
A Message broker has very different characteristics and use cases than a data streaming platform like Apache Kafka. A business process requires more than just sending data in real-time from a data source to a data sink. Data integration, processing, governance, and security must be reliable and scalable end-to-end across the business process. This blog post explores the capabilities of message brokers, the relation to the JMS standard, trade-offs compared to data streaming with Apache Kafka, and typical integration and migration scenarios. A case study explores the migration from IBM MQ to Apache Kafka. The last section contains a complete slide deck that covers all these aspects in more detail.

Message Broker vs. Apache Kafka -> Apples and Oranges
TL;DR: Message brokers send data from a data source to one or more data sinks in real time. Data streaming provides the same capability but adds long-term storage, integration, and processing capabilities.
Most message brokers implement the JMS (Java Message Service) standard. Most commercial messaging solutions add additional proprietary features. Data streaming has no standard. But the de facto standard is Apache Kafka.
I already did a detailed comparison of (JMS-based) message brokers and Apache Kafka based on the following characteristics:
- Message broker vs. data streaming platform
- API Specification vs. open-source protocol implementation
- Transactional vs. analytical workloads
- Storage for durability vs. true decoupling
- Push vs. pull message consumption
- Simple vs. powerful and complex API
- Server-side vs. client-side data-processing
- Complex operations vs. serverless cloud
- Java/JVM vs. any programming language
- Single deployment vs. multi-region
I will not explore the trade-offs again. Just check out the other blog post. I also already covered implementing event-driven design patterns from messaging solutions with data streaming and Apache Kafka. Check out how to use a dead letter queue (DLQ) with data streaming or the request-response concept with Kafka (and understand when and why NOT to use it).
The below slide deck covers all these topics in much more detail. Before that, I want to highlight related themes in its sections:
- Case study: How the retailer Advance Auto Parts modernized its enterprise architecture
- Integration between a message broker (like IBM MQ) and Apache Kafka
- Mainframe deployment options for data streaming
- Migration from a message broker to data streaming
Case Study: IT Modernisation from IBM MQ and Mainframe to Kafka and Confluent Cloud
Advance Auto Parts is North America’s largest automotive aftermarket parts provider. The retailer ensures the right parts from its 30,000 vendors are in stock for professional installers and do-it-yourself customers across all of its 5,200 stores.
Advance Auto Parts implement data streaming and stream processing use cases that deliver immediate business value, including:
- Real-time invoicing for a large commercial supplier
- Dynamic pricing updates by store and location
- Modernization of the company’s business-critical merchandising system
Here are a few details about Advance Auto Parts’ success story:
- Started small with Confluent Cloud and scaled as needed while minimizing administrative overhead with a fully managed, cloud-native Kafka service
