
Should I use Apache Camel or Apache Kafka for my next integration project? The question is very valid and comes up regularly. This blog post explores both open-source frameworks and explains the difference between application integration and event streaming. The comparison discusses when to use Kafka or Camel, when to combine them, when not to use them at all. A decision tree shows how you can quickly qualify out one for the other.
The history of application integration and event streaming
My personal history and experience in application integration and event streaming are the following. It shows my background and how I see the integration and data streaming markets.
A discussion that started over a decade ago…
With my background of work in the last decade at Talend, TIBCO, and Confluent, the comparison between Camel and Kafka is very exciting as I have spent a lot of time with both open-source frameworks:
Apache Camel powered Talend ESB. Talend had a visual coding tool to design Camel routes with code generation. Unfortunately, the tool’s primary focus was Talend Data Integration (ETL and batch). The Camel-powered ESB code was integrated, but it was neither perfect nor complete.
TIBCO BusinessWorks competed with Talend ESB while TIBCO StreamBase competed with other stream processing solutions. The Kafka ecosystem came up more and more in conversations with customers.
 I posted about “When to use Apache Camel” in 2011 already. In 2012, I did my first talk at an international software conference in the US. The name of the conference? CamelOne! A forum only about Apache Camel. What an exciting time. Claus Ibsen, THE Camel guy, wrote an excellent summary of CamelOne 2012 in Boston.
I posted about “When to use Apache Camel” in 2011 already. In 2012, I did my first talk at an international software conference in the US. The name of the conference? CamelOne! A forum only about Apache Camel. What an exciting time. Claus Ibsen, THE Camel guy, wrote an excellent summary of CamelOne 2012 in Boston.
In my conference summary, I talked about my two talks. One of them covered a comparison between Apache Camel, Spring Integration, and Mulesoft ESB. The presentation has over 35000 views, and the number still goes up today.
… from application integration to event streaming
Over time, the buzzword “big data” came up more and more. I spent some time at Talend and TIBCO to learn new programming concepts such as Map-Reduce and Shuffling, mainly powered by Apache Hadoop and Apache Spark. The big data ecosystem snowballed with tens of frameworks such as Hive, HBase, Pig, and many more.
However, the first people realized that real-time data beats slow data in almost all use cases. The Lambda architecture was invented to separate real-time workloads from batch workloads. Event Streaming was born. Apache Kafka became the de facto standard for data streaming. Like CamelOne a decade ago, Kafka Summit is the one-stop-show for Kafka use cases, architectures, and success stories. Contrary to the small CamelOne, Kafka Summit is a global event with events across the globe, plus online events.
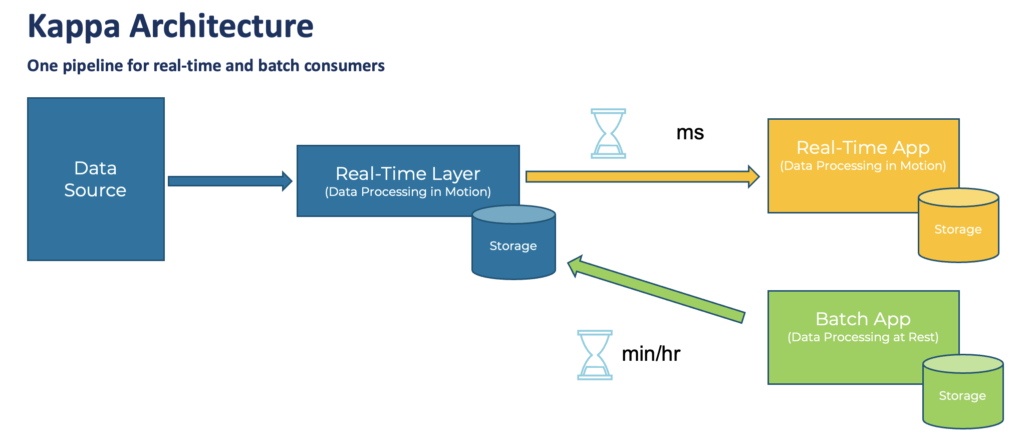
Data in motion with the Kappa architecture replacing Lambda
In 2014, a guy called Jay Kreps (few people knew him) was already questioning the Lambda architecture. Instead, he proposed to provide a single real-time layer to provide data for real-time and batch consumers. The Kappa architecture was born. Today, the Kappa architecture is mainstream, replacing Lambda. Various vendors adopt Kafka in the meantime.
