Industrial companies are undergoing a major shift. Real-time production data, cloud-native platforms, and AI are transforming how operations and business decisions connect. But to unlock this potential, organizations must break down silos between Operational Technology (OT) and Information Technology (IT). This blog explains how two architectural approaches—Unified Namespace and Data Product—work together to enable scalable, governed, and real-time data flows from factory floor to enterprise applications. Technologies like MQTT, OPC UA and Apache Kafka provide the backbone for this convergence—connecting machines, sensors, and business systems across hybrid edge and cloud environments.
Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases, including architectures and customer stories for hybrid IT/OT integration scenarios.
IT/OT Convergence in Industrial Transformation: From Field Data to Enterprise Value
Across industries such as manufacturing, automotive, energy, and logistics, digital transformation is driving convergence between IT (Information Technology) and OT (Operational Technology). Key initiatives include real-time monitoring of production lines, predictive maintenance using sensor data, virtual PLCs running in the cloud, and the adoption of hybrid edge-to-cloud architectures. These use cases demand a unified, scalable approach to managing data across systems that were traditionally isolated.
As enterprises evolve, they face two major questions:
- How can OT data be structured, accessible, and consistent?
- How can IT turn this data into reusable, trusted, and scalable business assets?
Two major paradigms address these needs: Unified Namespace (UNS) from the OT domain, and Data Product from the IT world.
What Is Unified Namespace (UNS)?
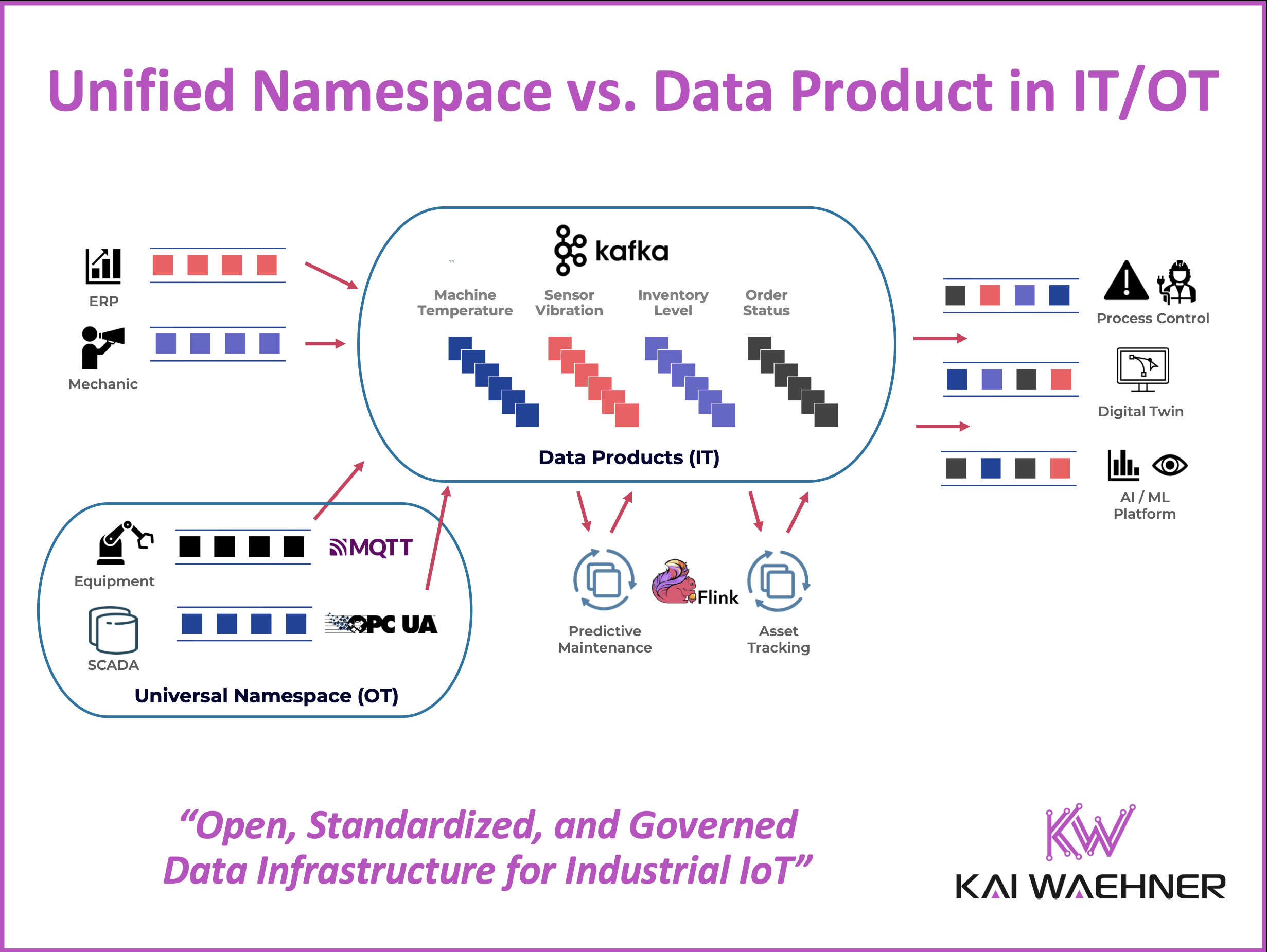
A Unified Namespace is a centralized, hierarchical data structure that aggregates and organizes OT data in real time. It acts as a “single source of truth” for industrial environments, exposing live data from machines, sensors, and PLCs in a structured and accessible way.
