Apache Kafka added Tiered Storage to separate compute and storage. The capability enables more scalable, reliable and cost-efficient enterprise architectures. This blog post explores the architecture, use cases, benefits, and a case study for storing Petabytes of data in the Kafka commit log. The end discusses why Tiered Storage does NOT replace other databases and how Apache Iceberg might change future Kafka architectures even more.
If you prefer watching a ten minute video, check out this summary about the “Evolution of Storage for Apache Kafka covering Tiered Storage, Direct Write to Object Storage and the relation to Open Table Formats such as Apache Iceberg”:
You are currently viewing a placeholder content from Default. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
Now, let’s explore why Tiered Storage for Apache Kafka is a BIG THING:
Compute vs. Storage vs. Tiered Storage
Let’s define the terms compute, storage, and tiered storage to have the same understanding when exploring this in the context of the data streaming platform Apache Kafka.
Compute and Storage
Two fundamental components of a computing system are compute and storage. They serve different purposes in information processing.
Compute refers to the processing power and capability of a computer system to perform tasks, execute instructions, and carry out computations. The compute component includes the CPU (Central Processing Unit) and GPU (Graphics Processing Unit).
Storage refers to the components and systems that store and retrieving data over the long term. It is where data is persistently maintained for later use. Storage includes devices such as hard disk drives (HDDs), solid-state drives (SSDs), and other types of non-volatile memory, such as databases that keep data even when the power is turned off.
Tiered Storage
Tiered storage refers to a storage architecture that uses different classes or tiers of storage (e.g., Object Storage on S3) to efficiently manage and store data based on its access patterns, performance requirements, and cost considerations.
The goal of tiered storage is to optimize the use of storage resources, balancing performance and cost, by placing data on the most suitable storage media based on its characteristics and the organization’s policies.
Data placement and movement between these tiers can be automated based on policies and algorithms that analyze usage patterns, access frequency, and other factors. This ensures that the most critical and frequently accessed data lives in high-performance storage, while less critical or infrequently accessed data is moved to lower-cost, lower-performance storage.
Long-Term Storage in Apache Kafka
Apache Kafka is an open-source distributed streaming platform that is used for building real-time data pipelines and streaming applications. Kafka is the established de facto standard for data streaming. The event streaming platform handles large volumes of data, providing a scalable and fault-tolerant architecture.
Applications and data stores use Kafka for ingesting, storing, and processing real-time data streams, making it a fundamental component in building event-driven architectures and systems that require the processing of continuous data flows. Additionally, many use cases leverage Kafka not just for real-time data but to ensure data consistency across real-time, batch, and request-response APIs.
Use Cases for Apache Kafka as Storage System
While most people think about Kafka as a message broker, real-time analytics platform, or big data ingestion system, the distributed commit log with ordering guarantees and timestamps enables plenty of use cases for accessing data long after its creation or replaying historical data.
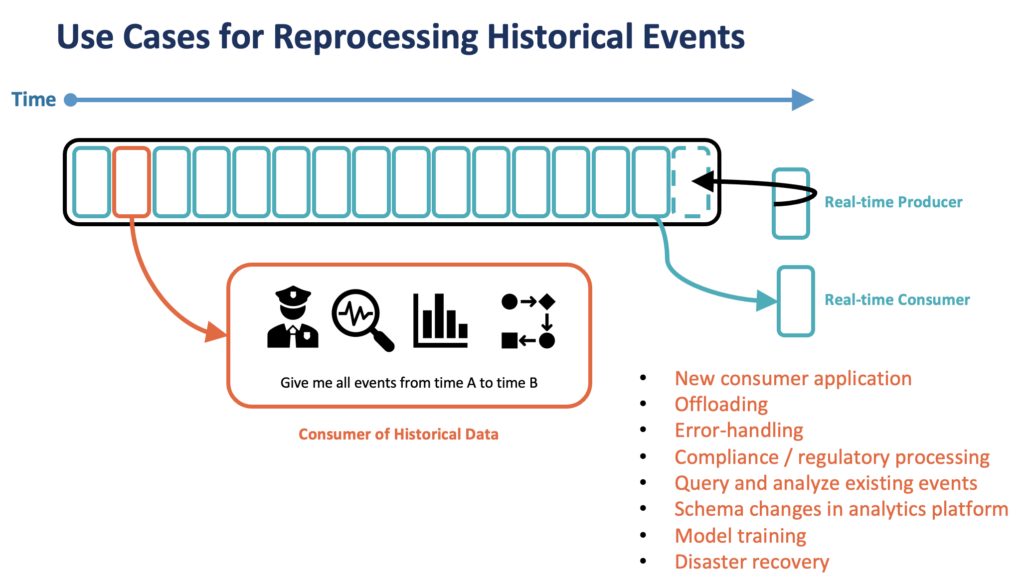
Here are a few examples for use cases that leverage long-term storage of data in Kafka:
- New consumer: Deploy a new application / database / data warehouse, data lake and synchronize the state of the business objects.