Confluent became the clear leader in the event streaming software category. Confluent Platform is powered by Apache Kafka. The focus is on event streaming. That’s different from most other vendors like Cloudera; they focus on 10-20 frameworks or products and try to combine and integrate them somehow. Today, Confluent Cloud is a complete game-changer providing Apache Kafka and its ecosystem for application integration and stream processing as a serverless cloud offering.
This is where we are today in 2022. Application integration (= Camel) and event streaming (= Kafka) play a critical role in every modern enterprise architecture. Open-source is widely adopted and usually preferred compared to proprietary solutions for various reasons, including avoiding vendor lock-in. That’s true for self-managed and serverless cloud offerings.
Hence, the question arises: Should I use Apache Camel for application integration or Apache Kafka for event streaming? Or both? Or does one solve the other, too? These questions will be answered in the following sections, concluding with a decision tree to help you make the right choice for your project.
Let’s look at the similarities between Camel and Kafka, when to use which framework, when and how to combine them, and when not to use them at all.
Features in Apache Camel AND Apache Kafka
Camel and Kafka have many positive and negative characteristics in common. Hence, it is no surprise that people compare the two frameworks:
- Open source under Apache 2.0 license
- Vibrant community and adoption in the industry
- Mature framework with deployments in enterprises across the globe
- Fixing point-to-point spaghetti architectures with a central integration backbone
- Open architecture and extensibility with custom functions and connectors
- Small and big deployments possible, plus single-node deployments for non-mission-critical use cases
- Re-engineered and optimized for cloud-native deployments (container, Kubernetes, cloud)
- Connectivity to any technology, API, communication paradigm, and SaaS
- Transformation of any data types and formats
- Processes transactional and analytical workloads
- Domain-specific language (DSL) for message at a time processing, with similar logic such as aggregation, filtering, conditional processing
- Relative complex frameworks because of their robust feature set, hence not suitable for solving a minor problem
- Not a replacement of a database, data warehouse, or data lake
Beyond the similarities, Kafka and Camel have very different sweet spots built to solve distinct problems. Hence, comparing these two tools is a bit comparison of apples and oranges. Some minor projects might use one or the other to solve the problem, but critical enterprise projects show the differences more quickly.
When to use Apache Camel?
The mission of Camel
Apache Camel is an integration framework. It solves a particular problem: Data integration between different applications, APIs, protocols, and communication paradigms. This concept is often called application integration or enterprise integration. Camel implements the famous Enterprise Integration Patterns (EIP). EIPs are based on messaging principles.
Camel’s strengths
- Event-based backbone based on well-known and adopted EIP concepts
- Connectivity to almost any API
- Integration, processing, and routing of information with an intuitive domain-specific language (DSL) with a focus on integration; providing the ability of composability in a programming context for finer grain control in code for doing conditional logic or transformations/reformatting
- Powerful routing capabilities with many built-in EIPs
- Many deployment options (standalone, web container, application server, Spring, OSGi, Kubernetes via the Camel K sub-project) – okay, I guess some options are not relevant in this decade anymore 🙂
- Lightweight alternative to proprietary ETL and ESB tools
Camel’s weaknesses
- Only a “routing machine”, i.e., not built for long-term storage (additional cache or storage needed), for that reason, Camel is not the right choice for a central nervous system like Kafka
- No stream processing (like you know it from Kafka Streams or Apache Flink)
- Limited scalability, not built for massive volumes of data
- No powerful visual coding like you know it from proprietary ETL/ESB/iPaaS tools
- No serverless cloud offering, with that also not competing with other iPaaS offerings
- Red Hat is the only vendor supporting it
- Built to be deployed in a single data center or cloud region, not across hybrid or multi-cloud scenarios
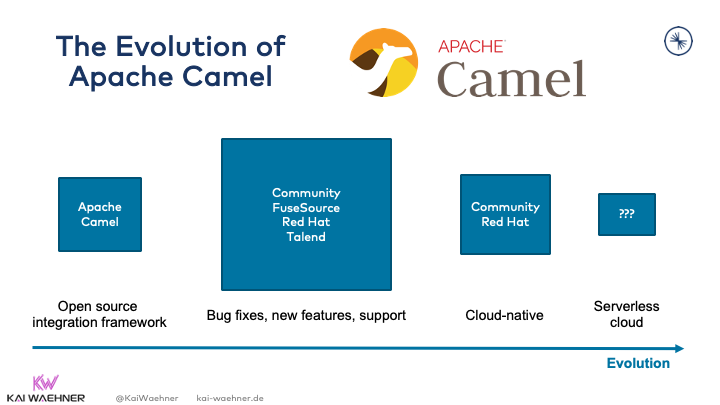
The evolution of Apache Camel
Camel is widely adopted and has a strong community. Unfortunately, from a vendor and support perspective, the offerings declined in the last few years. One of the most significant pain points: I still don’t see a serverless cloud offering anywhere today:
Camel TL;DR
Camel is an application integration framework to connect different applications and interfaces. Camel is NOT built for processing data in motion continuously, i.e., stream processing. Hence, it should be compared to ETL and ESB tools, not data streaming technologies like Kafka, Kinesis, or Flink. If you look for a serverless cloud offering, you are out of luck. If you look for vendor support, Red Hat is the only option.
