

Generative AI (GenAI) and Data Streaming
Let’s set the context first to have the same understanding of the buzzwords.
[Note: My ChatGPT iPhone app generated this section. I slightly shortened and adjusted the content afterward. GenAI is perfect for summarizing existing content so that authors can spend time on new content (that ChatGPT does not know yet).]
Natural Language Processing (NLP)
ChatGPT, what is NLP?
NLP stands for Natural Language Processing. It is a subfield of artificial intelligence (AI) that focuses on interactions between computers and human language. NLP enables computers to understand, interpret, and generate human language in a meaningful and valuable way.
Natural Language Processing involves a range of tasks, including:
- Text Parsing and Tokenization: Breaking down text into individual words or tokens.
- Named Entity Recognition (NER): Identifying and classifying named entities such as people, organizations, locations, and dates in the text.
- Sentiment Analysis: Determining the sentiment or emotional tone expressed in text, whether positive, negative, or neutral.
- Machine Translation: Translating text from one language to another.
- Question Answering: Building systems that can understand and answer questions posed in natural language.
- Text Generation: Creating human-like text or generating responses to prompts.
NLP is crucial in applications such as chatbots, virtual assistants, language translation, information retrieval, sentiment analysis, and more.
GenAI = Next Generation NLP (and more)
ChatGPT, what is Generative AI?
Generative AI is a branch of artificial intelligence focused on creating models and systems capable of generating new content, such as images, text, music, or even entire virtual worlds. These models are trained on large datasets and learn patterns and structures to generate new outputs similar to the training data. That’s why the widespread buzzword is Large Language Model (LLM).
Generative AI is used for next-generation NLP and uses techniques such as generative adversarial networks (GANs), variational autoencoders (VAEs), and recurrent neural networks (RNNs). Generative AI has applications in various fields and industries, including art, design, entertainment, and scientific research.
Apache Kafka for Data Streaming
ChatGPT, what is Apache Kafka?
Apache Kafka is an open-source distributed streaming platform and became the de facto standard for event streaming. It was developed by the Apache Software Foundation and is widely used for building real-time data streaming applications and event-driven architectures. Kafka provides a scalable and fault-tolerant system for handling high volumes of streaming data.
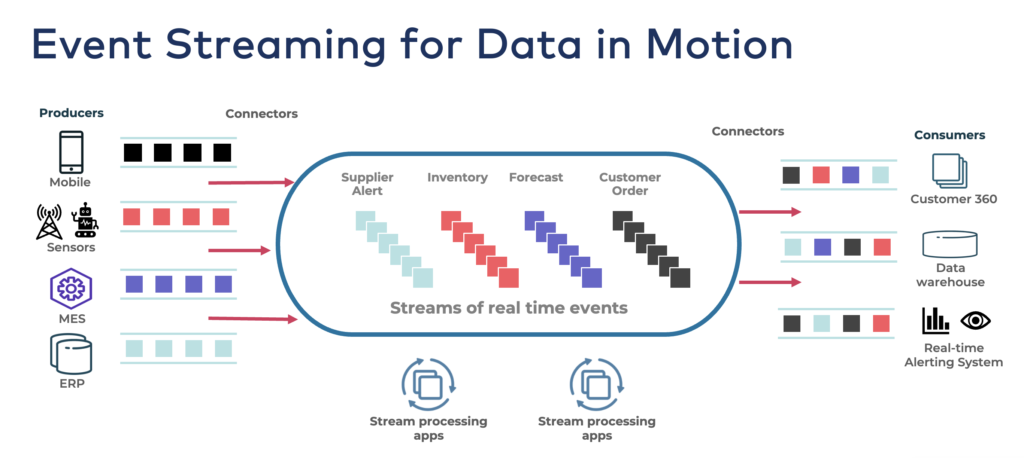
Kafka has a thriving ecosystem with various tools and frameworks that integrate with it, such as Apache Spark, Apache Flink, and others.
Apache Kafka is widely adopted in use cases that require real-time data streaming, such as data pipelines, event sourcing, log aggregation, messaging systems, and more.
Why Apache Kafka and GenAI?
Generative AI (GenAI) is the next-generation NLP engine that helps many projects in the real world for service desk automation, customer conversation with a chatbot, content moderation in social networks, and many other use cases.