Think of UNS as a virtual representation of your physical plant: each machine, line, and sensor has a corresponding namespace entry. Data is continuously updated and available to any authorized subscriber, enabling real-time dashboards, alarms, and analytics.
How Unified Namespace Is Typically Implemented
The Unified Namespace serves as a live mirror of the physical world—updating continuously and accessible to OT tools like SCADA systems or HMI dashboards. It is usually implemented using a hierarchical topic structure in a publish-subscribe system. Each asset—factory, line, machine, or sensor—is assigned a structured path (e.g., factory1/line2/machineA/temperature). Data from controllers, PLCs, or sensors is published to these topics in real time.
Technologies used in UNS include:
- OPC UA, a standard for secure, structured, and vendor-neutral communication in industrial systems. It includes a full object model, making it more complex and resource-hungry than MQTT but richer in semantics.
- MQTT is a lightweight publish-subscribe protocol designed for environments with limited resources and unreliable networks. MQTT enables scalable, low-latency communication across a wide range of embedded and distributed systems. A prime example is connected vehicles, where devices must exchange data in real time despite intermittent connectivity.
- Sparkplug, a specification on top of MQTT that adds structure, metadata, and state awareness. It defines a standard topic namespace and payload format, enabling auto-discovery and better interoperability. However, Sparkplug is MQTT-specific and not widely adopted beyond certain vendors.
While MQTT and OPC UA are the dominant protocols, many industrial environments still run on proprietary legacy protocols, which require gateways or adapters to integrate with a UNS. A core limitation to effectively implementing a Unified Namespace (UNS) is the lack of enforceable data contracts. Without formal, machine-readable schemas—often relying instead on loosely defined JSON, CSV, or ad hoc documentation—it becomes difficult to ensure consistent structure, validate payloads, and support safe evolution over time. This lack of structure makes it hard to scale a UNS reliably across teams, systems, and vendors.
What Is a Data Product?
Data Product come from the world of IT. A Data Product is a reusable, well-governed data asset with clear ownership, metadata, versioning, and access control. Data Product is core to data mesh and shift-left architecture, which aim to treat data like a product rather than a by-product.
The goal is NOT just to move data, but to standardize, govern, and share it across teams and systems—operational and analytical alike.
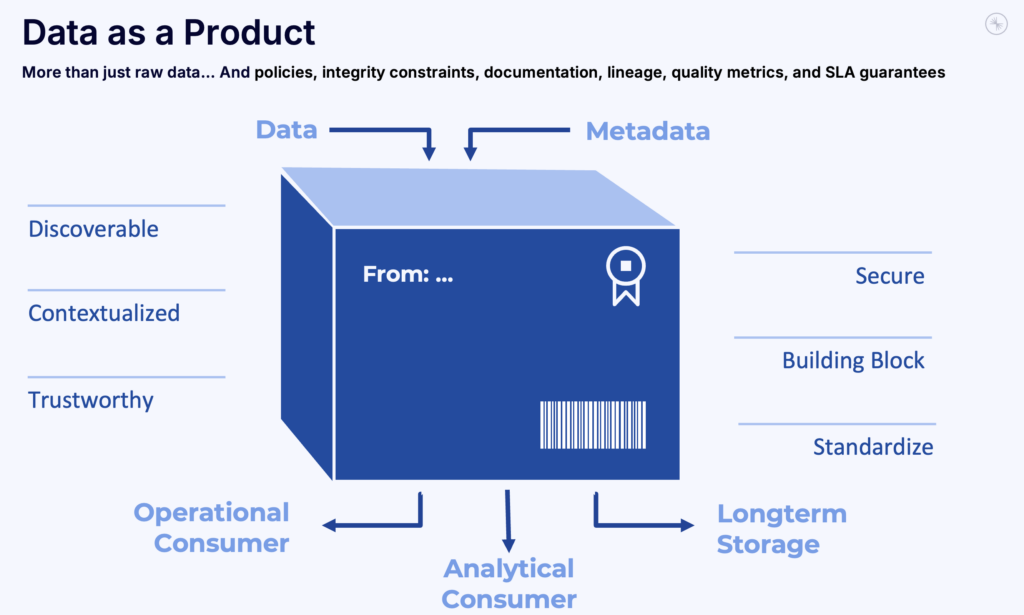
A good data product provides more than just raw data—it includes policies, integrity constraints, documentation, lineage, quality metrics, and SLA guarantees.
