The concepts and architectures of a data warehouse, a data lake, and data streaming are complementary to solving business problems. Storing data at rest for reporting and analytics requires different capabilities and SLAs than continuously processing data in motion for real-time workloads. Many open-source frameworks, commercial products, and SaaS cloud services exist. Unfortunately, the underlying technologies are often misunderstood, overused for monolithic and inflexible architectures, and pitched for wrong use cases by vendors. Let’s explore this dilemma in a blog series. Learn how to build a modern data stack with cloud-native technologies. This is part 1: Data Warehouse vs. Data Lake vs. Data Streaming – Friends, Enemies, Frenemies?
Blog Series: Data Warehouse vs. Data Lake vs Data Streaming
This blog series explores concepts, features, and trade-offs of a modern data stack using a data warehouse, data lake, and data streaming together:
- THIS POST: Data Warehouse vs. Data Lake vs. Data Streaming – Friends, Enemies, Frenemies?
- Data Streaming for Data Ingestion into the Data Warehouse and Data Lake
- Data Warehouse Modernization: From Legacy On-Premise to Cloud-Native Infrastructure
- Case Studies: Cloud-native Data Streaming for Data Warehouse Modernization
- Lessons Learned from Building a Cloud-Native Data Warehouse
Stay tuned for a dedicated blog post for each topic as part of this blog series. I will link the blogs here as soon as they are available (in the next few weeks). Subscribe to my newsletter to get an email after each publication (no spam or ads).
I also created a short ten minute video that explains the differences between data streaming and a lakehouse (and why they are complementary):
You are currently viewing a placeholder content from Default. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
The value of data: Transactional vs. analytical workloads
The last decade offered many articles, blogs, and presentations about data becoming the new oil. Today, nobody questions that data-driven business processes change the world and enable innovation across industries.
Data-driven business processes require both real-time data processing and batch processing. Think about the following flow of events across applications, domains, and organizations:
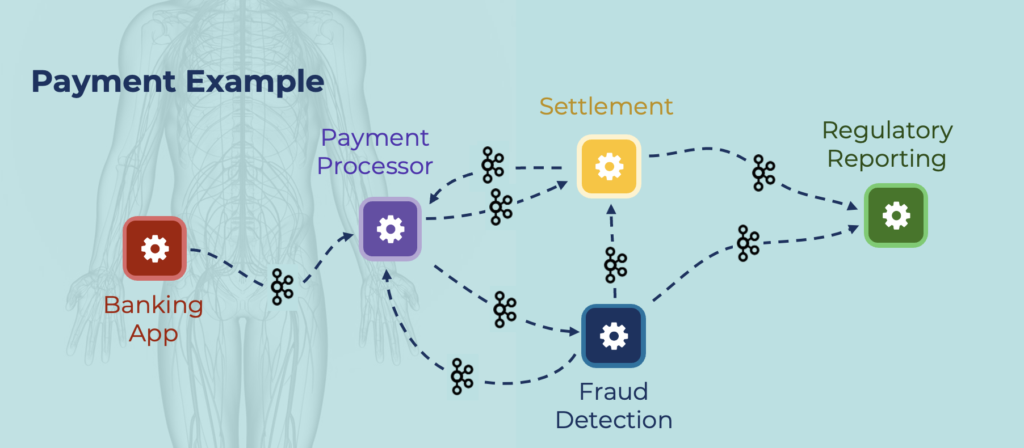
An event is business information or technical information. Events happen all the time. A business process in the real world requires the correlation of various events.
How critical is an event?
The criticality of an event defines the outcome. Potential impacts can be increased revenue, reduced risk, reduced cost, or improved customer experience.
- Business transaction: Ideally, zero downtime and zero data loss. Example: Payments need to be processed exactly once.
- Critical analytics: Ideally, zero downtime. Data loss of a single sensor event might be okay. Alerting on the aggregation of events is more critical. Example: Continuous monitoring of IoT sensor data and a (predictive) machine failure alert.
- Non-critical analytics: Downtime and data loss are not good but do not kill the whole business. It is an accident, but not a disaster. Example: Reporting and business intelligence to forecast demand.
When to process an event?
Real-time usually means end-to-end processing within milliseconds or seconds. If you don’t need real-time decisions, batch processing (i.e., after minutes, hours, days) or on-demand (i.e., request-reply) is sufficient.