Apache Kafka became the predominant orchestration layer in these machine learning platforms for integrating various data sources, processing at scale, and real-time model inference.
Data streaming with Kafka already powers many GenAI infrastructures and software products. Very different scenarios are possible:
- Data streaming as data fabric for the entire machine learning infrastructure
- Model scoring with stream processing for real-time productions
- Generation of streaming data pipelines with input text or speech
- Real-time online training of large language models
Let’s explore these opportunities for data streaming with Kafka and GenAI in more detail.
Real-time Kafka Data Hub for GenAI and other Microservices in the Enterprise Architecture
I already explored in 2017 (!) how “How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka“. At that time, real-world examples came from tech giants like Uber, Netflix, and Paypal.
Today, Apache Kafka is the de facto standard for building scalable and reliable machine learning infrastructures across any enterprise and industry, including:
- Data integration from various sources (sensors, logs, databases, message brokers, APIs, etc.) using Kafka Connect connectors, fully-managed SaaS integrations, or any kind of HTTP REST API or programming language.
- Data processing leveraging stream processing for cost-efficient streaming ETL such as filtering, aggregations, and more advanced calculations while the data is in motion (so that any downstream application gets accurate information)
- Data ingestion for near real-time data sharing with various data warehouses and data lakes so that each analytics platform can use its product and tools.
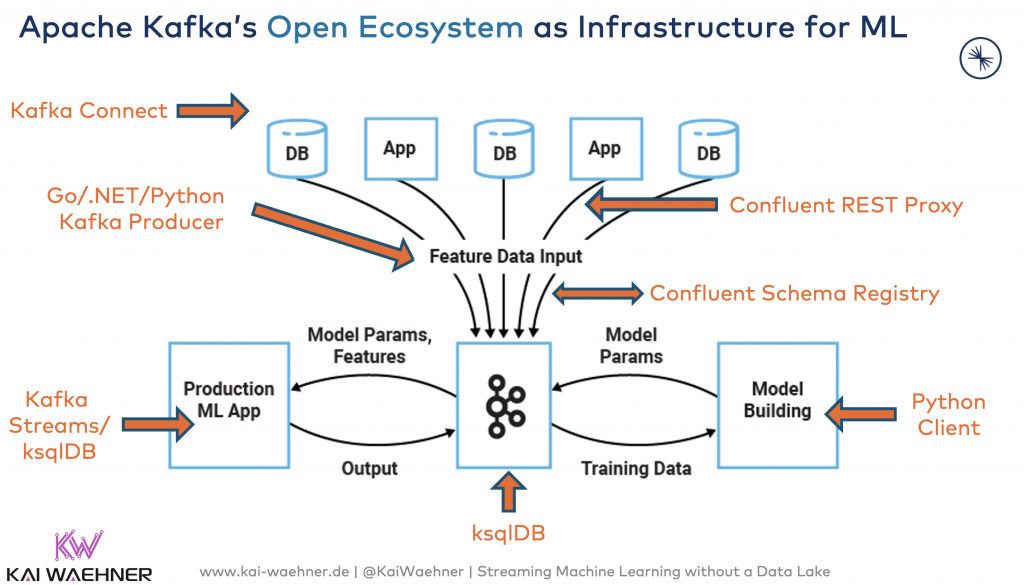
Building scalable and reliable end-to-end pipelines is today’s sweet spot of data streaming with Apache Kafka in the AI and Machine Learning space.
Model Scoring with Stream Processing for Real-Time Predictions at any Scale
Deploying an analytic model in a Kafka application is the solution to provide real-time predictions at any scale with low latency. This is one of the biggest problems in the AI space, as data scientists primarily focus on historical data and batch model training in data lakes.