- Offloading: Reducing cost significantly by NOT consuming again and again from expensive or non-scalable systems (e.g. mainframe and MIPS)
- Error-handling: Re-process historical data after fixing an issue in the business logic.
- Compliance / regulatory processing: Replay historical data to analyze an incident.
- Query and analyze existing events: Consume data from a notebook for data engineering, analytics, or reporting.
- Schema changes in analytics platform: Re-process data after updating data contracts.
- Model training: Batch ingestion into an AI framework to apply a machine learning algorithm
- Disaster recovery: Operational data stores replay data again from the persistent commit log in the case of a failure.
- …
Objections for Storing Data Long-Term in Kafka
Storing data long term in Kafka has a few drawbacks. The following arguments are valid concerns:
- Cost: Storing large volumes of data on attached disks is much more expensive than external storage systems like an object store.
- Scalability: Operating Kafka brokers with lots of data (say many gigabytes, or even terabytes, and more) is challenging, especially in the case of failures when you need to rebalance partitions.
- Risk: Downtime or data inconsistencies happen if operations struggle with large volumes or when hardware needs to be migrated.
Therefore, you should NOT store big data sets in Kafka without Tiered Storage! With this in mind, let’s explore how Tiered Storage for Kafka solves these problems.
Introducing Tiered Storage for Apache Kafka
Apache Kafka’s backend is a distributed system running Kafka brokers. Each Kafka broker has processing and storage capabilities.
The applications are producers and consumers of events. Many interfaces communicate with Kafka brokers:
- An application written in Java, Python, C++, Go, or any other programming language
- A Kafka Connect source or sink connector connecting to IBM MQ, Spark, Snowflake, or any other data store or SaaS application
- A stream processor built with Kafka-native Kafka Streams, KSQL, or external infrastructures like Apache Flink
- Any other endpoint, like a HTTP interface or an out-of-the-box integration of another middleware or data platform
What is Tiered Storage for Kafka?
Tiered storage for Apache Kafka refers to the capability of configuring different storage tiers to optimize the storage infrastructure based on the access patterns and requirements of the data stored in Kafka brokers.
A Kafka cluster stores data in Kafka Topics. These topics can have different characteristics in terms of importance, access frequency, and retention policies.
The concept is like the general idea of tiered storage in storage systems, but it’s adapted to the specific needs of Kafka. Tiered Storage is one critical making the Kafka architecture cloud-native.
