Durable execution engines, such as Temporal and Restate, are transforming how developers manage long-running workflows and transactions in distributed systems. By persisting workflow state, handling retries, and enabling fault-tolerant transactions, these engines ensure reliable execution and excel at automating machine-to-machine interactions, unlike traditional BPM tools designed for human-centric workflows.
When integrated with an event-driven platform like Apache Kafka, durable execution engines unlock new possibilities. Kafka’s durable, decoupled event storage acts as a backbone for real-time communication, while these engines orchestrate workflows such as order processing, coordinating inventory validation, payment authorization, and shipping, even in the face of failures.
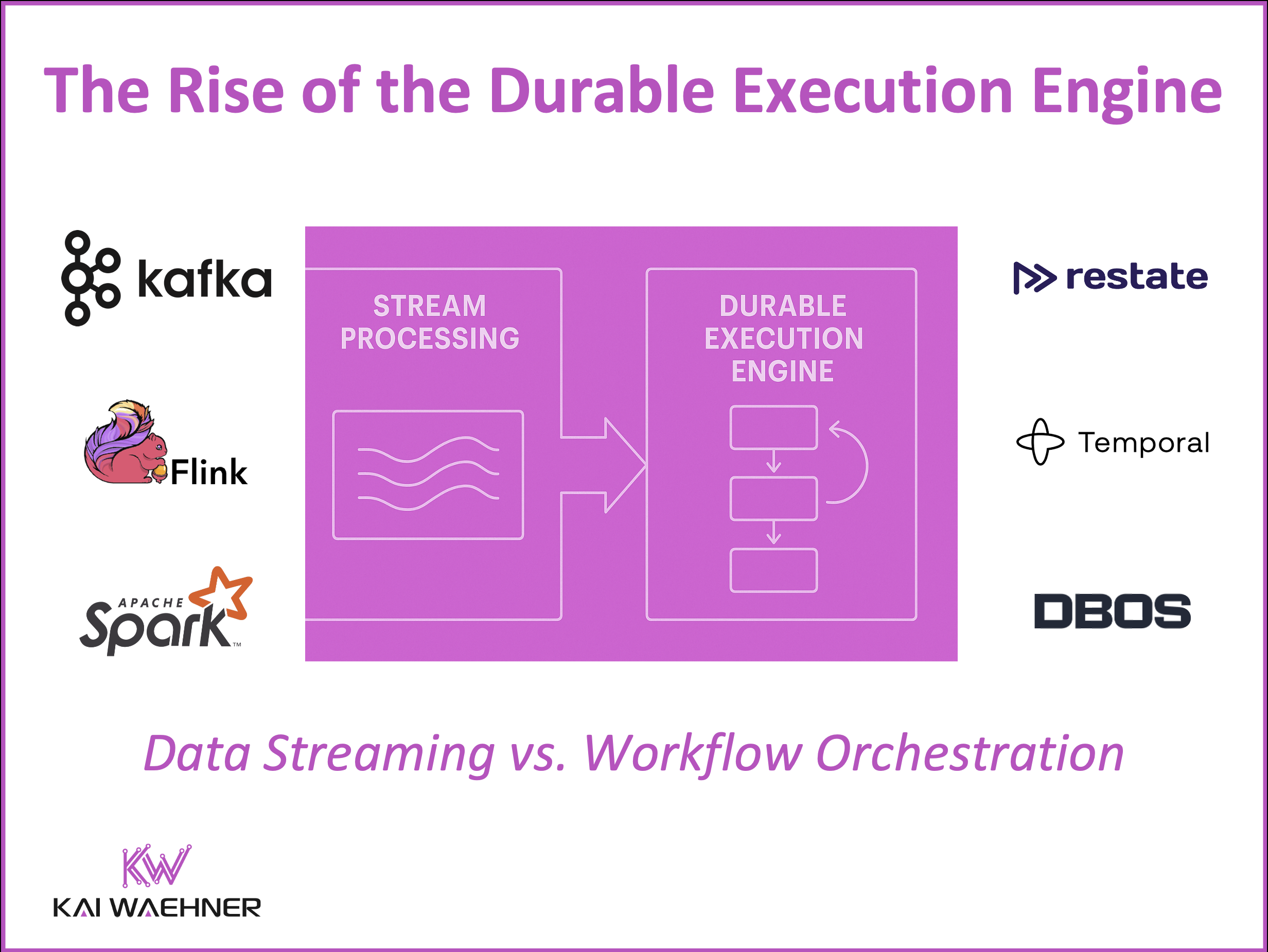
As the adoption of durable execution engines grows, they fill important gaps left by traditional BPM tools and complement existing stream processing frameworks. While stream processing tools like Kafka Streams or Apache Flink offer robust state management for real-time analytics and stateful computations, durable execution engines enhance state management by persisting workflow state over long periods. They are purpose-built for long-running, multi-step business processes, automatically handling retries, timeouts, and distributed transactions.