Key enabling technologies:
- Apache Kafka, which acts as a high-throughput, durable event streaming backbone. Kafka stores all data in an append-only commit log, making it perfect for both continuous real-time and replayable or batch workloads. This design decouples producers and consumers, enabling loosely coupled microservices and reliable pipelines.
- Kafka Connect to ingest data from systems like databases (Oracle, MongoDB), OT systems (via MQTT or OPC UA connectors), or applications (Salesforce CRM, SAP ERP).
- Schema Registry to enforce data contracts—machine-readable definitions of data structure and serialization. Modern schema registries also support advanced features like attribute-level encryption, policy enforcement through rules engines, and robust error handling with dead letter queues—critical for secure, resilient, and governed data pipelines. Common schema formats include:
- Avro (compact and highly optimized for Kafka)
- Protobuf (widely used in microservices)
- JSON Schema (more human-readable, web-friendly)
Standardized and Secure Data Sharing in Real-Time with Data Products Across Internal and External IT Domains
A well-governed data product enables secure, standardized, and reusable data sharing—within teams, across business units, and even with external B2B partners or via open API.
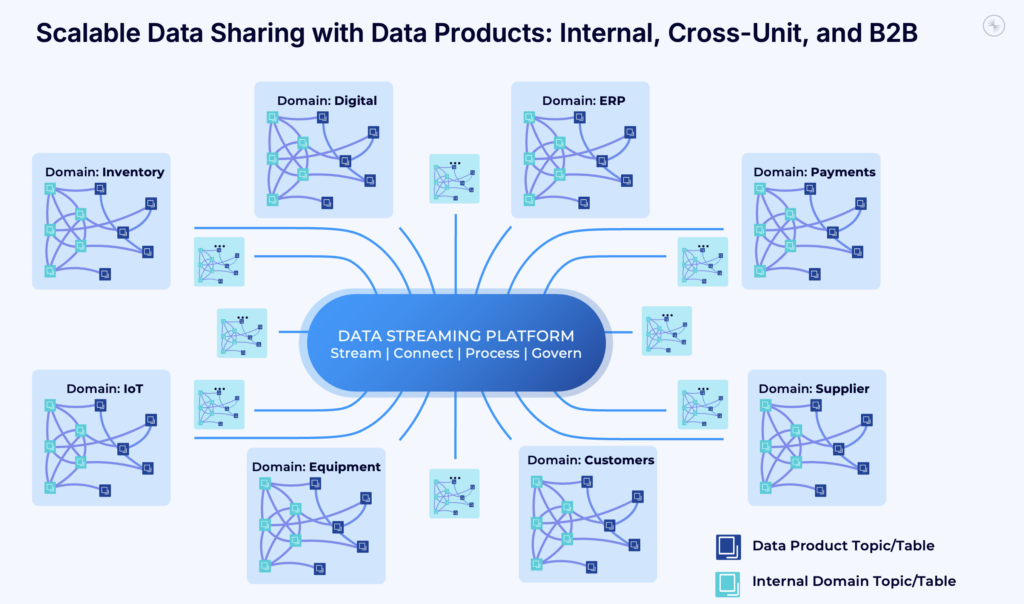
Real-time data sharing with data products is a common use case for data streaming. Read more in my dedicated article: “Streaming Data Sharing with Apache Kafka“.
Open table formats like Apache Iceberg and Delta Lake serve as the foundation for storing this data once and enabling access from various analytical engines and data lake platforms. Downstream consumers—such as Snowflake, Databricks, or business applications—can then rely on consistent and reliable access to the curated product.