Kafka Architecture without Tiered Storage
Kafka applications communicate with logical Kafka Topics to produce messages to or consume messages from partitions:
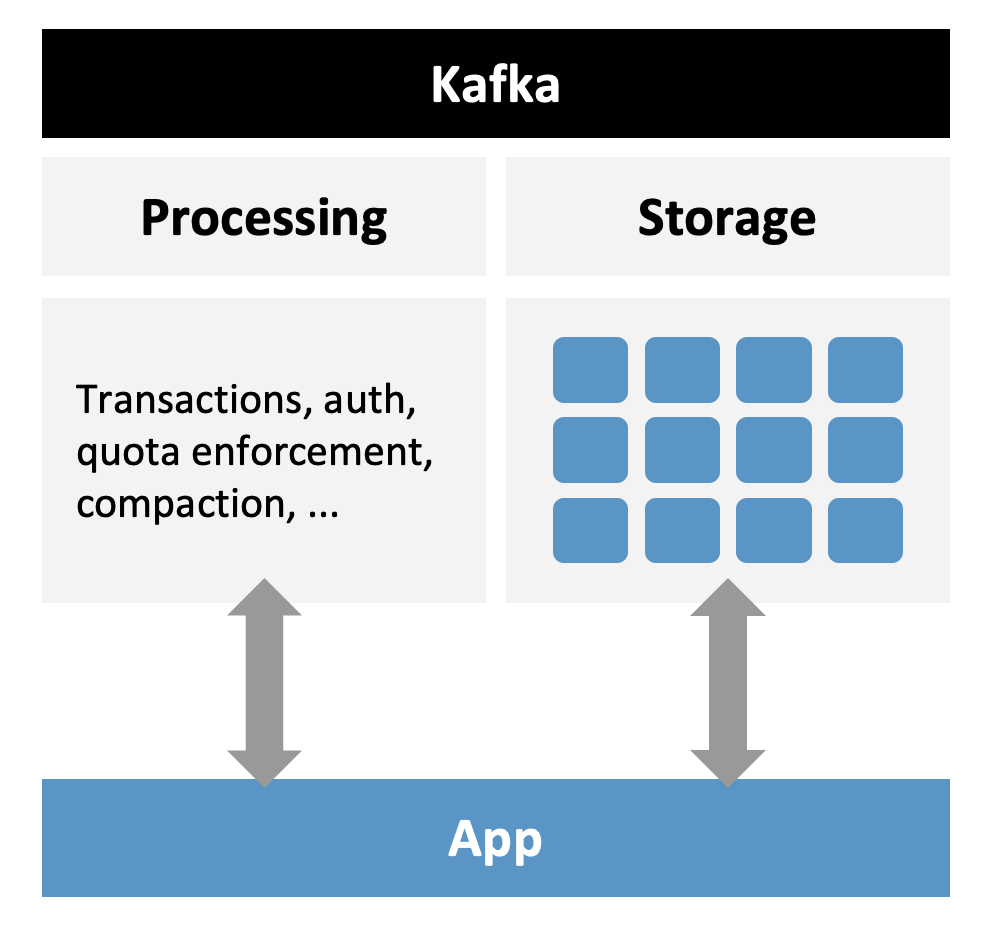
The storage is a disk attached to the broker. This can be HDD or SDD disks on-premise or e.g. EBS volumes on AWS cloud.
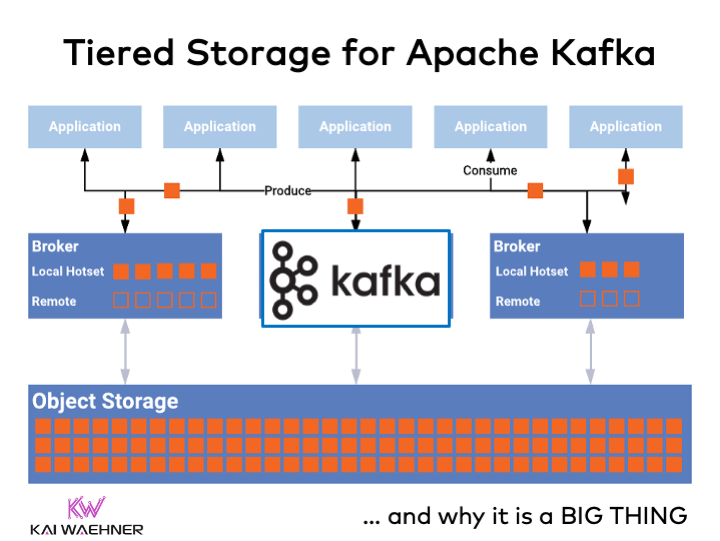
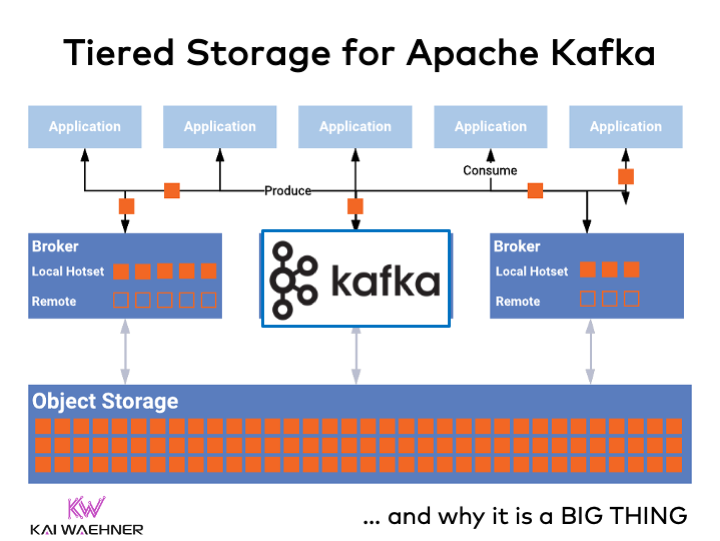