When to use Apache Kafka?
The mission of Kafka
Real-time data beats slow data at any scale. The event streaming platform enables processing data in motion. Kafka is the de facto standard for event streaming, including messaging, data integration, stream processing, and storage. Kafka provides all capabilities in one infrastructure at scale. It is reliable and allows to process analytics and transactional workloads.
Kafka’s strengths
- Event-based streaming platform
- A unique combination of pub/sub messaging, data processing, data integration, and storage in a single framework
- Built for massive volumes of data and extreme scale from the beginning, with that a single framework can be used for transactional (low volume) and analytics (high volume) use cases
- True decoupling between producers and consumers because of its storage component makes it the de facto standard for microservice architectures
- Guaranteed ordering of events in the distributed commit log
- Distributed data processing with fault-tolerance and recoverability built-in
- Replayability of events
- The de facto standard for event streaming
- Built with hybrid and multi-cloud data replication in mind (with included tools like MirrorMaker and separate, more advanced, and more straightforward tools like Confluent Cluster Linking)
- Support from many vendors, including Confluent, Cloudera, IBM, Red Hat, Amazon, Microsoft, and many more
- Paradigm shift: Built to process data in motion end-to-end from source to one or more sinks
Kafka’s weaknesses
- Paradigm shift: Enterprises need to learn and understand the added value of event streaming, a new software category that enables new use cases but also requires different design patterns and operations approaches
- No powerful visual coding like you know it from proprietary ETL/ESB/iPaaS tools
- Limited out-of-the-box routing capabilities (Kafka Connect SMT or Kafka Streams / ksqlDB app do the job very well, but not as simple as Camel)
- Complex operations (if you run it by yourself instead of using 3rd party tools or even better a serverless cloud offering)
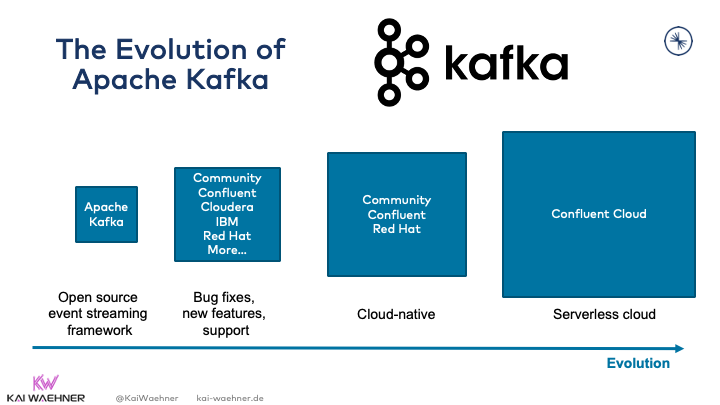
The evolution of Apache Kafka
Kafka was built at LinkedIn to process high volumes of data, as no other open-source framework could do this. Kafka found quick adoption after LinkedIn open-sourced it. Several vendors adopted Kafka and added it to their product portfolio. Some vendors just added Kafka for the sake of having it. Others innovated and used additional tools to make Kafka cloud-native for the next generation of event streaming. Kafka as a serverless cloud offering is a critical piece of many modern enterprise architectures today:
Kafka TL;DR
Kafka is an event streaming platform to process data in motion continuously. If you “just” need an integration framework to route data from a source to one or more sinks (= ETL / ESB), then Camel can be used, too. However, Kafka kills two birds with one stone (= integrating data AND processing it in motion where needed).