- Business transactions are often real-time: A transaction like a payment usually requires real-time processing (e.g., before the customer leaves the store; before you ship the item; before you leave the ride-hailing car).
- Critical analytics is usually real-time: Critical analytics very often requires real-time processing (e.g., detecting the fraud before it happens; predicting a machine failure before it breaks; upselling to a customer before he leaves the store).
- Non-critical analytics is usually not real-time: Finding insights in historical data is usually done in a batch process using paradigms like complex SQL queries, map-reduce, or complex algorithms (e.g., reporting; model training with machine learning algorithms; forecasting).
With these basics about processing events, let’s understand why storing all events in a single, central data lake is not the solution to all problems.
Flexibility through decentralization and best-of-breed
The traditional data warehouse respectively data lake approach is to ingest all data from all sources into a central storage system for centralized data ownership. The sky (and your budget) is the limit with current big data and cloud technologies.
However, architectural concepts like domain-driven design, microservices, and data mesh show that decentralized ownership is the right choice for modern enterprise architecture:
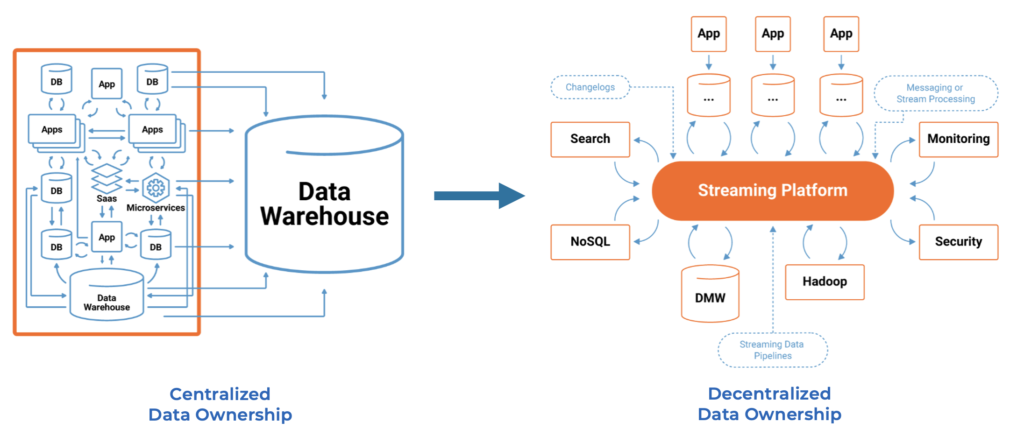
No worries. The data warehouse and the data lake are not dead but more relevant than ever before in a data-driven world. Both make sense for many use cases. Even in one of these domains, larger organizations don’t use a single data warehouse or data lake. Selecting the right tool for the job (in your domain or business unit) is the best way to solve the business problem.
There are good reasons people are pleased with Databricks for batch ETL, machine learning, and now even data warehouse, but still prefer a lightweight cloud SQL database like AWS RDS (fully managed PostgreSQL) for some use cases.
There are good reasons happy Splunk users also ingest some data into Elasticsearch instead. And why Cribl is getting more and more traction in this space, too.
There are good reasons some projects leverage Apache Kafka as the database. Storing data long-term in Kafka makes only sense for some specific use cases (like compacted topics, key/value queries, streaming analytics). Kafka does not replace other databases or data lakes.
Choose the right tool for the job with decentralized data ownership!
With this in mind, let’s explore the use cases and added value of a modern data warehouse (and how it relates to data lakes and the new buzz lakehouse).
Data warehouse: Reporting and business intelligence with data at rest
A data warehouse (DWH) provides capabilities for reporting and data analysis. It is considered a core component of business intelligence.
Use cases for data at rest
No matter if you use a product called a data warehouse, data lake, or lakehouse. The data is stored at rest for further processing:
- Reporting and Business Intelligence: Fast and flexible availability of reports, statistics, and key figures, for example, to identify correlations between market and service offering
- Data Engineering: Integration of data from differently structured and distributed data sets to enable the identification of hidden relationships between data
- Big Data Analytics and AI / Machine Learning: Global view of the source data and thus overarching evaluations to find unknown insights to improve business processes and interrelationships.
Some readers might say: Only the first is a use case for a data warehouse, and the other two are for a data lake or lakehouse! It all depends on the definition.
Data warehouse architecture
DWHs are central repositories of integrated data from disparate sources. They store historical data in one storage system. The data is stored at rest, i.e., saved for later analysis and processing. Business users analyze the data to find insights.