Kafka Architecture with Tiered Storage
Tiered Storage for Kafka does NOT change how applications communicate with Kafka brokers. Tiered Storage is an implementation detail:
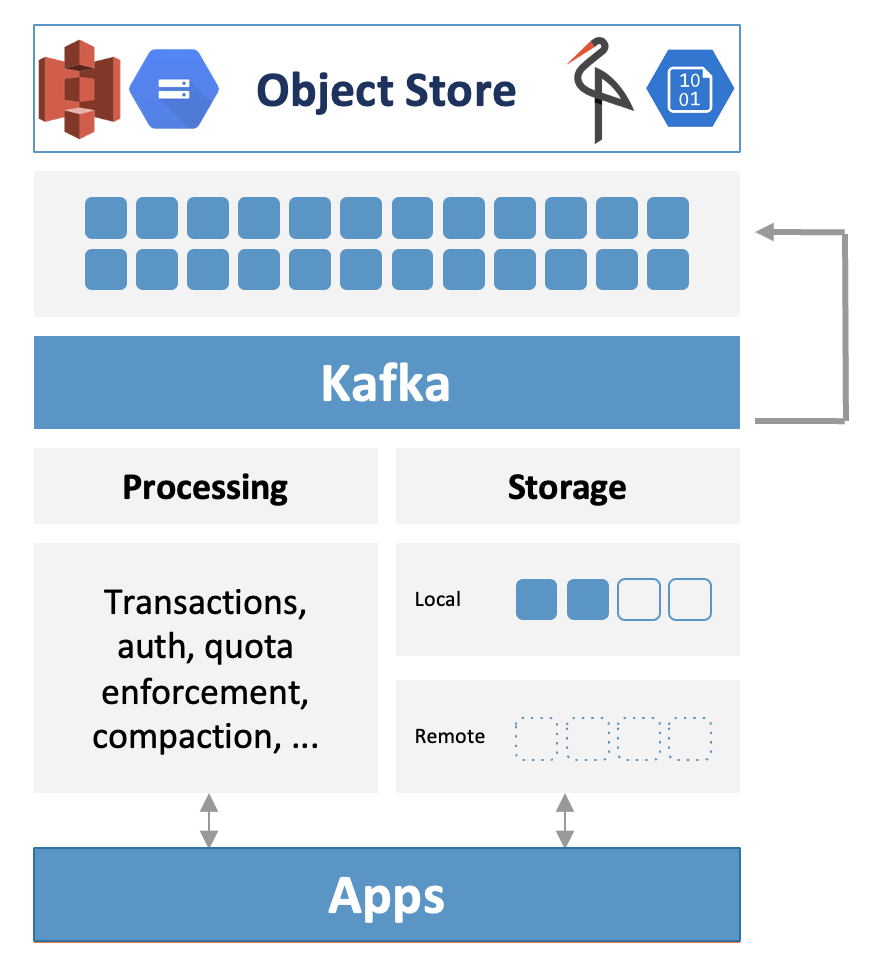
Besides the disks attached to the broker, Kafka offloads data to an external storage. Most times, this is an object storage like Amazon S3, Azure Blog Storage, Google Cloud Storage, or MinIO for Kubernetes.