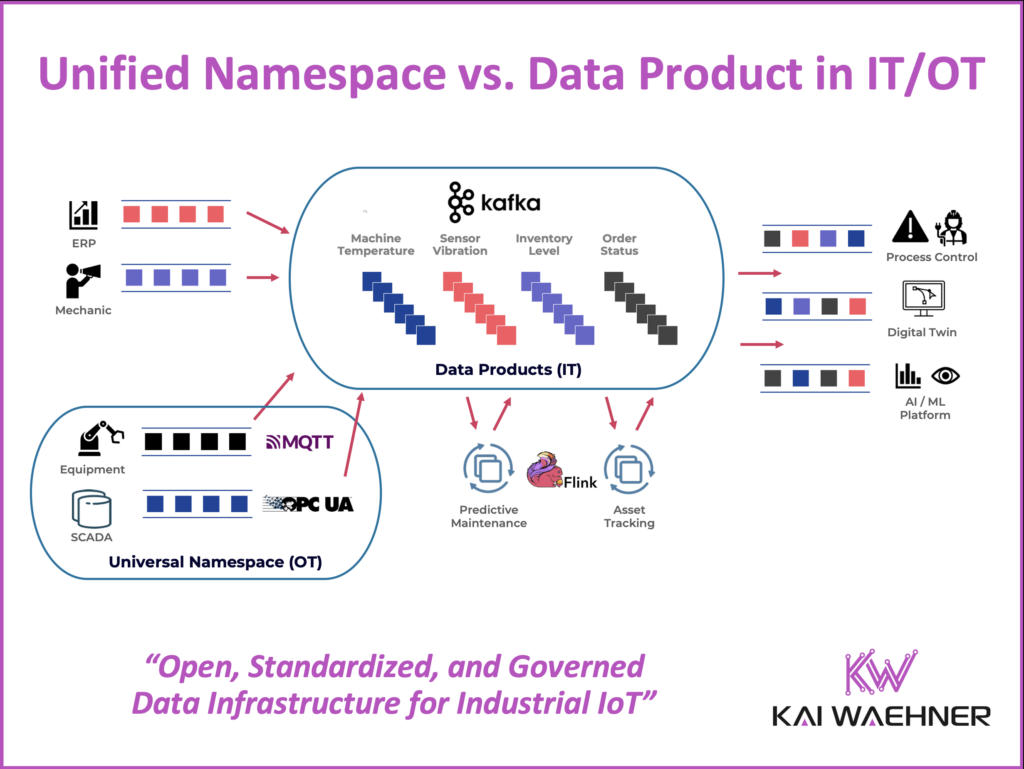
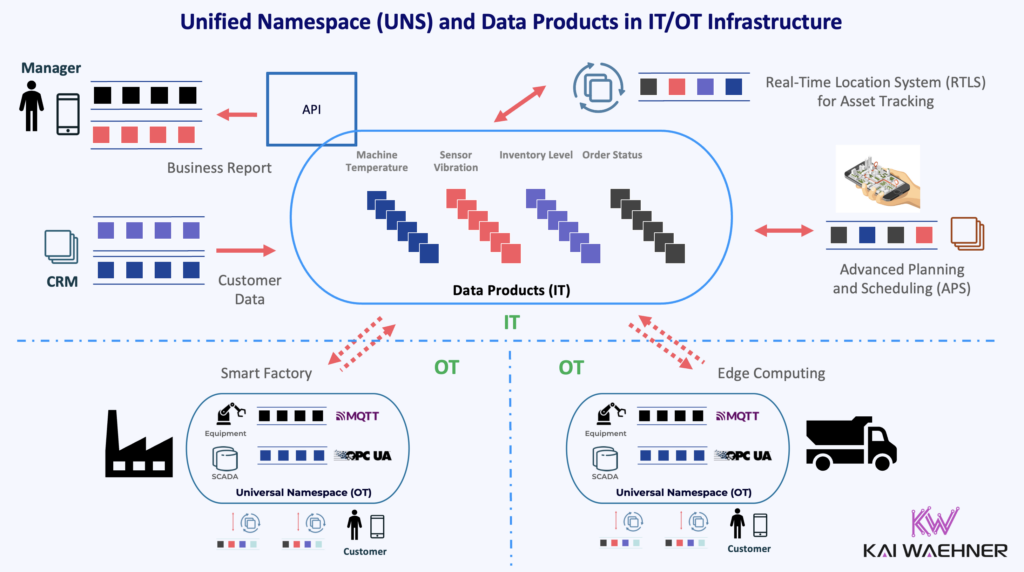
Combining Unified Namespace (OT) and Data Product (IT)
The UNS excels at representing live machine data for operational teams. It’s fast, accessible, and reflects the current state of industrial assets. But on its own, it lacks governance, long-term storage, and integration into enterprise data platforms.