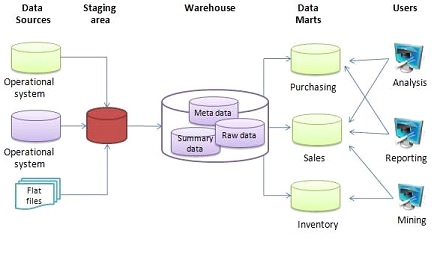
The data is uploaded from operational systems, such as IoT data, ERP, CRM, and many other applications. Data cleansing and data quality assurance are crucial pieces in the DWH pipeline. Extract, Transform, Load (ETL) or Extract, Load, Transform (ELT) are the two main approaches to building a data warehouse system. Data marts help to focus on a single subject or line of business within the data warehouse ecosystem.
The relation of the data warehouse to data lake and lakehouse
The focus of a data warehouse is reporting and business intelligence using structured data. Contrarily, the data lake is a synonym for storing and processing raw big data. A data lake was built with technologies like Hadoop, HDFS, and Hive in the past. Today, the data warehouse and data lake merged into a single solution. A cloud-native DWH supports big data. Similarly, a cloud-native data lake needs business intelligence with traditional tools.
Databricks: The evolution from the data lake to the data warehouse
That’s true for almost all vendors. For example, look at the history of one of the leading big data vendors: Databricks, known for being THE Apache Spark company. The company started as a commercial vendor behind Apache Spark, a big data batch processing platform. The platform was enhanced with (some) real-time workloads using micro-batching. A few milestones later, Databricks is an entirely different company today, focusing on cloud, data analytics, and data warehousing. Databricks’ strategy changed from:
- open source to the cloud
- self-managed software to fully-managed serverless offerings
- focus on Apache Spark to AI / Machine Learning and later added data warehousing capabilities
- a single product to a vast product portfolio around data analytics, including standardized data formats (“Delta Lake”), governance, ETL tooling (Delta Live Tables), and more,
Vendors like Databricks and AWS also coined a new buzzword for this merge of the data lake, data warehouse, business intelligence, and real-time capabilities: The Lakehouse.
The Lakehouse (sometimes called Data Lakehouse) is nothing new. It combines characteristics of separate platforms. I wrote an article about building a cloud-native serverless lakehouse on AWS using Kafka in conjunction with AWS analytics platforms.
Snowflake: The evolution from the data warehouse to the data lake
Snowflake came from the other direction. It was the first genuinely cloud-native data warehouse available on all major clouds. Today, Snowflake provides many more capabilities beyond the traditional business intelligence spectrum. For instance, data and software engineers have features to interact with Snowflake’s data lake through other technologies and APIs. The data engineer requires a Python interface to analyze historical data, while the software engineer prefers real-time data ingestion and analysis at any scale.
No matter if you build a data warehouse, data lake, or lakehouse: The crucial point is understanding the difference between data in motion and data at rest to find the right enterprise architecture and components for your solution. The following sections explore why a good data warehouse architecture requires both and how they complement each other very well.
Transactional real-time workloads should not run within the data warehouse or data lake! Separation of concerns is critical due to different uptime SLAs, regulatory and compliance laws, and latency requirements.
Data streaming: Supplementing the modern data warehouse with data in motion
Let’s clarify: Data streaming is NOT the same as data ingestion! You can use a data streaming technology like Apache Kafka for data ingestion into a data warehouse or data lake. Most companies do this. Fine and valuable.
BUT: A data streaming platform like Apache Kafka is so much more than just an ingestion layer. Hence, it differs significantly from ingestion engines like AWS Kinesis, Google Pub/Sub, and similar tools.
Data streaming is NOT the same as data ingestion
Data streaming provides messaging, persistence, integration, and processing capabilities. High scalability for millions of messages per second, high availability including backward compatibility and rolling upgrades for mission-critical workloads, and cloud-native features are some of the built-in features.