This blog explores capabilities, use cases, and integration of durable execution engines with data streaming technologies like Apache Kafka, Flink and Spark Structured Streaming—highlighting their potential to create scalable, resilient architectures for modern distributed enterprise systems.
Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free ebook about data streaming use cases across industries.
What Is a Durable Execution Engine?
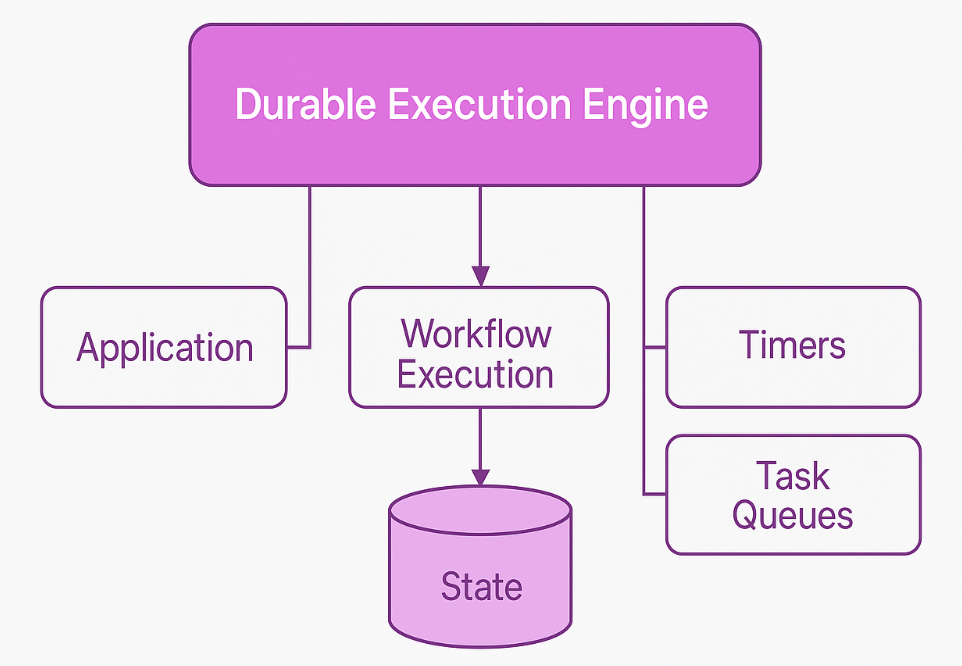
A durable execution engine ensures reliable, stateful execution of workflows and processes in distributed systems. It’s designed to manage workflows that are long-running, complex, or require durability across retries and failures. These engines:
- Persist the state of workflows to durable storage (e.g., databases).
- Automatically handle retries, timeouts, and rollbacks.
- Manage distributed transactions in a fault-tolerant way.
For example, in a distributed e-commerce application, an order-processing workflow might involve validating inventory, reserving funds, and arranging shipping. A durable execution engine ensures this process completes reliably, even if individual services fail or restart.
Key Vendors: Temporal, Restate, and More
The market for durable execution engines is still in its early stages, with the technology sitting near the beginning of the innovation curve—similar to the early phase of the Gartner Hype Cycle. Despite being so new, several promising vendors are already helping to define and shape this emerging category.
