Event Streaming with Apache Kafka disrupts the retail industry. Walmart’s real-time inventory system and Target’s omnichannel distribution and logistics are two great examples. This blog post explores a concrete use case as part of the overall story: A hybrid streaming architecture to build smart retail stores for autonomous or disconnected edge computing and replication to the cloud with Apache Kafka.
Disruption of the Retail Industry with Apache Kafka
Various deployments across the globe leverage event streaming with Apache Kafka for very different use cases. Consequently, Kafka is the right choice, whether you need to optimize the supply chain, disrupt the market with innovative business models, or build a context-specific customer experience.
I explored the use cases of Apache Kafka in retail in a dedicated blog post: “The Disruption of Retail with Event Streaming and Apache Kafka“. Learn about the real-time inventory system from Walmart, omnichannel distribution and logistics at Target, context-specific customer 360 at AO.com, and much more.
This post shows a specific example: The smart retail store and its connection to cloud applications. The example uses AWS. Of course, any other cloud infrastructure can be used instead, such as Azure, GCP, or Alibaba. Walgreens is a great real-world example for building smart retail with 5G and mobile edge computing (MEC) deployments to their 9000 stores.
A Hybrid Streaming Architecture with Apache Kafka for the Smart Retail Store
Multiple Kafka clusters are the norm, not an exception! Hybrid architecture requires Kafka clusters in one or more clouds and in local data centers. In the meantime, the trend goes even further: Plenty of use cases exist for Kafka at the edge (i.e., outside the data center).
In retail, the best customer experience and increased revenue require edge processing with low latency. Often, the internet connection is bad, too. Hence, hybrid Kafka architectures make a lot of sense:
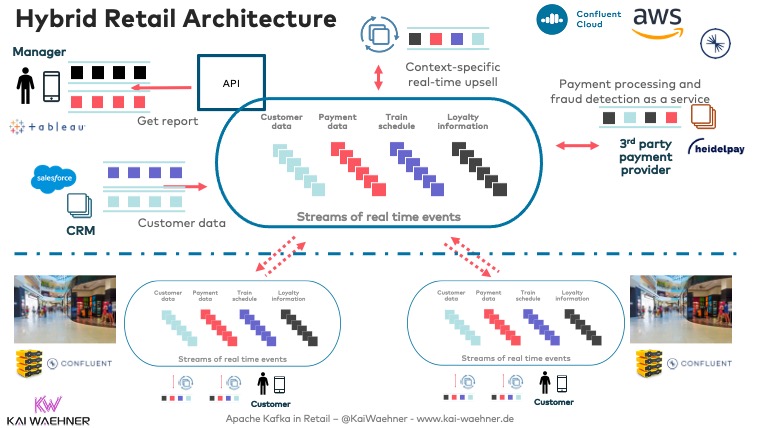
The bi-directional communication between each edge site and a central Kafka cluster is possible with Kafka-native tools such as Mirrormaker 2 or Confluent’s Cluster Linking.
The cloud is best for aggregation use cases, data lakes, data warehouses, integration with 3rd party SaaS, etc. However, many retail use cases need to run at the edge even if there is no internet connection.
Edge Processing and Analytics in the Retail Store
Many retail stores have a bad internet connection that is not stable and has low bandwidth. Hence, the digital transformation in retail requires data processing at the edge:
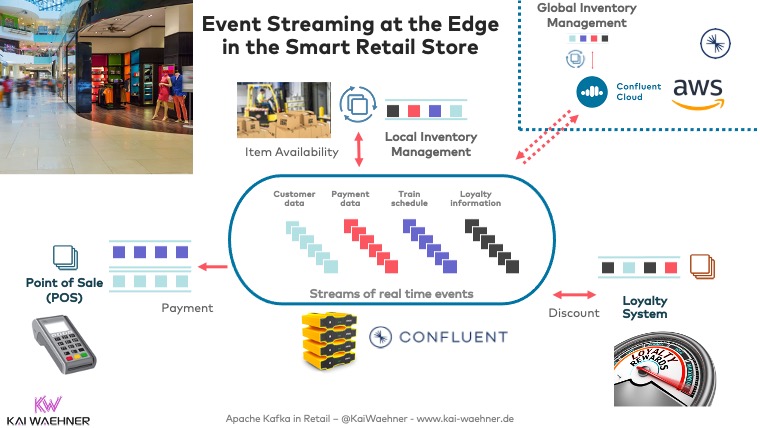
Kafka at the edge includes various use cases in a retail store:
- Low latency transactions like payment processing at the point of sale (Kafka is not hard real-time, but able to process data milliseconds end-to-end)
- Location-based services such as context-specific recommendations and advertisements (including machine learning and model inference)
- Integration with other edge applications and devices (sensors, cameras, mobile apps, etc.)