That’s where Data Products come in. They allow OT data to be filtered, enriched, transformed, and exposed to IT for analytics, reporting, and AI use cases. Typically, not all raw sensor data is passed into the data platform. Instead, data is aggregated at the edge or in stream processing tools (e.g., Apache Flink), then published to Kafka topics with schemas enforced by a schema registry.
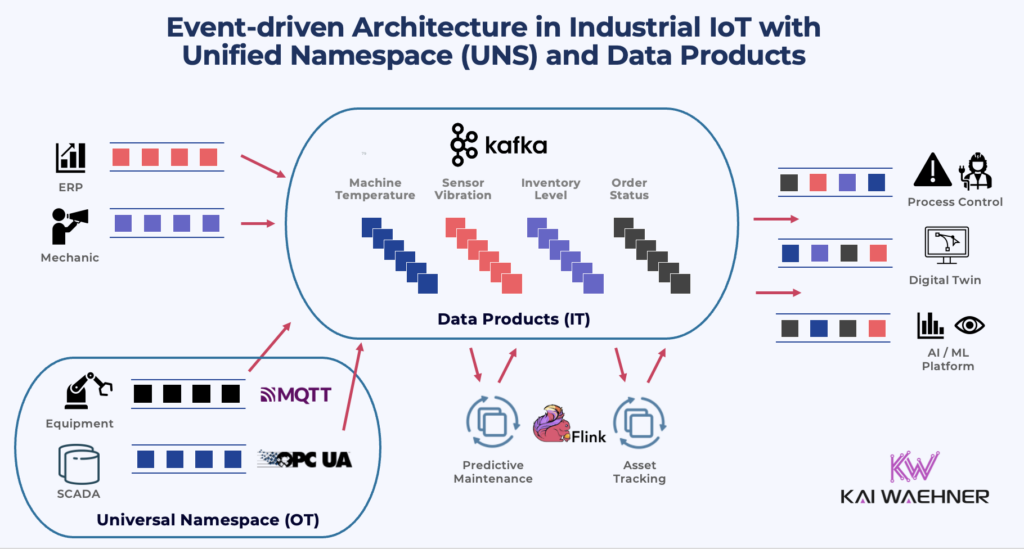
This architecture creates a seamless pipeline:
Edge IoT → Kafka Connect → Kafka Topic → Schema Registry → Data Product -> Operational and Analytical IT Applications
The design allows OT and IT teams to collaborate without compromising their needs. OT gets real-time data with minimal overhead. IT gets high-quality, standardized, and governed data products that are reusable across business functions.
Importantly, this flow is NOT just one-way. The same infrastructure enables bidirectional communication—so actions or decisions triggered in IT systems, such as from a mobile app or AI agent, can be routed back to OT systems for execution in real time. This closes the loop for automation and intelligent control.
When to Use Unified Namespace, Data Product, or Both
Choosing the right architectural pattern depends on the scope, scale, and maturity of your IT/OT integration strategy. While Unified Namespace and Data Product serve different needs, they often work best when used together. Below is guidance on when to apply each.
- Unified Namespace Only: Best suited for small-scale deployments focused on real-time visualization or localized automation. UNS supports SCADA systems, HMI dashboards, and OT monitoring tools. However, it falls short for enterprise-wide data reuse due to limited governance, lack of standardized data contracts, and organizational challenges around cross-team collaboration and data ownership.
- Data Product Only: Makes sense in digital-native IT projects with minimal or no IoT integration. Introducing structure and contracts from the beginning enables better scalability and team collaboration. A Unified Namespace should only be added if it provides real operational value—if you’re simply ingesting data from legacy equipment (e.g., parsing CSV files on a Windows server and ingest that data into Kafka), adding an MQTT broker as a middle layer would introduce unnecessary complexity and cost without clear benefit.
- Unified Namespace + Data Product: This is the standard in modern IT/OT architectures. UNS gives live access to OT data. Kafka bridges the gap to the IT world. Data Products formalize and distribute curated data to operational and analytical IT systems.
Example: From Thousands of Sensors via MQTT to a Universal Data Product in Apache Kafka
In a typical industrial environment, machines may send telemetry—such as temperature, pressure, or vibration data—via MQTT using dynamic topic structures like factory/machine123/sensor/temp or factory/machine456/sensor/temp. This is how a Unified Namespace (UNS) is typically built: it reflects the physical structure of the plant floor in a dynamic, hierarchical topic tree that OT systems like SCADA or HMIs can subscribe to in real time. MQTT supports wildcards such as the * (single-level) or # (multi-level) symbol, allowing consumers to subscribe to patterns like factory/+/sensor/temp to receive data from all machines without needing to manage thousands of explicit topic subscriptions. However, while flexible, this design can still lead to operational complexity when scaled across large environments with high topic cardinality and thousands of unique MQTT topics.
