IT modernization and innovative new technologies change the healthcare industry significantly. This blog series explores how data streaming with Apache Kafka enables real-time data processing and business process automation. Real-world examples show how traditional enterprises and startups increase efficiency, reduce cost, and improve the human experience across the healthcare value chain, including pharma, insurance, providers, retail, and manufacturing. This is part five: Machine Learning and Data Science. Examples include Recursion and Humana.

Blog Series – Kafka in Healthcare
Many healthcare companies leverage Kafka today. Use cases exist in every domain across the healthcare value chain. Most companies deploy data streaming in different business domains. Use cases often overlap. I tried to categorize a few real-world deployments into different technical scenarios and added a few real-world examples:
- Overview – Data Streaming Use Cases and Architectures for Healthcare (including Slide Deck)
- Legacy Modernization and Hybrid Cloud (Optum / UnitedHealth Group, Centene, Bayer)
- Streaming ETL (Bayer, Babylon Health)
- Real-time Analytics (Cerner, Celmatix, CDC/Centers for Disease Control and Prevention)
- THIS POST: Machine Learning and Data Science (Recursion, Humana)
- Open API and Omnichannel (Care.com, Invitae)
Stay tuned for a dedicated blog post for each of these topics as part of this blog series. I will link the blogs here as soon as they are available (in the next few weeks). Subscribe to my newsletter to get an email after each publication (no spam or ads).
Machine Learning and Data Science with Data Streaming using Apache Kafka
The relationship between Apache Kafka and machine learning (ML) is getting more and more traction for data engineering at scale and robust model deployment with low latency.
The Kafka ecosystem helps in different ML use cases for model training, model serving, and model monitoring. The core of most ML projects requires reliable and scalable data engineering pipelines across
- different technologies
- communication paradigms (REST, gRPC, data streaming)
- programming languages (like Python for the data scientist or Java/Go/C++ for the production engineer)
- APIs
- commercial products
- SaaS offerings
Here is an architecture diagram that shows how Kafka helps in data science projects:
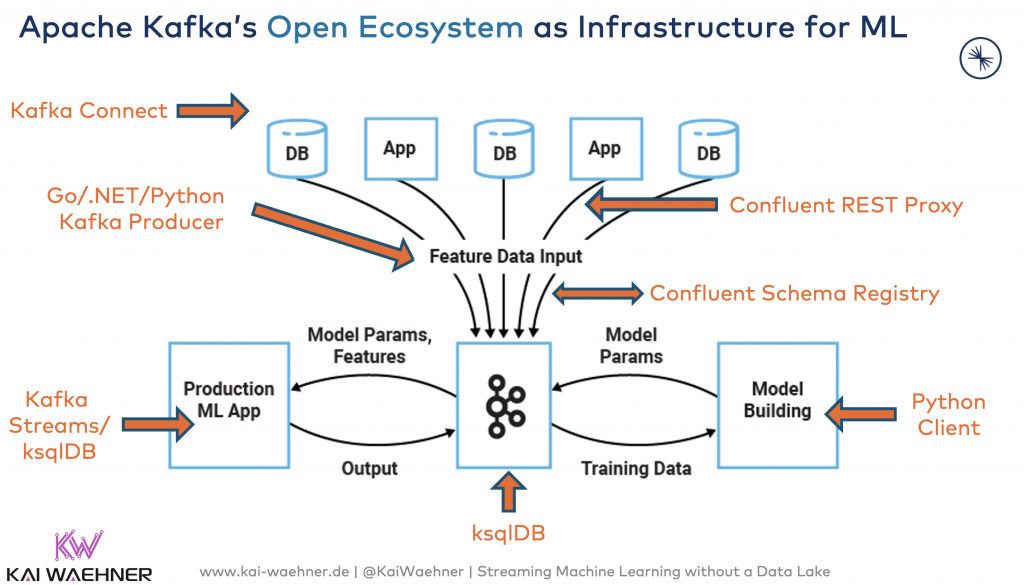
The beauty of Kafka is that it combines real-time data processing with extreme scalability and true decoupling between systems.
Tiered Storage adds cost-efficient storage of big data sets and replayability with guaranteed ordering.
I’ve written about this relationship between Kafka and Machine Learning in various articles:
- How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka
- Using Apache Kafka to Drive Cutting-Edge Machine Learning
- Model Deployment with Apache Kafka
- Machine Learning with Apache Kafka, Tiered Storage, TensorFlow
- Streaming Model Serving with Kafka and Seldon
Let’s look at a few real-world deployments for Apache Kafka and Machine Learning in the healthcare sector.