- Pre-processing before replication to the cloud (filtering, aggregations, etc.) to reduce costs
- Buffering and backpressure handling (real decoupling between applications and between edge and cloud)
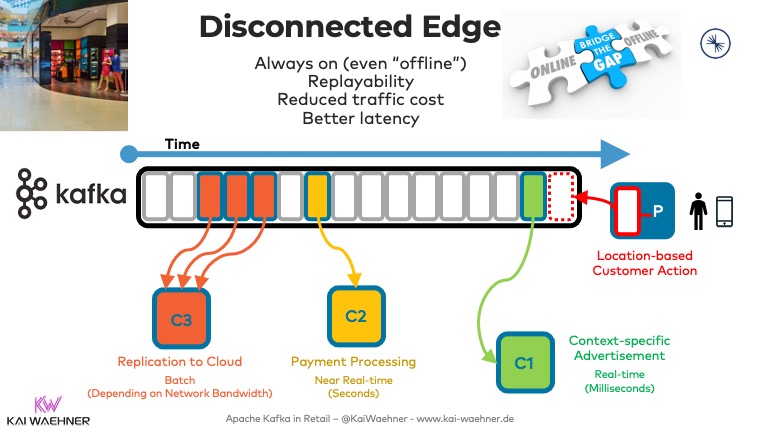
The Autonomous (or Disconnected) Edge: An Offline Retail Store
Many architectures don’t do real edge processing. They just connect the clients at the edge to the backends in the cloud. This is fine for some use cases. However, several good reasons exist to deploy Kafka at the edge beyond replication to the cloud:
- Always on – process edge data even if you don’t have a (good) internet connection
- Backpressure handling – decouple the edge from the cloud if there is no stable connection to the cloud
- Reduced traffic costs – it does not make sense to replicate all sensor data etc. to the cloud
- Low latency and edge data processing are key for some use cases – for instance, context-specific and location-based customer notifications don’t make sense if the person already walked away from a product or even out of your store already (please note that Kafka is NOT hard real-time, though!)
- Analytics – Machine Learning in the cloud is great to train models (and Kafka is a key piece of the ML story, too), but the model inference at scale in real-time (with Kafka) can only happen at the edge
With Kafka at the edge, you can solve all these scenarios with a single technology, including non-real-time use cases:
Real-World Example: Swimming Retail Stores at Royal Caribbean
Royal Caribbean is a cruise line. It operates the four largest passenger ships in the world. As of January 2021, the line operates twenty-four ships and has six additional ships on order.
Royal Caribbean implemented one of the most famous use cases for Kafka at the edge. Each cruise ship has a Kafka cluster running locally for use cases such as payment processing, loyalty information, customer recommendations, etc.:
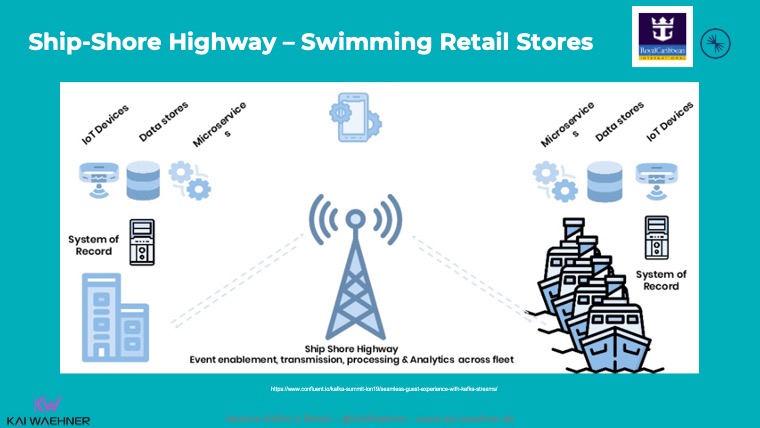
All the reasons I described above apply for Royal Caribbean:
- Bad and costly connectivity to the internet
- The requirement to do edge computing in real-time for a seamless customer experience and increased revenue
- Aggregation of al the cruise trips in the cloud for analytics and reporting to improve the customer experience, upsell opportunities, and many other business processes
Hence, a Kafka cluster on each ship enables local processing and reliable, mission-critical workloads. The Kafka storage guarantees durability, no data loss, and guaranteed ordering of events – even though they are processed later. Only very critical data is sent directly to the cloud (if there is connectivity at all). All other data is replicated to the central Kafka cluster in the cloud when the ship arrives in a harbor for a few hours. A stable internet connection and high bandwidth are available before leaving for the next trip again.
Obviously, the same architecture can be applied to traditional retail stores on land in malls or other buildings.
Kafka at the Edge is the New Black!
The “Kafka at the edge” story is coming up more and more. Obviously, it is not just relevant for retail stores but also for bank branches, restaurants, factories, cell towers, stadiums, and hospitals.
5G will be a key reason for Kafka’s success at the edge (and edge computing in general). The better you can connect things at the edge, the more you can do with it there. The example of building a smart factory with Kafka and a private 5G campus network goes into more detail. Streaming machine learning with Apache Kafka at the edge is the new black! This is true for many use cases, including advanced planning, payment and fraud detection, or customer recommendations.
What are your experiences and plans for event streaming in the retail industry or with Kafka at the edge (outside the data center)? Did you already build applications with Apache Kafka? Check out the “Infrastructure Checklist for Apache Kafka at the Edge” if you plan to go that direction!
Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.





