is also used for data integration (restaurant, traveler information, loyalty system, etc.) and data processing (up-/cross-selling, real-time delay information, etc.) at the edge. This way, only one single platform is required to solve all the different problems:
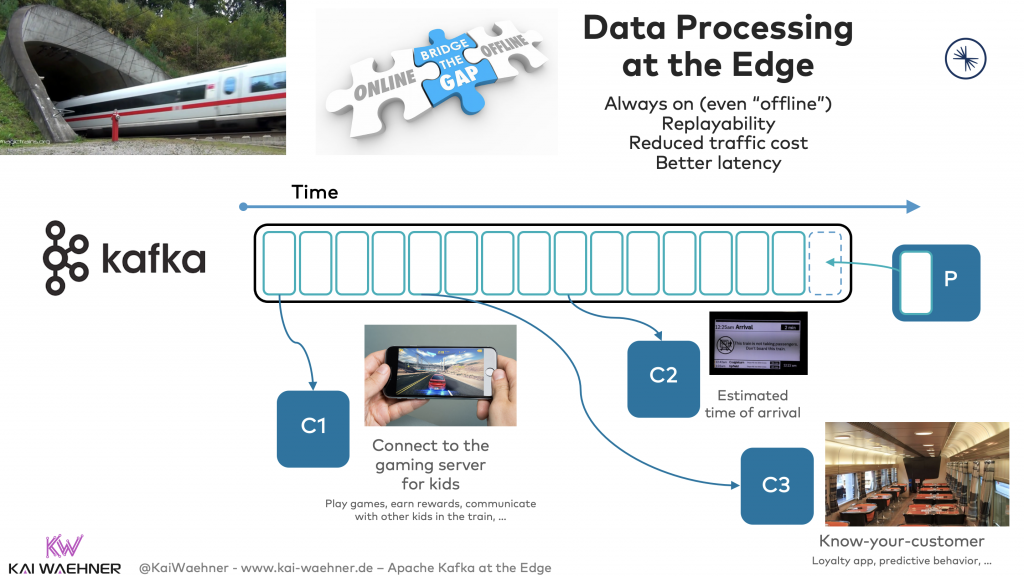
Kafka for Disconnected / Offline Scenarios
Trains (and many other edge locations) are offline regularly. For instance, a train drives through a tunnel or reaches an area with no cell connectivity. Local processing is still possible. Business continuity is the key to improve customer experience and increase sales processes – even if the train disconnected from the internet. Passengers can still use the mobile app to see traveler information, buy food in the restaurant, or watch movies stores on the train’s local server. As soon as the train has internet connectivity again, the purchases from passengers are transferred to the loyalty system in the cloud, the latest delay information is consumed from the cloud and stored on the edge Kafka broker in the train, etc. etc. etc.:
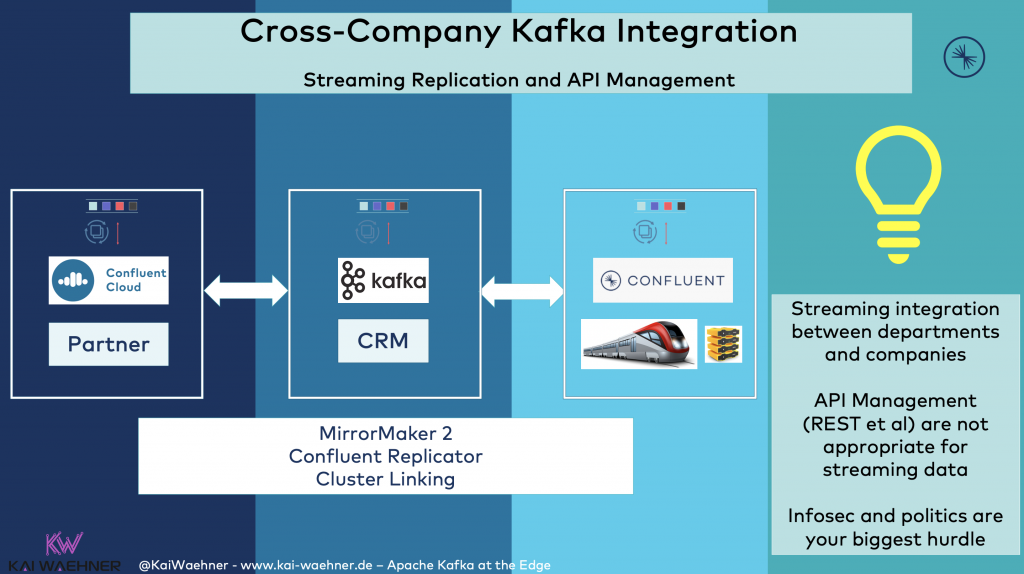
Cross-Company Kafka Integration
Data processing does not stop with the hybrid integration between the edge (train) and cloud (CRM, loyalty system, etc.). Different divisions or partner companies need to integrate, too. Instead of using non-scalable, synchronous REST API calls / API Management for partner integration, streaming replication with Kafka-native technologies is a much better, scalable approach:
I hope this story about Kafka at the edge helped you better understand how you can leverage event streaming in your industry and use cases to build an end-to-end streaming infrastructure from edge to cloud.