Humana – Real-Time Interoperability at the Point of Care
Humana Inc. is a for-profit American health insurance company. They leverage data streaming with Apache Kafka to improve real-time interoperability at the point of care.
The interoperability platform to transition from an insurance company with elements of health to truly a health company with elements of insurance.
Their core principles include:
- Consumer-centric
- Health plan agnostic
- Provider agnostic
- Cloud resilient
- Elastic scale
- Event-driven and real-time
A critical characteristic is inter-organization data sharing (known as “data exchange/data sharing”).
Humana’s use cases include
- real-time updates of health information, for instance
- connecting health care providers to pharmacies
- reducing pre-authorizations from 20-30 minutes to 1 minute
- real-time home healthcare assistant communication
The Humana interoperability platform combines data streaming (= the Kafka ecosystem) with artificial intelligence and machine learning (= IBM Watson) to correlate data, train analytic models, and act on new events in real-time.
Humana’s data journey is described in this diagram from their Kafka Summit talk:
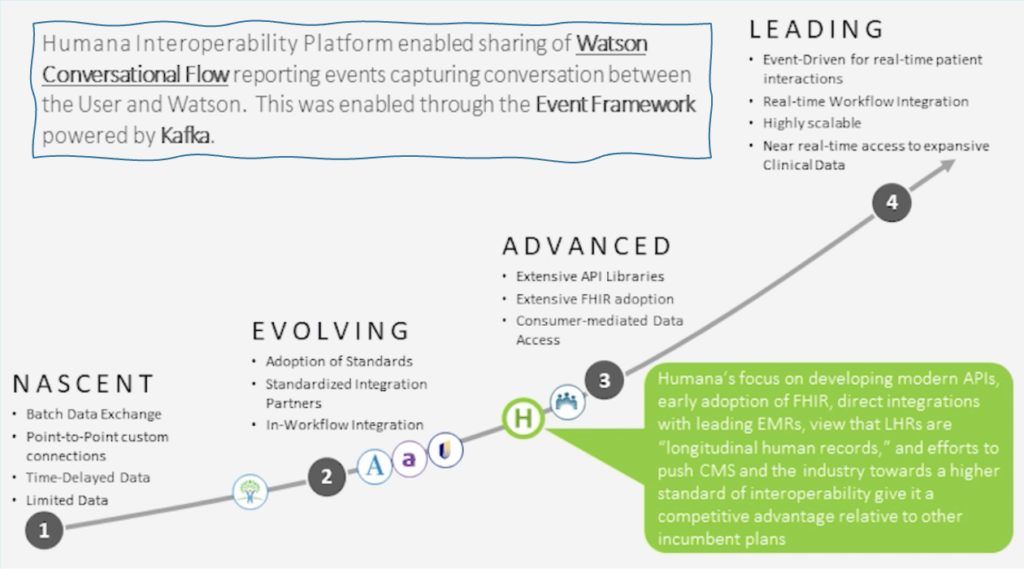
Learn more details about Humana’s use cases and architecture in the keynote of another Kafka Summit session.
Recursion – Industrial Revolution of Drug Discovery with Kafka and Deep Learning
Recursion is a clinical-stage biotechnology company that built the “industrial revolution of drug discovery“. They decode biology by integrating technological innovations across biology, chemistry, automation, machine learning, and engineering to industrialize drug discovery.

Kafka-powered data streaming speeds up the pharma processes significantly. Recursion has already made significant strides in accelerating drug discovery, with over 30 disease models in discovery, another nine in preclinical development, and two in clinical trials.
With serverless Confluent Cloud and the new data streaming approach, the company has built a platform that makes it possible to screen much larger experiments with thousands of compounds against hundreds of disease models in minutes and less expensive than alternative discovery approaches.