However, the model scoring for predictions needs to provide much better SLAs regarding scalability, reliability, and latency. Hence, more and more companies separate model training from model scoring and deploy the analytic model within a stream processor such as Kafka Streams, KSQL, or Apache Flink:
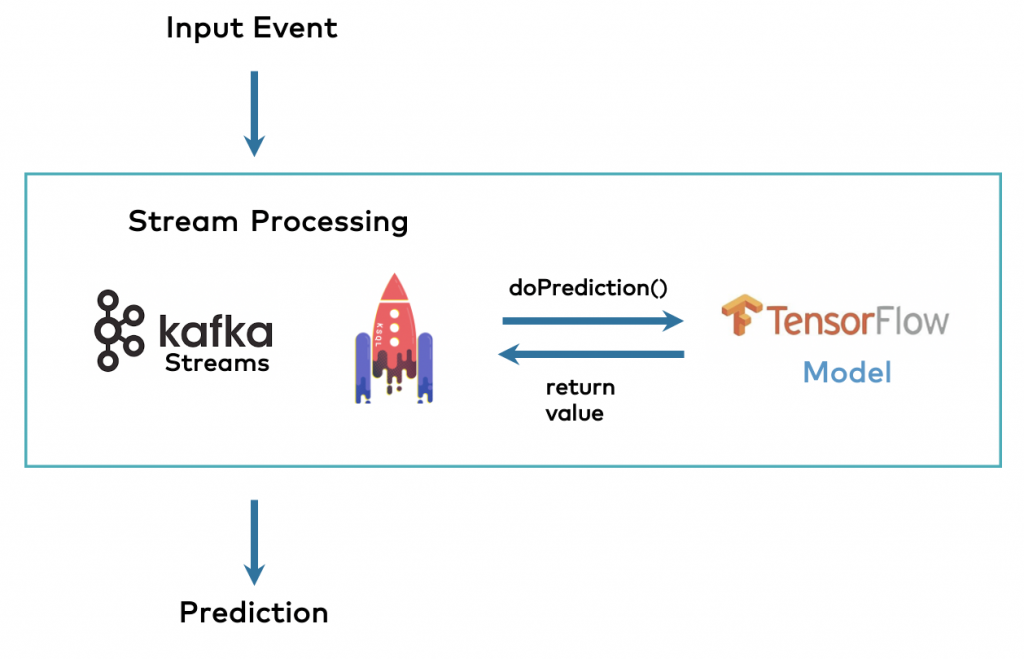
Check out my article “Machine Learning and Real-Time Analytics in Apache Kafka Applications” for more details.
Dedicated model servers usually only support batch and request-response (e.g., via HTTP or gRPC). Fortunately, many solutions now also provide native integration with the Kafka protocol.
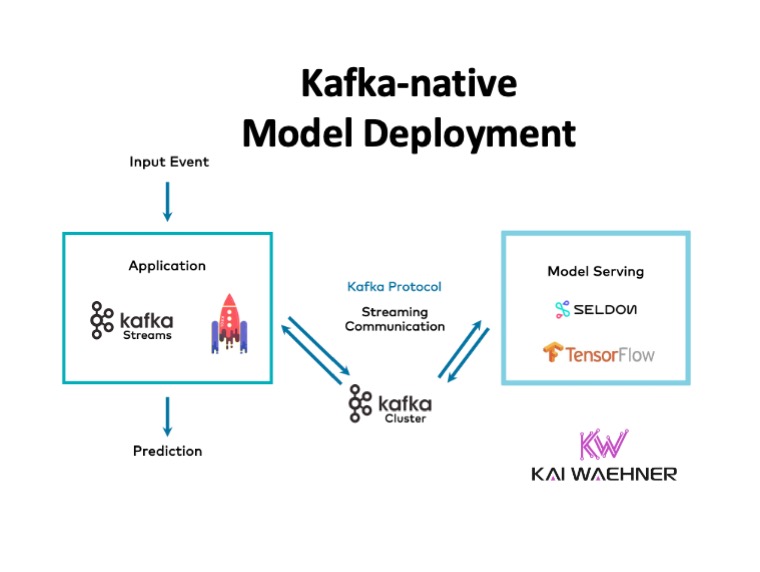
I explored this innovation in my blog post “Streaming Machine Learning with Kafka-native Model Deployment“.
Development Tools for Generating Kafka-native Data Pipelines from Input Text or Speech
Almost every software vendor discusses GenAI to enhance its development environments and user interfaces.
For instance, GitHub is a platform and cloud-based service for software development and version control using Git. But their latest innovation is “the AI-Powered Developer Platform to Build, Scale, and Deliver Secure Software”: Github CoPilot X. Cloud providers like AWS provide similar tools.