- Integrated data from more than a dozen different sources, including IBM Mainframe and IBM MQ through Kafka to the company’s ERP supply chain platform
- Used stream processing and ksqlDB to filter events for specific customers and to enrich product data
- Linked Kafka topics with Amazon S3 and Snowflake using Confluent Cloud sink connectors
- Set the stage for continued improvements in operational efficiency and customer experience for years to come
Integration Architecture BEFORE and AFTER at Advance Auto Parts
BEFORE – Legacy infrastructure and architecture, including IBM MQ and IBM AS/400 Mainframe, did not meet real-time performance requirements:
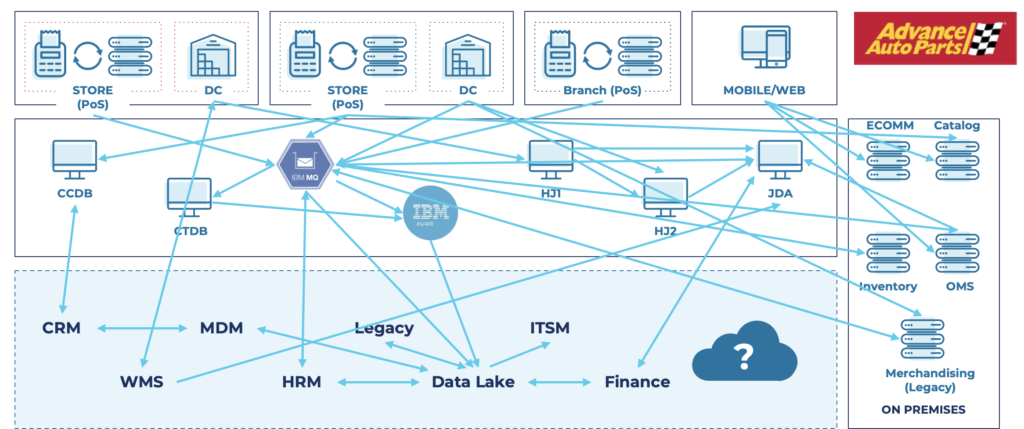
AFTER – Future-proof data architecture, including Kafka-powered Confluent Cloud, for real-time invoicing and dynamic pricing:
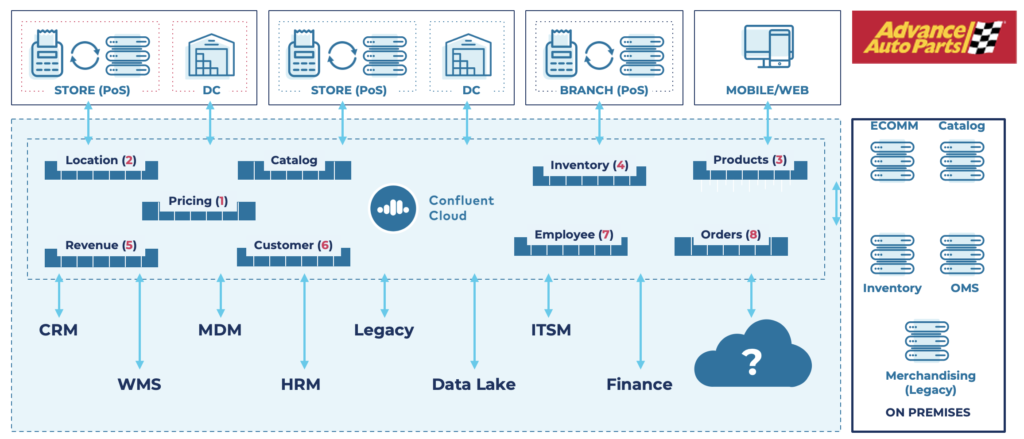
Integration between a message broker and Apache Kafka
The most common scenario for message brokers and data streaming is a combination of both. These two technologies are built for very different purposes.
Point-to-point application integration (at a limited scale) is easy to build with a message broker. Systems are tightly coupled and combine messaging with web services and databases. This is how most spaghetti architectures originated.
A data streaming platform usually has various data sources (including message brokers) and independent downstream consumers. Hence, data streaming is a much more strategic platform in enterprise architecture. It enables a clean separation of concerns and decentralized decoupling between domains and business units.
Integrating messaging solutions like IBM MQ, TIBCO EMS, RabbitMQ, ActiveMQ, or Solace and data streaming platforms around Apache Kafka leverage Kafka Connect as integration middleware. Connectors come from data streaming vendors like Confluent. Or from the messaging provider. For instance, IBM also provides Kafka connectors for IBM MQ.
The integration is straightforward and enables uni- or bi-directional communication. An enormous benefit of using Kafka Connect instead of another ETL tool or ESB is that you don’t need another middleware for the integration. If you need to understand the fundamental differences between MQ, ETL, ESB, iPaaS, and Data Streaming, check out this comparison of traditional middleware and Apache Kafka.
Mainframe integration with IBM MQ and Kafka Connect
The mainframe is a unique infrastructure using the IBM MQ message broker. Cost, connectivity, and security look different from other traditional enterprise components.
The most common approaches for the integration between mainframe and data streaming are Change Data Capture (CDC) from the IBM DB2 database (e.g., via IBM IIDR), direct VSAM file integration (e.g., via Precisely), or connectivity via IBM MQ.
Publishing messages from IBM MQ to Kafka improves data reliability, accessibility, and offloading to cloud services. This integration requires no changes to the existing mainframe applications. But it dramatically reduces MQ-related MIPS to move data off the Mainframe.
However, it raises an interesting question: Where should Kafka Connect be deployed? On the mainframe or in the traditional IT environment? At Confluent, we support deploying Kafka Connect and the IBM MQ connectors on the mainframe, specifically on zLinux / the System z Integrated Information Processor (zIIP).