From a technical perspective, Recursion finds drug treatments by processing biological images. A massively parallel system combines experimental biology, artificial intelligence, automation, and real-time data streaming:
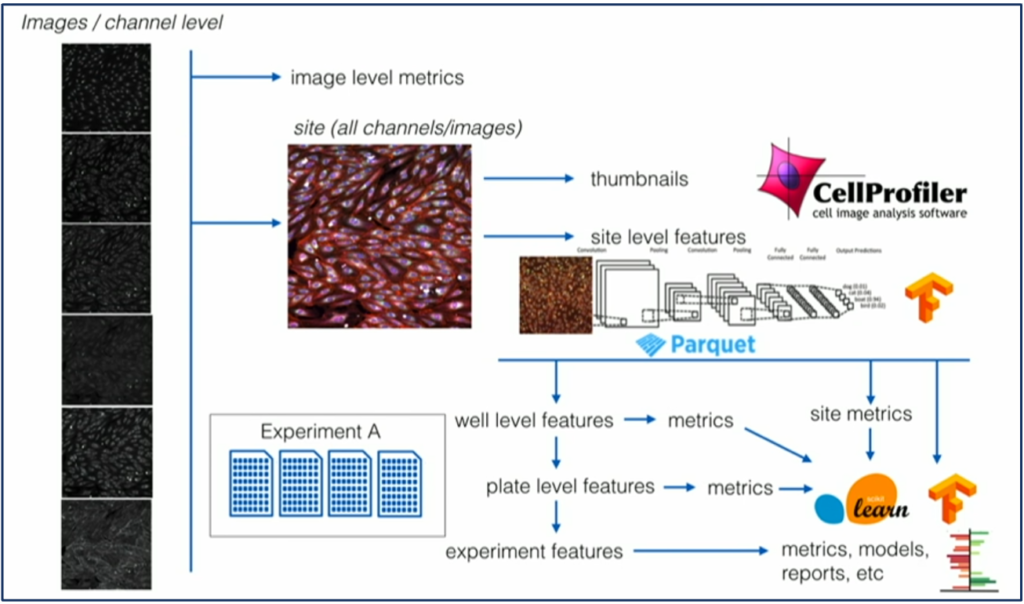
Recursion went from ‘drug discovery in manual and slow, not scalable, bursty BATCH MODE’ to ‘drug discovery in automated, scalable, reliable REAL-TIME MODE’.
Recursion leverages Dagger, an event-driven workflow and orchestration library for Kafka Streams that enables engineers to orchestrate services by defining workloads as high-level data structures. Dagger combines Kafka topics and schemas with external tasks for actions completed outside of the Kafka Streams applications.
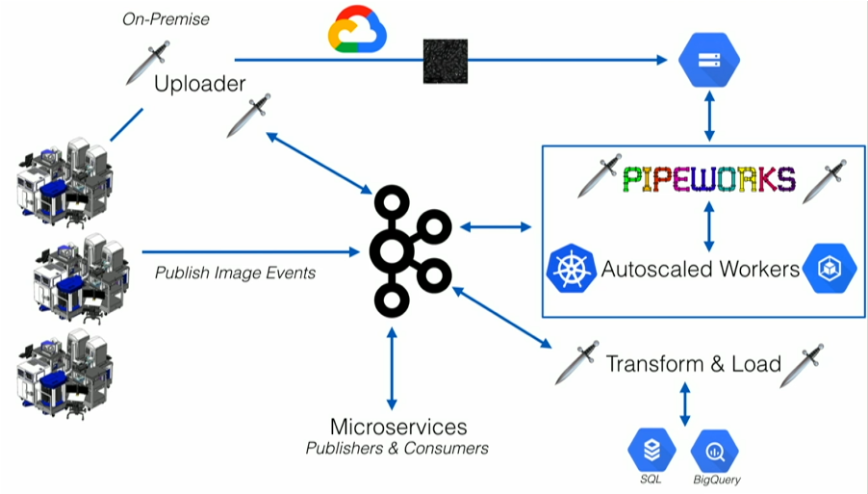
In the meantime, Recursion did not just migrate from manual batch workloads to Kafka but also migrated to serverless Kafka, leveraging Confluent Cloud to focus its resources on business problems instead of infrastructure operations.
Machine Learning and Data Science with Kafka for Intelligent Healthcare Applications
Think about IoT sensor analytics, cybersecurity, patient communication, insurance, research, and many other domains. Real-time data beats slow data in the healthcare supply chain almost everywhere.
This blog post explored the capabilities of the Apache Kafka ecosystem for machine learning infrastructures. Real-world deployments from Humana and Recursion showed how enterprises successfully deploy Kafka together with Machine Learning frameworks like TensorFlow for use cases.
How do you leverage data streaming with Apache Kafka in the healthcare industry? What architecture does your platform use? Which products do you combine with data streaming? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.