Similarly, look at any data infrastructure vendor like Databricks or Snowflake. The latest conferences and announcements focus on embedded capabilities around large language models and GenAI in their solutions.
The same will be true for many data streaming platforms and cloud services. Low-code/no-code tools will add capabilities to generate data pipelines from input text. One of the most straightforward applications that I see coming is generating SQL code out of user text.
For instance, “Consume data from Oracle table customer, aggregate the payments by customer, and ingest it into Snowflake”. This could create SQL code for stream processing technologies like KSQL or FlinkSQL.
Developer experience, faster time-to-market, and support less technical personas are enormous advantages for embedding GenAI into Kafka development environments.
Real-time Training of Large Language Models (LLM)
AI and Machine Learning are still batch-based systems almost all of the time. Model training takes at least hours. This is not ideal, as many GenAI use cases require accurate and updated information. Imagine googling for information today, and you could not find data from the past week. Impossible to use such a service in many scenarios!
Similarly, if I ask ChatGPT today (July 2023): “What is GenAI?” – I get the following response:
As of my last update in September 2021, there is no specific information on an entity called “GenAi.” It’s possible that something new has emerged since then. Could you provide more context or clarify your question so I can better assist you?
The faster your machine learning infrastructure ingests data into model training, the better. My colleague Michael Drogalis wrote an excellent deep-technical blog post: “GPT-4 + Streaming Data = Real-Time Generative AI” to explore this topic more thoroughly.
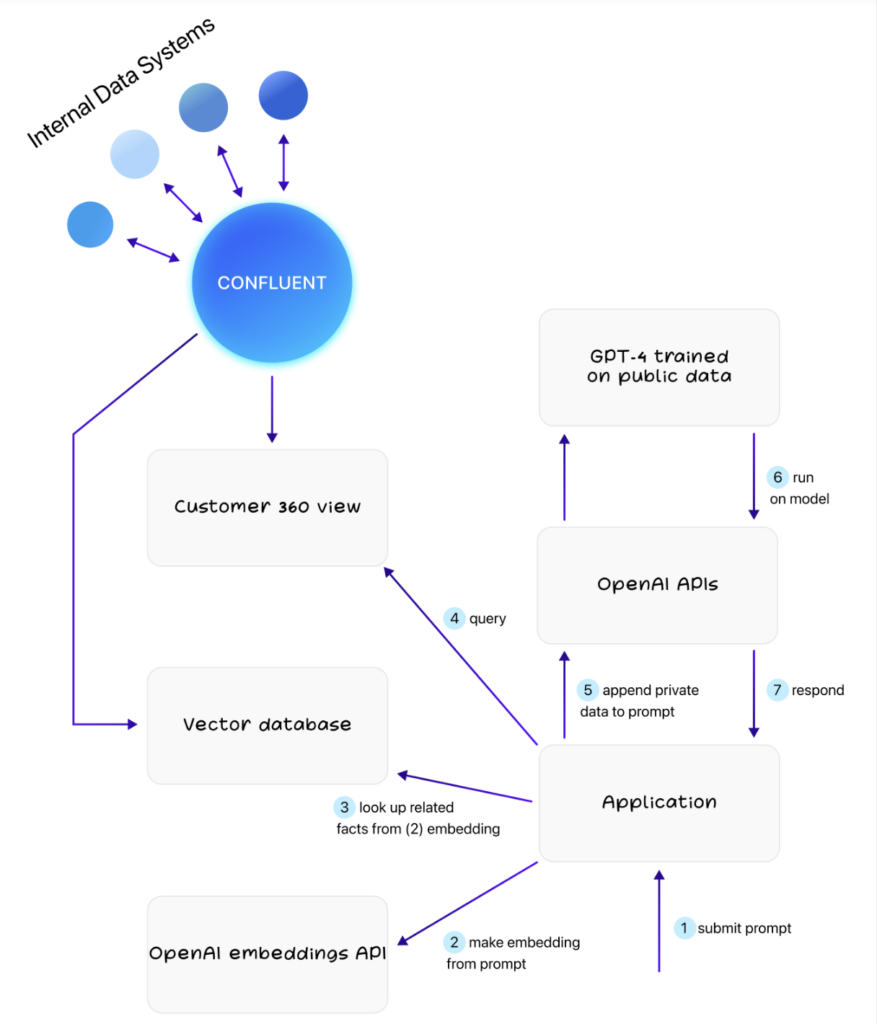
This architecture is compelling because the chatbot will always have your latest information whenever you prompt it. For instance, if your flight gets delayed or your terminal changes, the chatbot will know about it during your chat session. This is entirely distinct from current approaches where the chat session must be reloaded or wait a few hours/days for new data to arrive.