Infrastructure and Hardware Requirement for Deployment of Kafka at the Edge
Finally, it is important to discuss how to deploy Kafka at the edge. To be clear: Kafka still needs some computing power.
Obviously, this depends on many factors: The hardware vendors and infrastructure you are working with, specific SLAs and HA requirements, and so on. The good news is that Kafka can be deployed in many infrastructures, including bare metal, VMs, containers, Kubernetes, etc. The other good news is that new hardware for computing resources (even for the “edge”) typically has 4, 8, or even 16GB RAM because this is the smallest chip vendors produce these days (for these environments such as small factories, retail stores, etc).
Minimum hardware requirements for running a very small footprint Kafka are a single-core processor and a few 100MB RAM. This already allows decent edge processing with 100+Mb/sec throughput on a single Kafka node (with replication factor = 1). However, real values depend on the number of partitions, message size, network speed, and other characteristics. Don’t expect the same performance and scalability as in the data center or cloud!
Thus, you can deploy a Kafka broker on a Raspberry Pi, but not on some small embedded device! The latter is where the Kafka clients can run.
Check out the “Infrastructure Checklist for Apache Kafka at the Edge” if you plan to go that direction!
“The Confluent Way” to Deploy Kafka at the Edge
From a technical perspective, deployment of Kafka at the edge is the same as in a data center or cloud. However, the environment and requirements are a little bit different as we learned above. Some additional features definitely help with deploying and operating Kafka at the edge.
I work for Confluent. Hence, I provide you “The Confluent Way” of deploying Kafka at the edge in your future projects, including innovative, differentiating features:
- Confluent Server includes the Kafka Broker and various enhancements such as self-balancing clusters, Tiered Storage, embedded REST API, server-side schema validation, and much more. It can be deployed as a single node (very lightweight, but no high availability) or cluster (for mission-critical workloads that require high availability at the edge).
- In 2020, ZooKeeper is still required as an additional component. However, ZooKeeper removal is coming in 2021! Many Confluent engineers work full-time on removing the (ugly) Zookeeper dependency from the Kafka project, which means it will be possible to run a standalone, single process edge solution powered by Kafka. The whole Kafka community is looking forward to this architectural change. You can already run Kafka at the edge today, of course. It works well with ZooKeeper, too.
- Cluster Linking allows all these small Kafka edge sites to connect to a bigger Kafka cluster in a data center or cloud using the Kafka protocol. No need to use additional tools and infrastructure such as Confluent Replicator or MirrorMaker. This significantly reduces development efforts and infrastructure costs.
- Monitoring and Proactive Support with Confluent’s toolset. For instance, one Control Center can monitor several different (remote) Kafka clusters. Confluent Telemetry Reporter collects data from edge sites. Monitoring includes the technical infrastructure, but also for applications and end-to-end integration.
- Kubernetes is becoming the edge orchestration platform of choice for many edge deployments. For instance, using the MicroK8s Kubernetes distribution. Confluent Operator (Custom Resource Definitions, CRD) provides the capabilities to provision and operate single-broker or cluster deployments at the edge. This includes rolling upgrades, security automation, and much more. Confluent Operator is battle-tested in Confluent Cloud and large deployments of Confluent Platform in data centers, already. Chick-fil-A has a great success story about running Kubernetes in their 2000+ fast food stores to provide disconnected edge services and low latency. Kubernetes is clearly optional. Only use it when it really adds value, and not too complex and resource-hungry. Many edge deployments will probably disqualify Kubernetes as too heavyweight and complex.
- Data Integration and data processing is key at the edge. Confluent provides connectors to legacy and modern systems (including PLC4X for PLC, OPC-UA, and IIoT integration, database CDC connectors, MQ and MQTT integration, Data Diode connectors for uni-directional UDP networks in high security or dirty environments, cloud connectors, and much more). Kafka Streams and ksqlDB allow lightweight but powerful stream processing without the need for yet another technology.
- Lightweight edge clients (e.g., embedded devices) leverage the C or C++ client APIs for Kafka and the REST Proxy to communicate from any programming language via HTTP(S). This is important for many low-power edge devices with limited computing power where Java or similar “resource-hungry technologies” cannot be deployed.
- Optionally, certified, pre-configured OEM hardware is available. You put the box at the edge, connect it to LAN or Wifi, and use it. That’s it. Management and monitoring of the infrastructure occur via the remote software of the hardware vendor. “Feasible video processing on Hivecell” demonstrates edge analytics with a Kafka cluster, a Kafka Streams application, and embedded machine learning models for image recognition in real-time.
Kafka at the Edge (and in Hybrid Architectures) is the New Black
Kafka is a great solution for the edge. It enables deploying the same open, scalable, and reliable technology at the edge, data center, and the cloud. This is relevant across industries. Kafka is used in more and more places where nobody has seen it before. Edge sites include retail stores, restaurants, cell towers, trains, and many others. I hope the various use cases and architectures inspired you a little bit.
What are your experiences at the edge? What are your use cases? Did you or do you plan to use Apache Kafka and its ecosystem? What is your strategy? Let’s connect on LinkedIn and discuss it!
