
The oil & gas and mining industries require edge computing for low latency and zero trust use cases. Most IT architectures are hybrid with big data analytics in the cloud and safety-critical data processing in disconnected and often air-gapped environments. This blog post shares a panel discussion that explores the challenges, use cases, and hardware/software/network technologies to reduce cost and innovate. A key focus is on the open-source framework Apache Kafka, the de facto standard for processing data in motion at the edge and in the cloud.

Apache Kafka at the Edge and in Hybrid Cloud
I explored the usage of event streaming at the edge and in hybrid cloud scenarios in lots of detail in the past. Hence, instead of yet another description, check out the following posts to learn about use cases and architectures:
- Use Cases and Architectures for Kafka at the Edge
- Apache Kafka is the New Black at the Edge in Industrial IoT, Logistics, and Retailing
- Infrastructure Checklist for Apache Kafka at the Edge
- Architecture patterns for distributed, hybrid, edge, and global Apache Kafka deployments
- Kafka for Cybersecurity in Zero Trust and Air-Gapped Environments
Panel Discussion: Kafka, Network Infrastructure, Edge, and Hybrid Cloud in Oil and Gas
Here is the panel discussion. The conversation includes the software and the hardware/infrastructure/networking perspective. It is a great mix of exploring use cases from the oil&gas and mining industries for processing data in motion and technical facts about communication/radio/telco infrastructures. I think it was really a great mix of topics that are heavily related and depend on each other to deploy a project successfully.
Speakers:
- Andrew Duong (Confluent): Moderator
- Kai Waehner (Confluent): Expert on hybrid software architectures and data in motion
- Dion Stevenson (Tait Communications): Expert on hardware and network infrastructure
- Sohan Domingo (Tait Communications): Expert on hardware and network infrastructure
Now enjoy the discussion and feel free to share any thoughts or feedback:
You are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
Kafka in the Energy Sector including Oil and Gas, Mining, Smart Grids
An example architecture for hybrid event streaming in the oil and gas industry can look like the following:
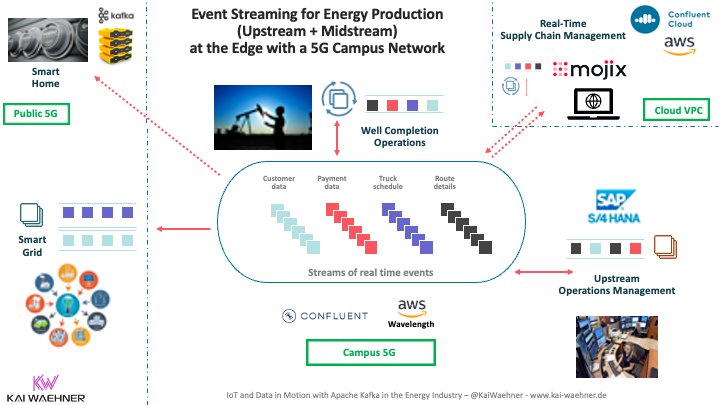
If you want to learn more about event streaming with Apache Kafka in the energy industry (including oil and gas, mining, smart grids), check out the following blog post:
Apache Kafka for Smart Grid, Utilities and Energy Production
Notes about the Kafka, Edge, Oil, and Gas, Mining Conversation
If you prefer reading or just listening to a few of the sections, here are some notes about the flow of the panel discussion:
Kafka for Next-Generation Edge Computing
The energy industry, including oil&gas and mining, is super interesting from a technical perspective. It requires edge and cloud computing. Upstream, midstream, and downstream is a complex and safety-critical supply chain. Processing data in motion with Apache Kafka leveraging various network infrastructures is a great opportunity to innovate and reduce costs across various use cases.
Do you already leverage Apache Kafka for processing data in motion in the oil and gas, mining, or any other industry? How does your (future) edge or hybrid architecture look like? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