Serverless cloud offerings handle the offloading for the operator. Self-managed solutions allow operators to configure hot and cold storage durations for each Kafka Topic.
Benefits of Tiered Storage for Apache Kafka
Let’s review the above-discussed objections to storing big data sets long-term in Kafka and how Tiered Storage helps:
- Reduced cost: Most data is offloaded to an external storage. This reduces the storage cost significantly.
- Improved scalability: Only data on the disks attached to the Kafka brokers must be rebalanced. As most data is offloaded, rebalancing only takes seconds or minutes; even if the external storage saves petabytes.
- Reduced risk: Better scalability and separation of compute and storage makes operations much easier and significantly reduces the risk of downtime or data inconsistency.
The Implementation of Tiered Storage in Apache Kafka
Tiered Storage for Apache Kafka is available. However, be aware that different implementations exist with different features, maturity, and support levels.
And open source Apache Kafka only provides the interface for tiered storage. You must choose an open source implementation, build your own integration into an external storage system, or leverage a commercial product or cloud service that embeds tiered storage into its offering.
Keep in mind that the interface alone is not helpful. The implementation needs to be battle-tested and guarantee data consistency across the hot storage on the broker and cold storage in the external storage; even in the case of failure, network issues, etc.
Kafka consumers do not see the implementation details of Kafka’s Tiered Storage. They just consumed as if there was no tiered storage implementation (and still expect the same behavior). There are no API or code changes needed in Kafka client applications. Hence, you can easily migrate an existing deployment to a Kafka cluster leveraging Tiered Storage.
Many people ask about the performance impact of tiered storage for Kafka. The short answer: There is no performance impact for most scenarios. Real-time consumers consume from the memory / page cache as before. And replaying historical data from the event log does not differ much from the local disk or the remote object-store.
AK 3.6 Release Makes Tiered Storage Available
When writing this blog post (December 2023), KIP-405: Kafka Tiered Storage is available as early access in Apache Kafka 3.6. This release introduces Tiered Storage to Kafka. This release is only for non-production environments (see the early access notes for more information).
GA of this feature is just a foreseeable matter of time. The bulk of KIP-405 was part of early access in release 3.6. But there are a few additional features that are slated for 3.7. And GA likely comes after that in 3.8+.
KIP-405 Provides a Pluggable Storage API for Tiering
KIP-405 separates computation and storage in the Kafka broker for pluggable storage tiering natively in Kafka Tiered Storage, bringing a seamless storage extension to remote objects with minimal operational changes.
Apache Kafka’s LocalTieredStorage default implementation is a local file-based RemoteStorageManager. LocalTieredStorage facilitates the simulation of remote storage behavior in a controlled and isolated environment during testing. This is not meant for production use cases! Enterprises need to write their own implementation, embed an open-source alternative, or trust a software vendor respectively cloud service.
How Confluent, Uber, and Others use Tiered Storage
KIP-405 is only available in preview with Kafka 3.6. But some proprietary implementations already exist for years in production. This also helped to define the KIP with lessons learned from running Kafka in production with tiered storage under the hood.
Implementation details of tiered storage for Kafka vary, and there may be different approaches or tools available to achieve this, depending on the specific Kafka distribution or storage infrastructure being used. Organizations might also use external systems or cloud storage solutions to implement tiered storage strategies for Kafka.
Confluent pioneered tiered storage for Kafka and has provided the capability for several years already. It is available for the self-managed Confluent Platform and the fully managed Confluent Cloud in AWS, Azure, and GCP. Confluent chose the S3 interface to implement storage support for the cloud providers (AWS, Azure, GCP) and several on-premise solutions like PureStorage Flash Blade, Nutanix Objects, Netapp Object Storage, Dell EMC ECS, Hitachi Content Platform Object Storage, or MinIO for Kubernetes.