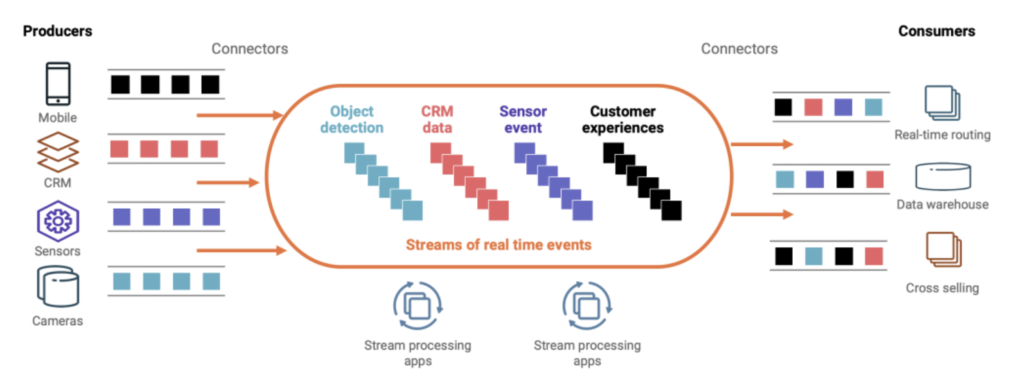
The de facto standard for data streaming is Apache Kafka. Therefore, I mainly use Kafka for data streaming architectures and use cases.
Transactional and analytics use cases for data streaming with Apache Kafka
The number of different use cases for data streaming is almost endless. Please remember that data streaming is NOT just a message queue for data ingestion! While data ingestion into a data lake was the first prominent use case, this implies <5% of actual Kafka deployments. Business applications, streaming ETL middleware, real-time analytics, and edge/hybrid scenarios are some of the other examples:
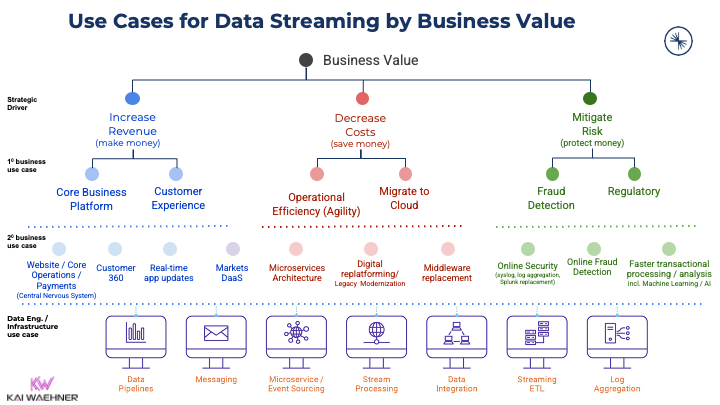
The persistence layer of Kafka enables decentralized microservice architectures for agile and truly decoupled applications.
Keep in mind that Apache Kafka supports transactional and analytics workloads. Both usually have very different uptime, latency, and data loss SLAs. Check out this post and slide deck to learn more about data streaming use cases across industries powered by Apache Kafka.
The next post of this blog series explores why data streaming with tools like Apache Kafka is the prevalent technology for data ingestion into data warehouses and data lakes.
Don’t (try to) use the data warehouse or data lake for data streaming
This blog post explored the difference between data at rest and data in motion:
- A data warehouse is excellent for reporting and business intelligence.
- A data lake is perfect for big data analytics and AI / Machine Learning.
- Data streaming enables real-time use cases.
- A decentralized, flexible enterprise architecture is required to build a modern data stack around microservices and data mesh.
None of the technologies is a silver bullet. Choose the right tool for the problem. Monolithic architectures do not solve today’s business problems. Storing all data only at rest does not help with the demand for real-time use cases.
The Kappa architecture is a modern approach for real-time and batch workloads to avoid a much more complex infrastructure using the Lambda architecture. Data streaming complements the data warehouse and data lake. The connectivity between these systems is available out-of-the-box if you choose the right vendors (that are often strategic partners, not competitors, as some people think).
For more details, browse to other posts of this blog series:
- THIS POST: Data Warehouse vs. Data Lake vs. Data Streaming – Friends, Enemies, Frenemies?
- Data Streaming for Data Ingestion into the Data Warehouse and Data Lake
- Data Warehouse Modernization: From Legacy On-Premise to Cloud-Native Infrastructure
- Case Studies: Cloud-native Data Streaming for Data Warehouse Modernization
- Lessons Learned from Building a Cloud-Native Data Warehouse
How do you combine data warehouse and data streaming today? Is Kafka just your ingestion layer into the data lake? Do you already leverage data streaming for additional real-time use cases? Or is Kafka already the strategic component in the enterprise architecture for decoupled microservices and a data mesh? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.