Plenty of Kafka offerings are available on the market. Check out the Apache Kafka landscape and comparison to understand the differences between offerings from Confluent, Cloudera, IBM, Red Hat, Amazon, Microsoft, and others.
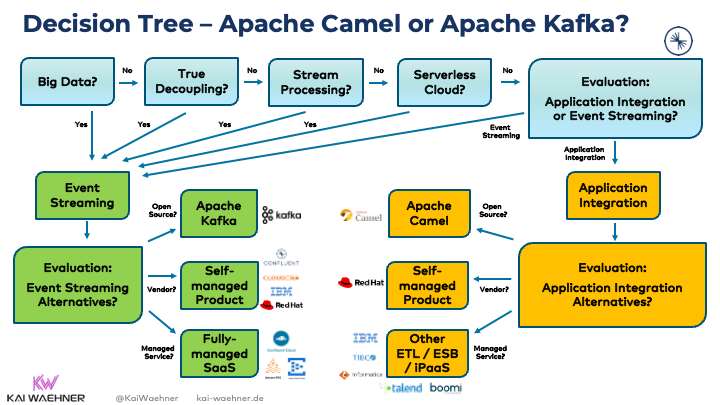
Decision tree – Camel or Kafka?
The above sections explored when to use Camel and Kafka. So far, so good. Nevertheless, both frameworks overlap with their capabilities. Let’s get some help to choose the right one in that case.
Qualify out – the easiest way to start an evaluation!
The easiest way to decide on a specific option is to qualify out other frameworks that cannot fulfill the requirements.
Therefore, do you need
- Big data processing?
- A storage component for true decoupling and replayability of events?
- Stateless or stateful stream processing?
- A serverless cloud offering?
The above section discussed these differentiators of Kafka. In all these cases, you can qualify out Camel. It does not fulfill these requirements. These requirements are not necessarily a complete list. And you might also find a few aspects to qualify out Kafka from the beginning. Hence, you could also start from the Camel perspective and ask yourself: When should I not use Kafka. But I think it is easier the other way round.
Qualifying out solutions because of their limitations makes the decision tree and evaluation process much easier from the beginning.
Decision Tree for Camel and Kafka
Here is my decision tree to find out if Camel or Kafka is the right choice and what vendors you could evaluate:
When to use Camel and Kafka together?
It is possible to use Camel and Kafka together in a single integration architecture. Should you do that? Two options exist. One makes more sense than the other:
Kafka for event streaming and Camel for ETL
Camel and Kafka integrate well with each other. The native Kafka component of Camel is the best native integration point as a bridge between both environments:
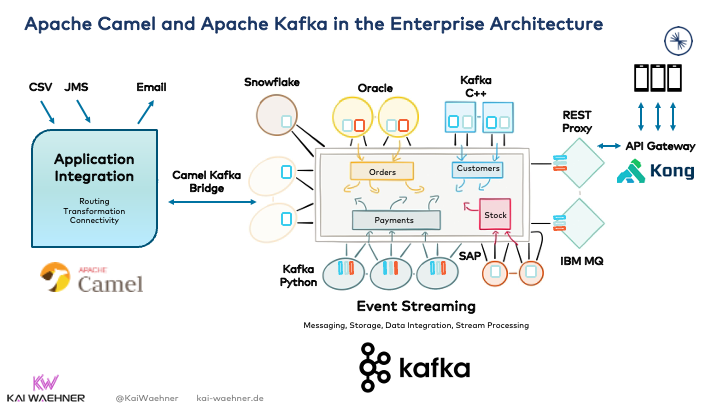
The above architecture shows how Camel and Kafka live next to each other. Camel is used in a business domain for application integration. Kafka is the central nervous system between the Camel integration application and many other applications. I also added Kong as API Gateway to clarify that Camel or Kafka is not a silver bullet to solve every problem.
Once again, the vast advantage of Kafka as central integration layer is its unique combination of characteristics within a single infrastructure, including:
- Real-time messaging at any scale
- Storage for true decoupling between different applications and communication paradigms
- Built-in backpressure handling and replayability of events
- Data integration
- Stream processing
Real-time data replication across hybrid and multi-cloud is not shown in the above picture but is also part of the enterprise architecture out-of-the-box leveraging take Kafka protocol.