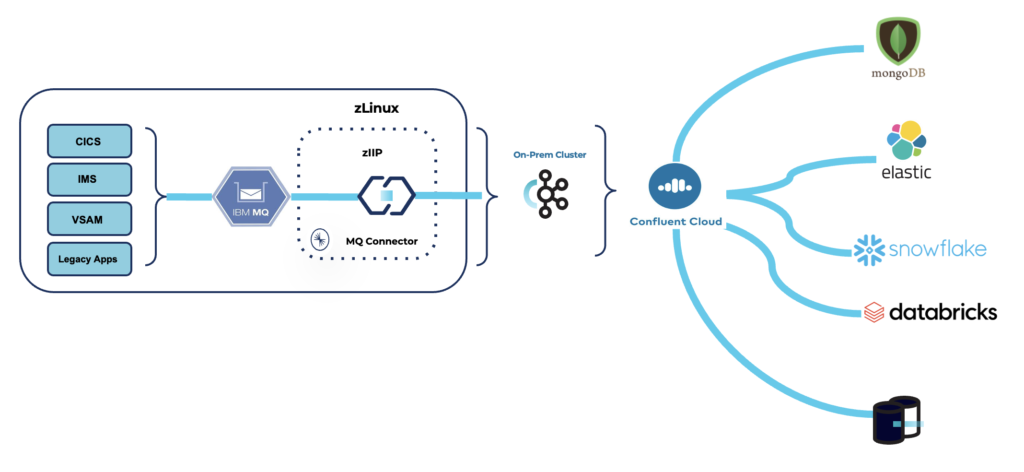
This shows vast benefits for the customer, like 10x better performance and MQ MIPS cost reductions of up to 90%.
Migration from a message broker to data streaming because of cost or scalability issues
Migration can mean two things:
- Completely migrating away from the existing messaging infrastructure, including client and server-side
- Replacing message brokers (like TIBCO EMS or IBM MQ) because of licensing or scalability issues but keeping the JMS-based messaging applications running
The first option is a big bang, which often includes a lot of effort and risk. If the main points are license costs or scalability problems, another alternative is viable with the Confluent Accelerator “JMS Bridge” to migrate from JMS to Kafka on the server side:
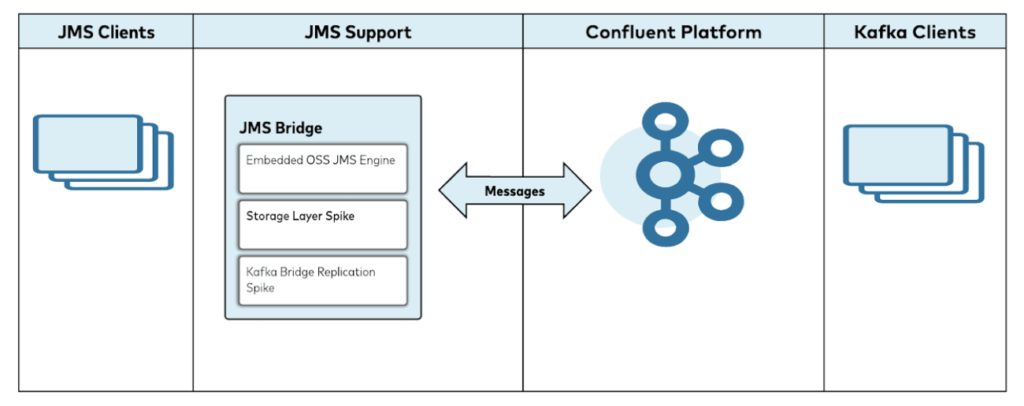
The Confluent JMS Bridge enables the migration from JMS brokers to Apache Kafka (while keeping the JMS applications). Key features include:
- The JMS Bridge is built around a modified open-source JMS engine
- Supports full JMS 2.0 spec as well as Confluent/Kafka
- Publish and subscribe anywhere data is intended for end users
- JMS-specific message formats can be supported via Schema Registry (Avro)
- Existing JMS applications replace current JMS implementation jars with Confluent jars that embed an open-source JMS implementation and wrap it to the Kafka API
Slide Deck and Video: Message Broker vs. Apache Kafka
The following slide deck explores the trade-offs, integration options, and migration scenarios for JMS-based message brokers and data streaming with Apache Kafka. Even if you use a message broker that is not JMS-based (like RabbitMQ), most of the aspects are still valid for a comparison:
And here is the on-demand video recording for the above slide deck:
You are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
Data streaming is much more than messaging!
This blog post explored when to use a message broker or a data streaming platform, how to integrate both, and how to migrate from JMS-based messaging solutions to Apache Kafka. Advance Auto Parts is a great success story from the retail industry that solves the spaghetti architecture with a decentralized, fully managed data streaming platform.
TL;DR: Use a JMS broker for simple, low-volume messaging from A to B.
Apache Kafka is usually a data hub between many data sources and data sinks, enabling real-time data sharing for transactional and high-volume analytical workloads. Kafka is also used to build applications; it is more than just a producer and consumer API.
The data integration and data processing capabilities of Kafka at any scale with true decoupling and event replayability are significant differences from JMS-based MQ systems.
What message brokers do you use in your architecture? What is the mid-term strategy? Integration, migration, or just keeping the status quo? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