When ingesting this data into IT systems, such fine-grained topic structures become inefficient. Apache Kafka, the backbone for building Data Products, favors more static topic structures for better scalability and governance. In this case, the MQTT data is mapped into a broader Kafka topic (e.g., sensor-data) while preserving machine-specific metadata in the message key, headers, or schema fields. Kafka’s Schema Registry then enforces the structure, enabling operational and analytical downstream systems to reliably process and reuse the data.
This mapping step—from a highly dynamic Unified Namespace to a more standardized “IT-ready” Data Product—is essential. It bridges the flexibility OT needs with the governance and reusability IT demands, creating a scalable, structured, and real-time data pipeline.
IT/OT Integration and Convergence between Unified Namespace and Data Products
Most modern platforms support this convergence out of the box. Some examples of leading vendors in its space:
- HiveMQ offers native integration with Confluent Kafka for MQTT
- PTC Kepware or Inductive Automation (Ignition) and other OT middleware gateways convert OPC UA or proprietary protocols to MQTT or directly to Kafka
- Kafka Connect connectors exist for MQTT, OPC UA, Modbus, and many IT systems by vendors like Confluent
In the IT world, Apache Kafka is the de facto standard for data integration, event-driven architecture, and real-time streaming. It merges the worlds of operational and analytical workloads into one pipeline.
In OT, OPC UA and MQTT are becoming the go-to standard, especially for new hardware and projects. However, the real world still includes lots of legacy equipment and infrastructure. As such, projects often begin brownfield with gateways that transform proprietary protocols into standard ones.
Sparkplug helps structure MQTT payloads, but is limited to MQTT and not widely supported across all vendors. Where possible, it’s better to move toward universal schemas—Avro, Protobuf, JSON Schema—early in the ingestion pipeline, especially once data enters Kafka.
The Pitfalls of Direct OT-to-Data Lake Integration
Directly ingesting raw OT data into a data lake—often promoted by OT middleware vendors—is an architectural anti-pattern. Even if direct connectors to your favorite lakehouse exist, the approach typically leads to high effort, high cost, and poor reusability. Most IT teams don’t need high-frequency telemetry data like one temperature measurement per second. They need curated, contextualized, and governed data.
A data lake is not the single source of truth (even if this data is used for multiple use cases there)—it’s one consumer among many. Pushing data in multiple operational and analytical directions using different tools and logic creates a fragile, spaghetti-like integration landscape. The consequence of direct OT-to-data lake ingestion is Reverse ETL—one of the most concerning and increasingly common anti-patterns, often promoted by data lake vendors.
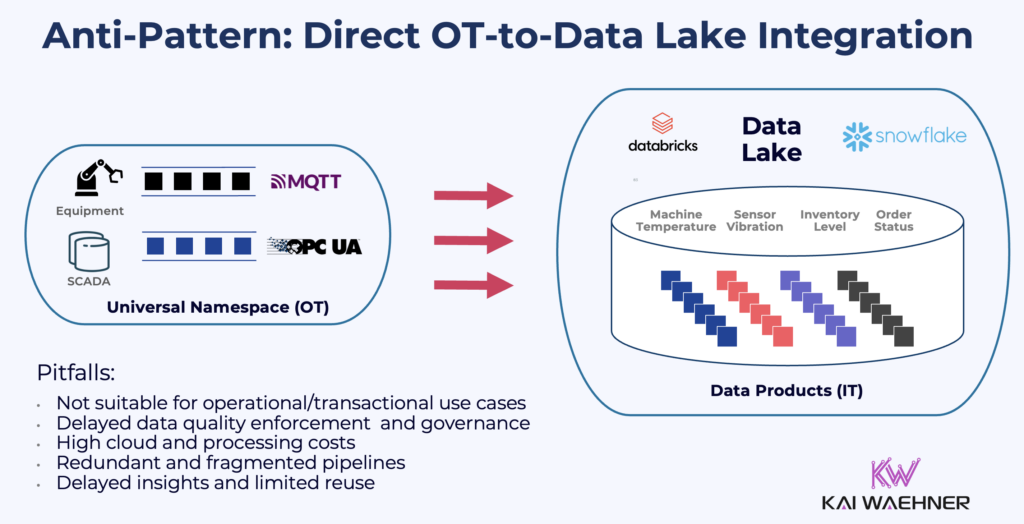
Instead, building a universal data product layer allows all downstream systems—whether analytical or transactional—to consume the same consistent and high-quality data, reducing cost, increasing trust, and accelerating time to value.
