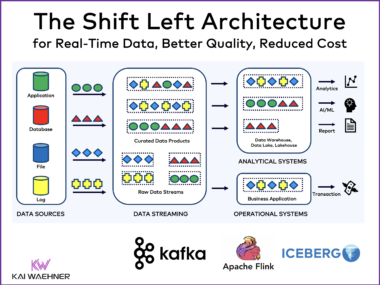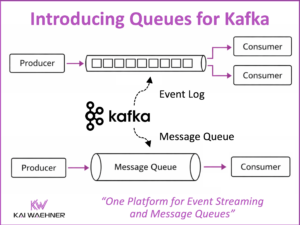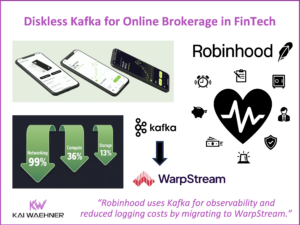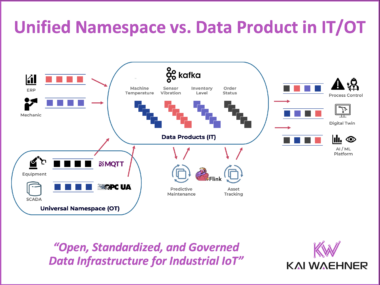
Unified Namespace vs. Data Product in IT/OT for Industrial IoT
Industrial companies are connecting machines, sensors, and enterprise systems like never before. Real-time data, cloud-native platforms, and AI are driving this transformation—but only if silos between OT and IT can be broken down. This blog introduces two key architecture patterns that support IT/OT convergence. The Unified Namespace structures live OT data, while Data Products govern and deliver that data across IT systems. Technologies like MQTT, OPC UA and Apache Kafka play a central role in building scalable, secure, and real-time data pipelines. Combined, these patterns enable clean integration, better data quality, and faster time to value—laying the foundation for success in manufacturing, energy, logistics, and beyond.