Temporal and Restate are very interesting emerging vendors in this space:
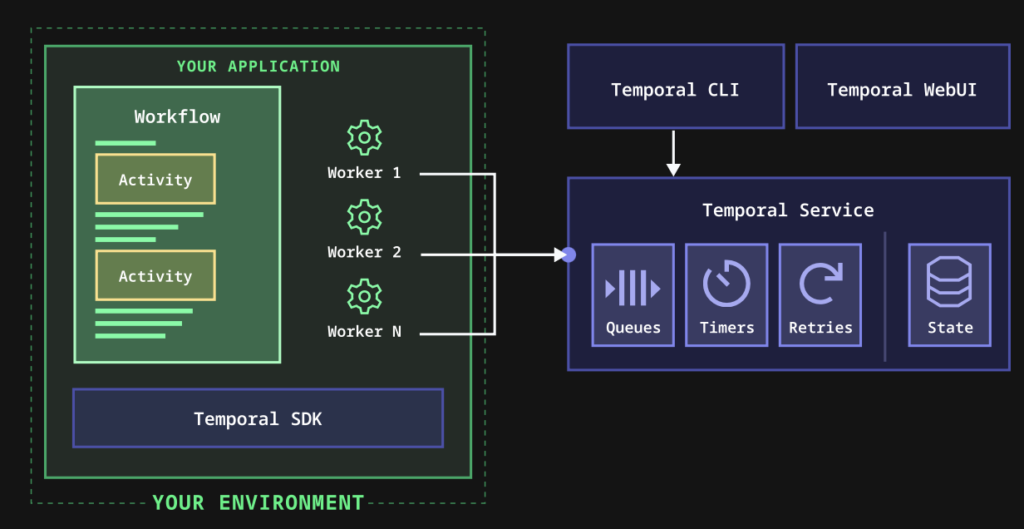
- Temporal: The open source framework provides SDKs (Java, Go, Python, Node.js) to define workflows as code. Temporal provides durable state management, ensuring workflows resume after failures without developers needing to reimplement retries or checkpoints.
- Restate: The proprietary solution focuses on providing a lightweight, cloud-native engine for resilient process execution, offering APIs for workflow orchestration and state tracking.
Both solutions integrate well with modern microservices architectures and support use cases like order management, fraud detection, and distributed batch jobs.
Temporal describes its architecture as follows: Build failproof, fault-tolerant applications in your preferred language using Temporal SDKs, which replace brittle state machines with durable workflows, automatic retries, and full execution visibility.
Other noteworthy tools include Cadence (an open-source predecessor of Temporal), Zeebe (a workflow engine designed for cloud-native applications by BPM vendor Camunda), and DBOS (a unified system integrating database and workflow execution capabilities).
How Durable Execution Engines Differ from BPM Engines
Durable execution engines share some similarities with traditional Business Process Management (BPM) engines but are optimized for different scenarios.
| Feature | BPM Engine | Durable Execution Engine |
|---|---|---|
| Focus | Human workflows, approvals, and form-based processes | Optimized for long-running, automated, fault-tolerant service orchestration |
| Durability | Often limited to task-level state | Built-in, state persists across failures |
| Development Model | Visual workflow modeling | Code-first |
| Scalability | Limited scalability | Optimized for distributed, scalable systems |
| Example Use Cases | Employee Onboarding, Invoice Approval Workflow, Loan Application Processing, Customer Complaint Resolution | Order Fulfillment in E-commerce, Insurance Claims Processing, Subscription Billing and Renewal, IoT Sensor Alert Workflow, Financial Transaction Settlement |
For instance, Camunda, a BPM engine, is well-suited for workflows that involve human approval steps, such as employee onboarding or compliance reviews. In contrast, durable execution engines are designed to orchestrate distributed microservices with complex dependencies, where robust coordination, retries, and state consistency are critical.
Note that Camunda also supports code integration, but BPMN remains central to its execution model—workflows are defined and executed based on BPMN diagrams. Code must align with the visual process model, limiting pure code-first workflow design.
Camunda anticipated the trend toward cloud-native architectures early with the launch of Zeebe, introducing horizontal scalability and event streaming into the BPM space—well before the term “durable execution engine” was coined.