This convergence sets the stage for a shift-left architecture—avoiding direct data lake ingestion by applying validation, transformation, and governance earlier in the pipeline.
Shift Left Architecture and Its Impact on IT/OT Use Cases
Shift left is not just a technical strategy—it’s an organizational mindset. It means shifting responsibility for data quality, validation, and governance as early as possible in the lifecycle. In IT/OT environments, this typically begins right after data is created in the OT layer—by machines, PLCs, sensors, or embedded controllers.
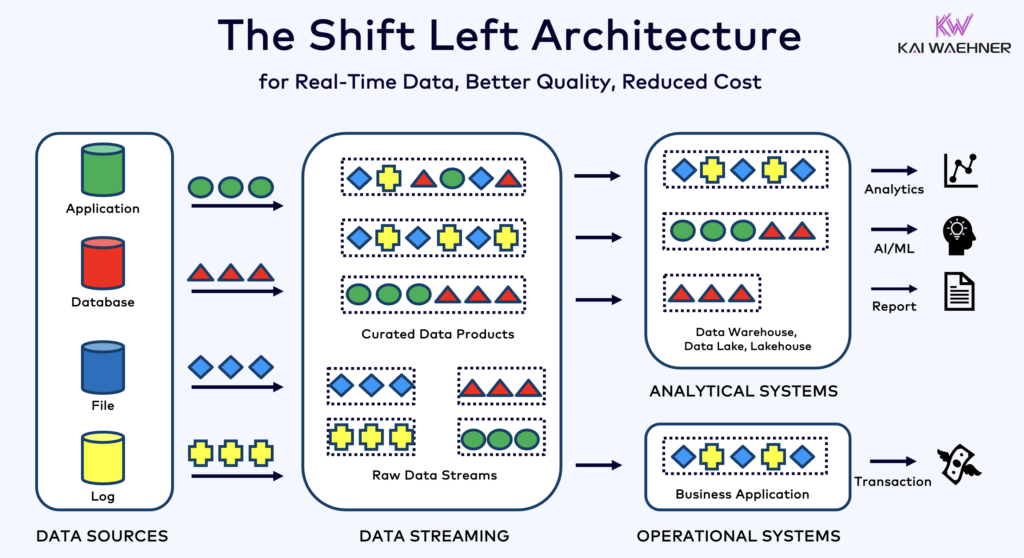
Although it’s often implemented using data streaming technologies like Apache Kafka and Apache Flink, shift left is not tied to any single tool or platform. It applies across architectures, whether on-premises, hybrid, or cloud-native. The goal is always the same: reduce downstream complexity and cost by making upstream systems more intelligent and accountable for the data they generate.
For example, instead of collecting all raw signals from a plant and cleaning them later in a data lake, a shift-left approach would filter, enrich, and validate data at the edge—before it hits centralized platforms. This could happen in an MQTT broker with payload validation, in a Kafka Connect pipeline using schema enforcement, or in a stream processing application running Apache Flink or Kafka Streams on the factory floor or in the cloud.
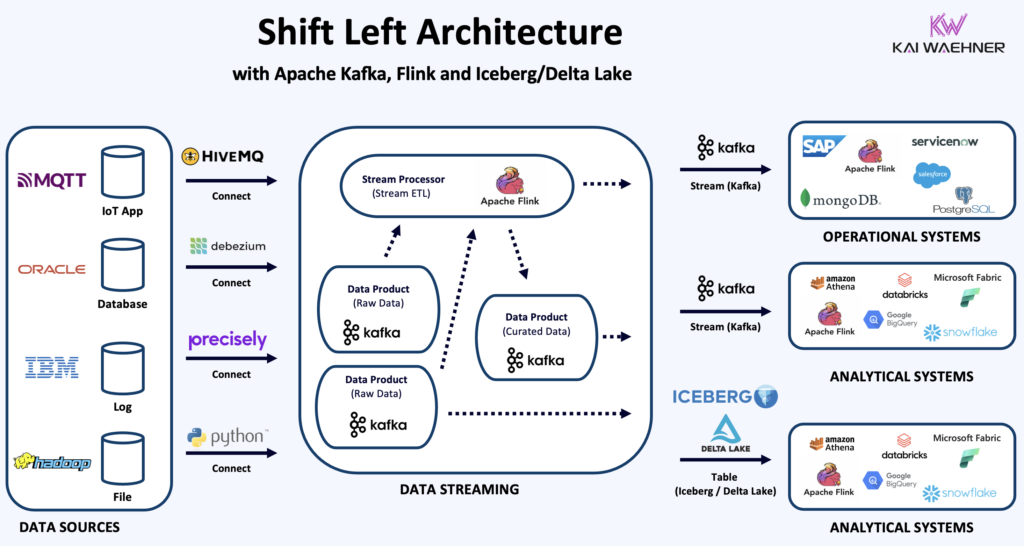
Business value of shift left in IT/OT use cases includes:
- Faster Insights: Real-time validation and enrichment mean curated data is immediately available for decision-making.
- Lower Cost: Clean, purpose-driven data reduces storage and processing needs in downstream systems.
- Improved Trust: Teams across OT, IT, and business functions work with consistent and verified data sets.
- Governance at Scale: Security, access control, and compliance can be applied earlier and more effectively.
- Operational Resilience: Local validation at the edge ensures that only relevant data moves to central systems, reducing noise and failure points.
Siemens: Shift Left Architecture with Data Streaming for IoT and Logistics Use Cases Leveraging Apache Kafka and Flink
Siemens Digital Industries and Siemens Healthineers both apply shift left principles by moving data processing, quality control, and validation closer to the source—enabling real-time innovation across manufacturing, logistics, and healthcare through a modern, cloud-native data streaming platform leveraging Confluent powered by Apache Kafka and Apache Flink.

Shift left is especially valuable when combined with Unified Namespace and Data Products. The UNS gives OT teams the structure and visibility to surface real-time data. Kafka and Schema Registry enable shift-left enforcement of data contracts, turning this data into scalable, governed data products. Together, they create a pipeline that is not only real-time—but also clean, secure, and reusable across the enterprise.
Flexible Deployment Across Edge, Cloud, and Hybrid Environments
This architecture is deployment-agnostic. Whether you’re running OT at the edge and IT in the cloud, or a hybrid model—solutions from both sides (e.g., HiveMQ for MQTT and Confluent for data streaming) can be deployed self-managed or as SaaS, with support for any infrastructure strategy.
In manufacturing, edge deployments are common for machine data processing, local buffering, and safety-critical automation—especially where latency or intermittent connectivity make cloud dependence impractical. For example, real-time quality checks or predictive maintenance algorithms often run on industrial gateways or edge servers close to the production line.
Cloud-based deployments, on the other hand, are often favored in logistics or automotive for global coordination, AI model training, or centralized fleet tracking. Use cases include aggregating sensor data from connected vehicles or warehouse robots for long-term analysis and strategic optimization. Leveraging SaaS or serverless platforms in these scenarios offers elastic scalability, reduced operational overhead, and faster time to market—allowing teams to focus on use cases instead of infrastructure.
Hybrid edge-to-cloud models are increasingly the norm in energy, utilities, and healthcare—where compliance, uptime, and performance must be balanced. For instance, a utility company may use edge analytics for real-time outage detection and cloud infrastructure for regulatory reporting and cross-site forecasting.
My Apache Kafka + MQTT blog series provides real-world success stories that demonstrate how organizations implement these deployment options and combinations effectively—tailored to their operational needs, technical constraints, and strategic goals.
From Raw Signals to Data Products: Structuring OT and IT for Real-Time Business Value
Unified Namespace and Data Products are not competing concepts—they are complementary building blocks of a modern IT/OT enterprise architecture.
A Unified Namespace (UNS) structures live OT data for immediate use in local automation and monitoring. Data Products transform, govern, and deliver that data across the broader organization—for analytics, operations, and business applications.
Combining both is no longer optional.
It’s the foundation for scalable, governed, and real-time data infrastructure in the age of Industry 4.0, GenAI, and cloud-native systems.
As vendors increasingly adopt open protocols and cloud integration becomes the norm, the organizations that succeed will be those that merge these worlds with purpose and discipline.
Across manufacturing, automotive, energy, logistics, and other data-intensive sectors, the guidance is clear:
- Use Unified Namespace to gain real-time visibility in OT.
- Design Data Product to deliver curated insights in IT.
- Connect both using reliable, open, and scalable technology.
Ultimately, this is about more than integration.
It’s about unlocking the full value of your data—safely, reliably, and at scale.
OPC UA, MQTT, and Apache Kafka form the core trio for modern IoT data streaming—connecting industrial devices, enabling real-time communication, and integrating OT with scalable enterprise IT systems.
Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases, including architectures and customer stories for hybrid IT/OT integration scenarios.