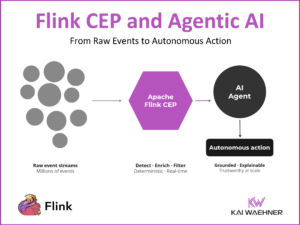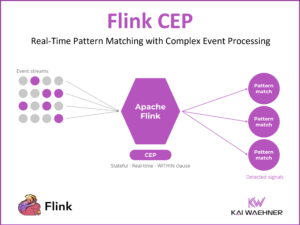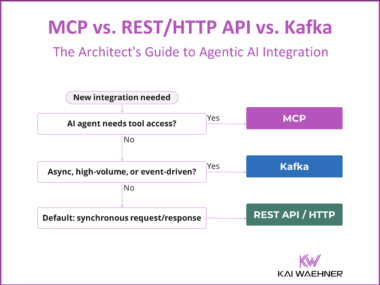
MCP vs. REST/HTTP API vs. Kafka: The Architect’s Guide to Agentic AI Integration
MCP, REST/HTTP APIs, and Apache Kafka are not alternatives. They solve different problems at different layers of the architecture. This article maps the decision: what each technology is built for, where the boundaries are, and where the real gray areas lie. Includes a comparison table and decision tree for architects.