A durable execution engine like Temporal or Restate goes one step further. It provides fine-grained control over retries, timeouts, and compensation logic (custom steps to undo or adjust actions when a failure occurs later in the workflow) to ensure stateful orchestration with strong transactional execution guarantees across unreliable networks and services.
Connecting Durable Execution Engines to an Event-driven Architecture
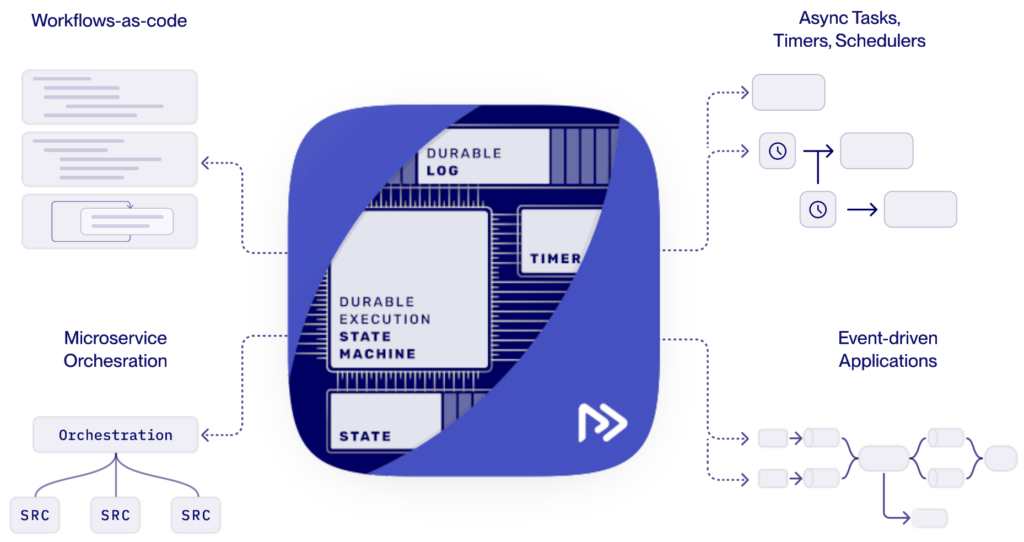
Event-driven architecture (EDA) is a natural fit for durable execution engines. EDA decouples producers and consumers using events, enabling asynchronous and reactive systems. A durable Execution engine complements EDA by managing the stateful orchestration of workflows triggered by these events.
For example, an event such as “OrderPlaced” could trigger a workflow in Temporal or Restate to:
- Validate inventory.
- Reserve payment.
- Notify shipping.
The workflow’s progress is stored in the durable execution engine to ensure it can resume at any step in case of service failures. This setup ensures high fault tolerance and operational reliability.
Restate explores in its product description how workflows, event-driven applications and micro service orchestration fit together in a durable execution engine:
Apache Kafka’s Role: True Decoupling and Seamless Integration
Apache Kafka is the backbone of most event-driven architectures today. It is used by over 150,000 organization to enable real-time data streaming and integration. Its features make it ideal for pairing with durable execution engines:
- True Decoupling: Producers and consumers are independent and communicate via topics. This decoupling reduces interdependencies and enables horizontal scaling, improving resilience and scalability.
- Durable Storage: Kafka retains events in a durable and replayable log with guaranteed ordering and timestamps. This allows workflows to process events asynchronously, ensuring downstream systems can recover from delays, failures, or outages without data loss.
- Broad Compatibility: Kafka integrates with a wide range of systems via:
- Kafka Connect: Pre-built connectors for databases, cloud services, and other systems.
- Kafka Clients: Libraries for most programming languages.
- REST Proxy: Enables integration with HTTP-based systems.
- Native Middleware Support: Seamless integration with other middleware and data platforms.
Limitations of Apache Kafka for Workflow Orchestration
While Apache Kafka, combined with stream processing, can act as a workflow engine, there are limitations:
- Manual State Management: Kafka, or more generally data streaming, lacks built-in tools for tracking workflow states or managing retries. Developers must implement these manually using patterns like saga orchestration.
- Lack of Workflow Semantics: Kafka Topics are excellent for messaging and as persistence layer for events, but stream processing lack built-in constructs like parallel execution or compensations.
