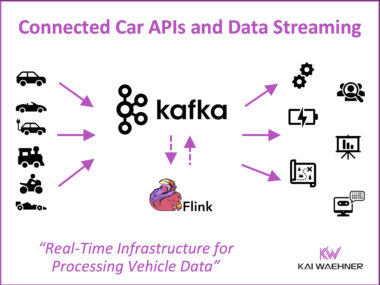
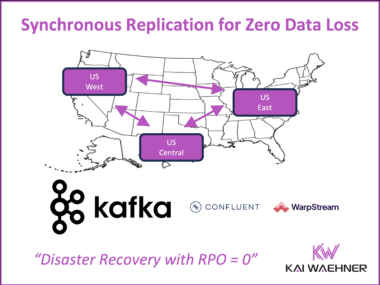
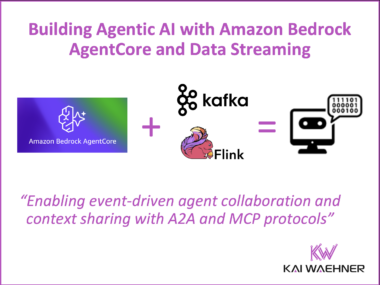
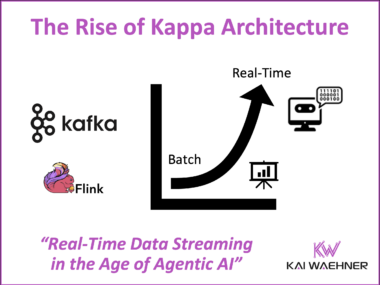
How Data Streaming Powers AI and Autonomous Networks in Telecom – Insights from TM Forum Innovate Americas
AI and autonomous networks took center stage at TM Forum Innovate Americas 2025 in Dallas. Leaders from AT&T, Verizon, and other telcos showed how large-scale AI is transforming customer experience, security, and network operations, while the vision of self-optimizing networks moves closer to reality. At the heart of these advances lies data streaming: real-time, governed data flows that connect OSS/BSS, feed AI with fresh context, and enable automation at scale. This article captures the key insights from the event and explains why data streaming is becoming the central nervous system of modern telecoms.