With true decoupling within modern microservice architecture, each business team can decide whether they need application integration (using Camel) or event streaming (using Kafka). Often, both could be used. Additional questions around single vs. multi frameworks and APIs, vendor support, scalability needs, and other characteristics need to be evaluated to make the right choice for your business problem.
Camel connectors embedded into Kafka Connect
There is another way to combine Kafka and Camel: The “Camel Kafka Connector” sub-project of Apache Camel. Don’t get confused. This feature is not the Kafka component (= connector) of Camel! Instead, it is a relatively new initiative to deploy camel components into the Kafka Connect infrastructure.
The obvious benefit: This way, you get hundreds of new connectors “for free” within the Kafka ecosystem. This capability sounds excellent. And it is!
However, consider the total cost of ownership and the overall efforts using this approach. Application integration is one of the most challenging problems in computer science – especially if you talk about transactional data sets that require zero data loss, exactly-once semantics, and no downtime. The more components you combine in the end-to-end data flow, the harder it gets to keep your performance and reliability SLAs.
Hence, using Camel components within Kafka Connect has a considerable disadvantage: Combining two frameworks with complexities and different design concepts. Just a few examples:
- Kafka world: Partitions, Offsets, Leader and Follower, Key/Value/Header, connectors (based on Kafka Connect), Bootstrap Server, ConsumerRecord, Retention Time, etc.
- Camel world: Routes, RouteBuilder CamelContext, Exchange, Processor, components (Camel connectors), Endpoints, Type Converters, Registry, etc.
Please think twice before mixing two integration tools that are powerful but complex on their own. Getting this running is just one piece of the puzzle (the simple part). Don’t forget end-to-end testing, resiliency, SLAs, support across technologies and APIs. Even buying support for Camel and Kafka from Red Hat (i.e., a single vendor) does not improve this approach.
It is likely better to take the business logic and API calls out of the Camel component and copy it into a Kafka Connect connector template to run the integration natively with only Kafka code. This workaround allows a clean architecture, end-to-end integration with a single framework, a single vendor behind it, and much easier testing / debugging / monitoring.
TL;DR: I recommend only using the “Camel Kafka Connector” sub-project if the following options do not work:
- Use only Apache Camel for application integration
- Leverage Apache Kafka for event streaming and application integration
- Choose separate deployments of Camel and Kafka and use the Camel-Kafka-Bridge
When NOT to use Camel or Kafka at all?
Once again, the easiest way for your evaluation to start is qualifying out tools that do not work to solve the problem.
Both Camel and Kafka are NOT built for the following scenarios:
- A proxy for millions of clients (like mobile apps) – but native proxies (like a REST or MQTT Proxy for Kafka) exist for some use cases.
- An API Management platform – but these tools are usually complementary and used to create life cycle management or monetize APIs deployed with Camel or Kafka.
- A database for complex queries and batch analytics workloads
- an IoT platform with features such as device management – but direct native integration with (some) IoT protocols such as MQTT or OPC-UA is possible and the approach for (some) use cases.
- A technology for hard real-time applications such as safety-critical or deterministic systems – but that’s true for any other IT framework, too. Embedded systems are a different software than Camel or Kafka!
I wrote a very detailed post about this topic from a Kafka perspective. It maps almost 1:1 to the Camel world, too (and any related technology such as Flink, Spark, Pulsar, etc.): “When NOT to use Apache Kafka?”
Apache Camel vs. Apache Kafka – Who is the winner?
Simple answer: Both!
When you compare apples and oranges, you might become happy when you are hungry as both are good to eat. The same is true for Camel and Kafka. Both can do application integration. But they serve very different needs.
Many integration scenarios can use Camel or Kafka.
Camel is the right tool if you need to integrate data within an application context or business unit (with no need for stream processing, true decoupling, replayability, large scale, replication across data centers or cloud regions).
Kafka is the central event-based nervous system across business units, regions, and hybrid clouds. Kafka is all about event streaming. Application integration is just a piece of this puzzle. On the other side, I have seen plenty of integration projects powered by Apache Kafka. It is often replacing other middleware. That’s true for ETL/ESB legacy modernization and in discussions about using a cloud-native iPaaS.
Do you use Camel or Kafka today? What use cases? How do you decide which one to choose? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