- Code Complexity: Building a full-fledged workflow engine on Kafka and stream processing engines like Kafka Streams, Flink, or Spark Structured Streaming adds significant custom development overhead.
A dedicated blog post explores case studies across industries to show how enterprises like Salesforce or Swisscom implement stateful workflow automation and orchestration with Kafka and stream processing.
In contrast, a durable execution engine provides these features out of the box, allowing developers to focus on business logic rather than infrastructure.
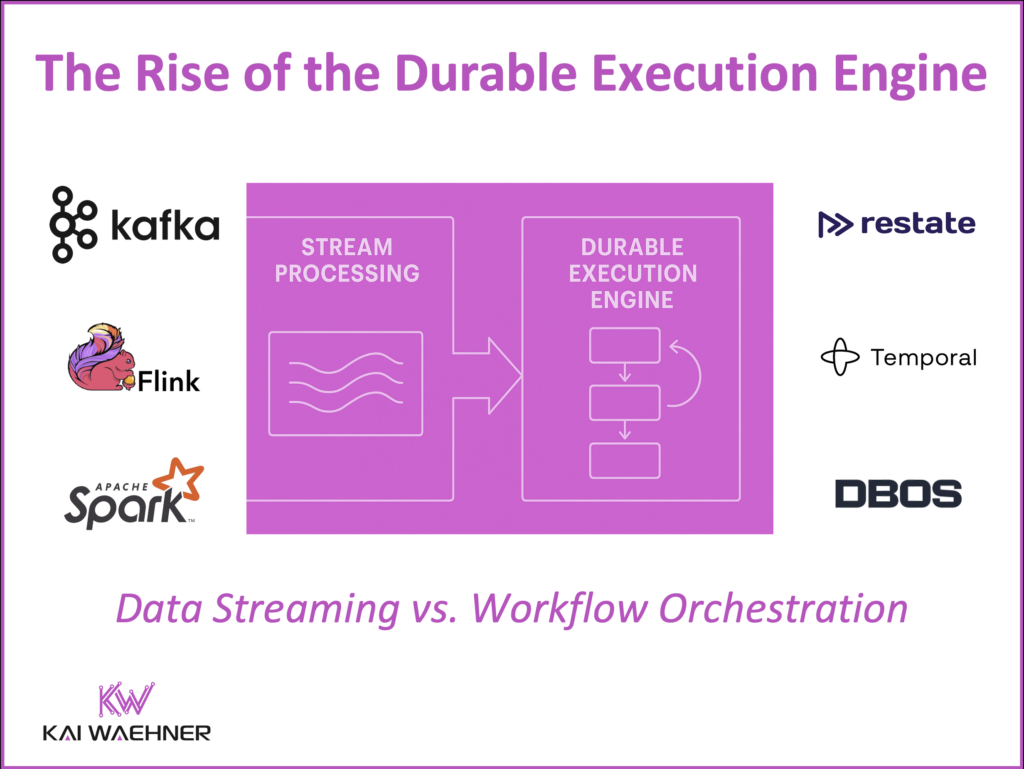
When to Use Stream Processing vs. Durable Execution Engine?
While stream processing tools like Kafka Streams, Apache Flink or Apache Spark’s Structured Streaming overlap a bit with durable execution engines, they serve distinct purposes.
Use Cases for Stream Processing (Kafka Streams, Apache Flink, Spark Structured Streaming)
Focuses on transforming and analyzing continuous data streams. Usually using a streaming API for real-time processing, but also for some analytical batch workloads. Ideal for use cases like:
- Real-time analytics (e.g., fraud detection in payments).
- Stateless and stateful transformations (e.g., aggregations over time windows).
- Enrichment of event data (i.e, combination real-time data streamings like orders with “static” master data from an ERP or CRM).
- Batch-style workloads using Spark Streaming or Flink’s Batch API for high-throughput processing and travel back in time for historical data replays (e.g., reprocessing one day of transaction data to regenerate reports for financial compliance or audit requests)
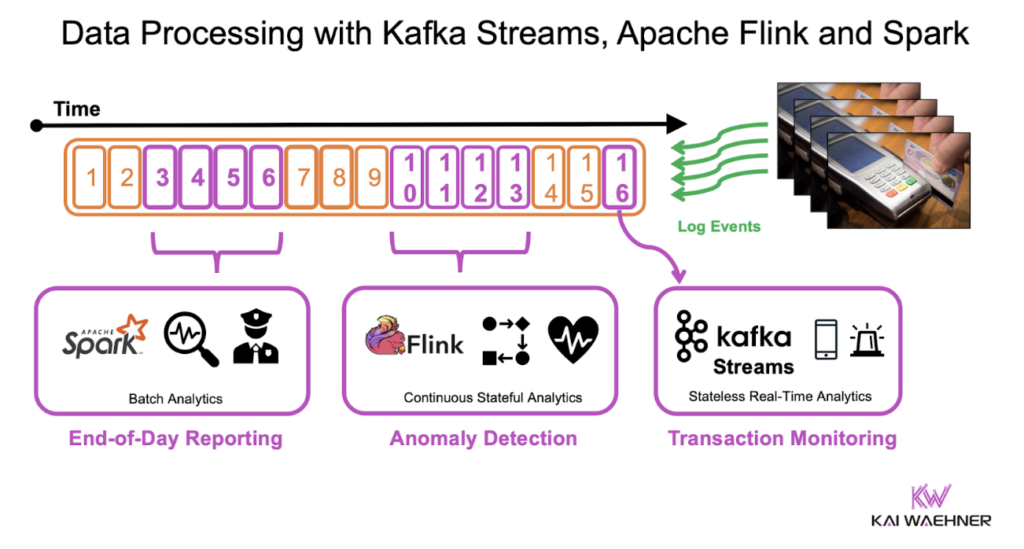
More details in my article “Stateless vs. Stateful Stream Processing with Kafka Streams and Apache Flink“.
Use Cases for a Durable Execution Engine (Restate, Temporal, DBOS)
Manage the lifecycle of workflows. Best for:
- Long-running processes (e.g., loan approvals).
- Complex microservice orchestration and distributed transactions (e.g., service-to-service calls).
- State management for business workflows (e.g., orchestrating a multi-step insurance claim process with approvals, data validation, and third-party interactions).
Spoilt for Choice – Stream Processing vs. Durable Execution Engine
If your primary goal is real-time analytics on event streams—such as aggregations, anomaly detection, or enrichment—then tools like Kafka Streams or Apache Flink are typically the best fit. They are designed for high-throughput, low-latency processing and also support stateful, durable computations, making them suitable for both stateless and windowed operations.
However, if you need to coordinate long-running workflows, handle multi-step transactions across distributed systems, or manage retries, timeouts, and compensation logic, a durable execution engine may be the better choice. These engines are optimized for reliability and business process continuity rather than stream analytics.
That said, introducing additional workflow tooling adds complexity to your architecture. Careful evaluation is essential—consider whether your existing stream processing tools can meet your workflow needs before introducing a separate execution engine.
The Emerging Role of the Durable Execution Engine in Distributed Systems
Durable execution engines like Temporal and Restate are transforming the way developers build and manage workflows in distributed systems. These engines address gaps left by traditional BPM tools and stream processing frameworks like Kafka Streams, Apache Flink or Spark Structured Streaming by providing durable state management for distributed transactions and workflow orchestration.
Current Market: The market for durable execution engines is in its very early stages. Interest is growing, but adoption is still limited to cutting-edge organizations and early adopters. This technology sits on the upward slope of the hype cycle, with immense potential for growth.
Future Trends: Expect tighter integrations of durable execution engines with event-driven data streaming platforms such as Apache Kafka, enhanced developer tooling, and broader adoption across industries. The lines between stream processing and distributed workflow orchestration may also blur as tools evolve to address overlapping use cases.
By pairing a durable execution engine with an event-driven architecture, businesses can unlock a new level of reliability and efficiency, making them indispensable for the next generation of distributed systems.
Stay ahead of the curve! Subscribe to my newsletter for insights into data streaming and connect with me on LinkedIn to continue the conversation. And make sure to download my free data streaming ebook with use cases across industries.