Uber, who had the lead in implementing the KIP-405 in open source Apache Kafka, runs its tiered storage against HDFS. Confluent and AWS contributed to refactoring, best practices and performance / integration testing. Satish Duggana, tech lead for Data and Streaming Infrastructure at Uber, presented the details of their implementations and deployment in a talk at Current 2023.
Other vendors like AWS with MSK and Aiven are adopting KIP-405 and provide their own tiered storage implementations these days.
Case Study: KOR Financial stores 160 Petabytes in Kafka for Regulatory Reporting
KOR is a cloud-native family of global trade repositories and regulatory reporting services that has adopted Confluent Cloud and a data streaming architecture to improve compliance processes.
Regulatory reporting is obviously a perfect use case for Tiered Storage in Kafka to replay historical data. As the Kafka log provides guaranteed ordering and timestamps, there is no need for another database or data lake besides Kafka.
Daan Gerits, Chief Data Officer, KOR Financial, explains at Diginomica: “At KOR Financial, we have a very specific problem that we are trying to solve, which is collecting trading information for regulators. And we decided to do it in a totally different way to the way that most people are doing it. Where others would be using data storage or big data technologies, we decided to go all in on Kafka. We are building our system to store 160 petabytes in Confluent Cloud and then work on top of that. We don’t have any other database. So it’s a long retention use case.”
Kafka is NOT a Database (Replacement)
Apache Kafka is a database. It provides ACID guarantees. Hundreds of companies for deploy Kafka for mission-critical deployments including transactional workloads. However, most times, Kafka is NOT competitive to other databases.

Kafka is an event streaming platform for messaging, storage, processing and integration at scale in real-time with zero downtime and zero data loss. Almost all deployments connect Kafka to database sources and sinks for data integration, decoupling and data consistency, where the heart of the cloud-native enterprise architecture is real-time, scalable and reliable.
Apache Kafka is complementary to database, data warehouse, data lake and Lakehouse architectures. I wrote a blog series about use cases and architectures for data streaming other storage platforms.
The Future: Apache Iceberg for Kafka?
The adoption of Tiered Storage for Apache Kafka is just getting started. Many teams will store (some) data longer in Kafka to offload data from expensive systems or replay historical data without needing another database.
However, most analytics platforms do NOT use the Kafka protocol to consume and query data. The trend across most data platforms goes towards Apache Iceberg as a standardized abstraction layer for storing and querying (non-real-time) data in an objects store or other storage.
Apache Iceberg is an open-source table format and processing framework for big data. It aims to provide the best of both worlds: the performance of a traditional table format with the flexibility of a schema-on-read approach. Iceberg addresses solves in managing large-scale and evolving data sets in distributed storage environments.
Apache Iceberg supports popular data processing frameworks, such as Apache Spark, Apache Flink, Apache Hive, Presto, and more. With Kafka’s Tiered Storage and especially the S3 support by some vendors, I can see how this can be an entire game changer for storing and processing events in real-time with the Kafka protocol or with other analytics engines and databases in near-real-time or batch.
The future will show us. For now, let’s be excited about how Tiered Storage for Kafka is the next big thing around data streaming.
Tiered Storage makes Kafka more Scalable, Cost-Efficient and Reliable
Tiered Storage for Apache Kafka makes event-driven architectures more scalable, cost-efficient and reliable. It enables new use cases that require another database or data lake in the past.
However, Kafka’s goal is still NOT to replace other data and analytics platforms. Design patterns like microservices and data mesh enable a true decoupling of applications and data stores. Kafka provides this decoupling. With tiered storage in mind for various use cases such as offloading, new consumers, or error-handling, you can consider new approaches for your cloud-native enterprise architecture.
Are you excited about Tiered Storage for Apache Kafka? How will you use it? Or do you already use an existing implementation, like Confluent Cloud? Let’s connect on LinkedIn and discuss it! Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter.