
IT modernization and innovative new technologies change the healthcare industry significantly. This blog series explores how data streaming with Apache Kafka enables real-time data processing and business process automation. Real-world examples show how traditional enterprises and startups increase efficiency, reduce cost, and improve the human experience across the healthcare value chain, including pharma, insurance, providers, retail, and manufacturing. This is part three: Streaming ETL. Examples include Babylon Health and Bayer.

Blog Series – Kafka in Healthcare
Many healthcare companies leverage Kafka today. Use cases exist in every domain across the healthcare value chain. Most companies deploy data streaming in different business domains. Use cases often overlap. I tried to categorize a few real-world deployments into different technical scenarios and added a few real-world examples:
- Overview – Data Streaming Use Cases and Architectures for Healthcare (including Slide Deck)
- Legacy Modernization and Hybrid Cloud (Optum / UnitedHealth Group, Centene, Bayer)
- THIS POST: Streaming ETL (Bayer, Babylon Health)
- Real-time Analytics (Cerner, Celmatix, CDC/Centers for Disease Control and Prevention)
- Machine Learning and Data Science (Recursion, Humana)
- Open API and Omnichannel (Care.com, Invitae)
Stay tuned for a dedicated blog post for each of these topics as part of this blog series. I will link the blogs here as soon as they are available (in the next few weeks). Subscribe to my newsletter to get an email after each publication (no spam or ads).
Streaming ETL with Apache Kafka
Streaming ETL is similar to concepts you might know from traditional ETL tools. I have already explored how data streaming with Kafka differs from data integration tools and iPaaS cloud services. The critical difference is that you leverage a single platform for data integration and processing at scale in real-time. There is no need to combine several platforms to achieve this. The result is a Kappa architecture that enables real-time but also batch workloads with a single integration architecture.
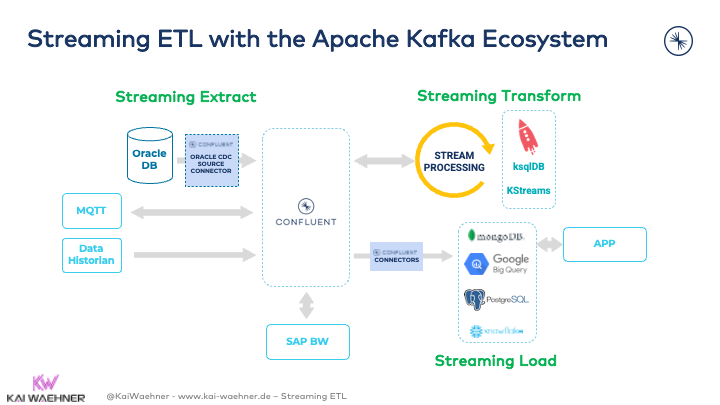
Streaming ETL with Kafka combines different components and features:
- Kafka Connect as Kafka-native integration framework
- Kafka Connect source and sink connectors to consume and produce data from/to any other database, application, or API
- Single Message Transform (SMT) – an optional Kafka Connect feature – to process (filter, change, remove, etc.) incoming or outgoing messages within the connector deployment
- Kafka Streams or ksqlDB for continuous data processing in real-time at scale for stateless or stateful ETL jobs
- Data governance via schema management, enforcement and versioning using the Schema Registry
- Security and access control using features like role-based access control, audit logs, and end-to-end encryption
In the cloud, you can leverage a serverless Kafka offering for the whole Streaming ETL pipeline. Confluent Cloud fully manages Kafka’s end-to-end infrastructure, including connectors, ksqlDB workloads, data governance, and security.
One last general note: Don’t Design for Data at Rest to Reverse it! Learn more here: “When to Use Reverse ETL and when it is an Anti-Pattern“. Instead, use real-time Streaming ETL for Data in Motion and the Kappa architecture from scratch.
Let’s look at a few real-world deployments in the healthcare sector.
Babylon Health – PII and GDRP compliant Security
Babylon Health is a digital-first health service provider and value-based care company that combines an artificial intelligence-powered platform with virtual clinical operations for patients. Patients are connected with health care professionals through its web and mobile application.
Babylon’s mission is to put an accessible and affordable health service in the hands of every person on earth. For that mission, Babylon built an agile microservice architecture with the Kafka ecosystem:
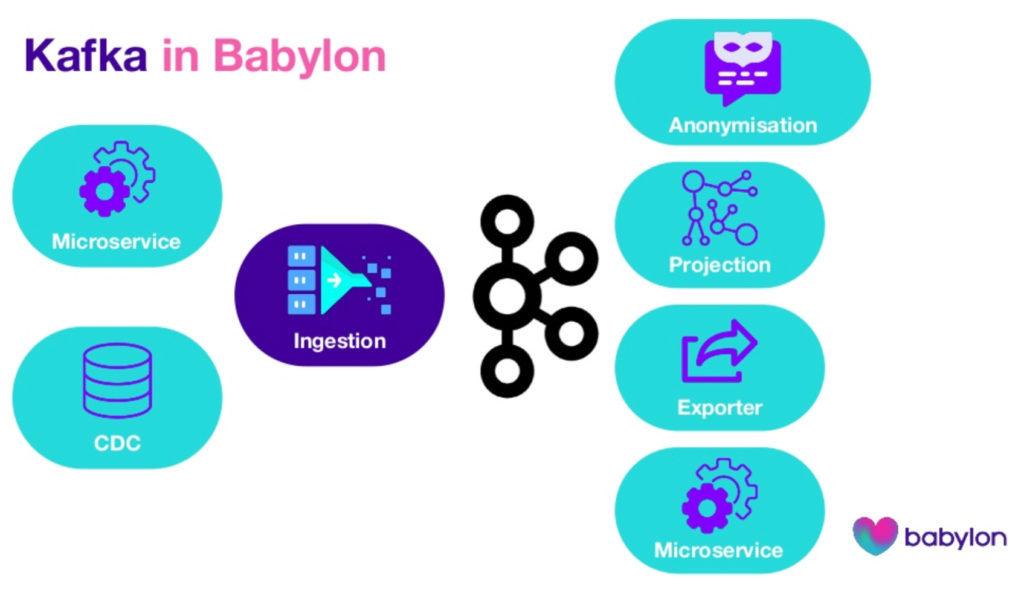
Here are the “wonders of working” in Healthcare for Babylon (= reasons to choose Kafka):
- Real-time data processing
- Replayability of historical information
- Order matters and is ensured with guaranteed ordering
- GDPR and data ownership for PII compliant security
- Data governance via the schema registry to provide true decoupling and access via many programming languages like Java, Python, and Ruby
Bayer – Data Integration and Processing in R&D
Bayer AG is a German multinational pharmaceutical and life sciences company and one of the largest pharmaceutical companies in the world. They leverage Kafka in various use cases and business domains.
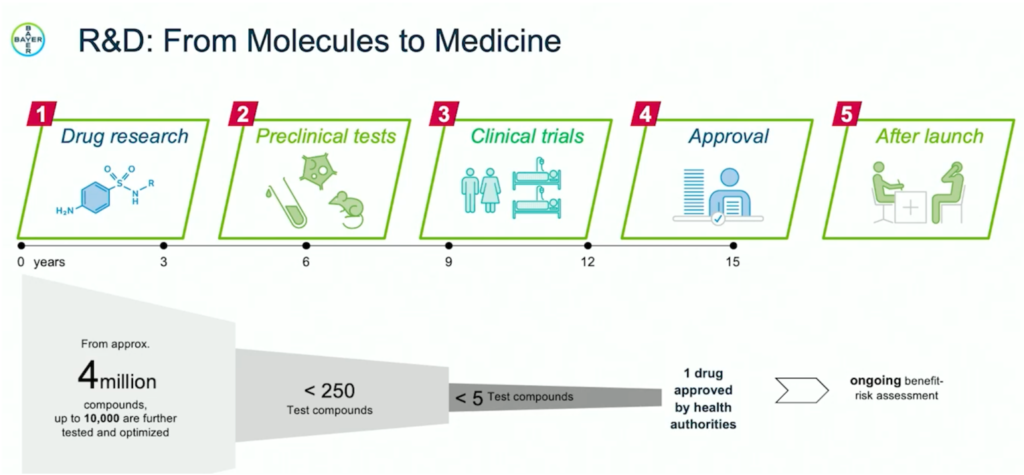
The following scenario is from the research and development department of the pharma business unit. Their focus areas are cardiovascular diseases, oncology, and women’s health. The division employs over 7,500 R&D people and expenses over 2.75 billion euros for R&D.
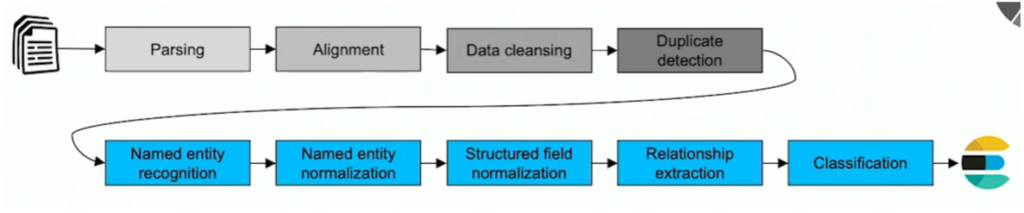
The use case Bayer presented at a recent Kafka Summit is about analyzing clinical trials, patents, reports, news, and literature leveraging the Kafka ecosystem. The R&D team processes 250 Million documents from 30+ individual data sources. The data includes 7 TB of raw text-rich data with daily updates, additions, and deletions. Algorithms and data evolve. Bayer needs to completely reprocess the data regularly. Various document streams with different formats and schemas flow through several text processing and enrichment steps.
Scalable, reliable Kafka pipelines with Kafka Streams (Java) and Faust (Python) replaced custom, error-prone, non-scalable scripts. Schemas are used as the data interface to ensure data governance. Avro is the first-class citizen data format to enable compression and better throughput.
The true decoupling of Kafka in conjunction with the Schema Registry guarantees interoperability among different components and technologies (java, python, commercial tools, open-source, scientific, proprietary).
Streaming ETL with Kafka for Real-Time Data Integration at any Scale
Think about IoT sensor analytics, cybersecurity, patient communication, insurance, research, and many other domains. Real-time data beats slow data in the healthcare supply chain almost everywhere.
This blog post explored the capabilities of the Apache Kafka Ecosystem for Streaming ETL. Real-world deployments from Babylon Health and Bayer showed how enterprises successfully deploy Kafka for different enterprise architecture use cases.
How do you leverage data streaming with Apache Kafka in the healthcare industry? What architecture does your platform use? Which products do you combine with data streaming? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