LLM + Vector Database + Kafka = Real-Time GenAI
Real-time model training is still a novel approach. Many machine learning algorithms are not ready for continuous online model training today. But combining Kafka with a vector database enables using a batch-trained LLM together with real-time updates feeding up-to-date information into the LLM.
Nobody will accept an LLM like ChatGPT in a few years, giving you answers like “I don’t have this information; my model was trained a week ago”. It does not matter if you choose a brand new vector database like Pinecone or leverage new vector capabilities of your installed Oracle or MongoDB storage.
Feed data into the vector database in real-time with Kafka Connect and combine with with a mature LLM to enable real-time GenAI with context-specific recommendations.
Real-World Case Studies for Kafka and GenAI
This section explores how companies across different industries, such as the carmaker BMW, the online travel and booking Expedia, and the dating app Tinder leverage the combination of data streaming with GenAI for reliable real-time conversational AI, NLP and chatbots leveraging Kafka.
Two years ago, I wrote about this topic: “Apache Kafka for Conversational AI, NLP and Chatbot“. But technologies like ChatGPT make it much easier to adopt GenAI in real-world projects with much faster time-to-market and less cost and risk. Let’s explore a few of these success stories for embedding NLP and GenAI into data streaming enterprise architectures.
Disclaimer: As I want to show real-world case studies instead of visionary outlooks, I show several examples deployed in production in the last few years. Hence, the analytic models do not use GenAI, LLM, or ChatGPT as we know it from the press today. But the principles are precisely the same. The only difference is that you could use a cutting-edge model like ChatGPT with much improved and context-specific responses today.
Expedia – Conversations Platform for Better Customer Experience
Expedia is a leading online travel and booking. They have many use cases for machine learning. One of my favorite examples is their Conversations Platform built on Kafka and Confluent Cloud to provide an elastic cloud-native application.
The goal of Expedia’s Conversations Platform was simple: Enable millions of travelers to have natural language conversations with an automated agent via text, Facebook, or their channel of choice. Let them book trips, make changes or cancellations, and ask questions:
- “How long is my layover?”
- “Does my hotel have a pool?”
- “How much will I get charged to bring my golf clubs?”
Then take all that is known about that customer across all of Expedia’s brands and apply machine learning models to immediately give customers what they are looking for in real-time and automatically, whether a straightforward answer or a complex new itinerary.
Real-time Orchestration realized in four Months
Such a platform is no place for batch jobs, back-end processing, or offline APIs. To quickly make decisions that incorporate contextual information, the platform needs data in near real-time, and it needs it from a wide range of services and systems. Meeting these needs meant architecting the Conversations Platform around a central nervous system based on Confluent Cloud and Apache Kafka. Kafka made it possible to orchestrate data from loosely coupled systems, enrich data as it flows between them so that by the time it reaches its destination, it is ready to be acted upon, and surface aggregated data for analytics and reporting.
Expedia built this platform from zero to production in four months. That’s the tremendous advantage of using a fully managed serverless event streaming platform as the foundation. The project team can focus on the business logic.
The Covid pandemic proved the idea of an elastic platform: Companies were hit with a tidal wave of customer questions, cancellations, and re-bookings. Throughout this once-in-a-lifetime event, the Conversations Platform proved up to the challenge, auto-scaling as necessary and taking off much of the load of live agents.
Expedia’s Migration from MQ to Kafka as Foundation for Real-time Machine Learning and Chatbots
I explored several times that event streaming is more than just a (scalable) message queue. Check out my old (but still accurate and relevant) Comparison between MQ and Kafka, or the newer comparison between cloud-native iPaaS and Kafka.
BMW – GenAI for Contract Intelligence, Workplace Assistance and Machine Translation
- Service desk automation
- Speech analysis of customer interaction center (CIC) calls to improve the quality
- Self-service using smart knowledge bases
- Agent support
- Chatbots
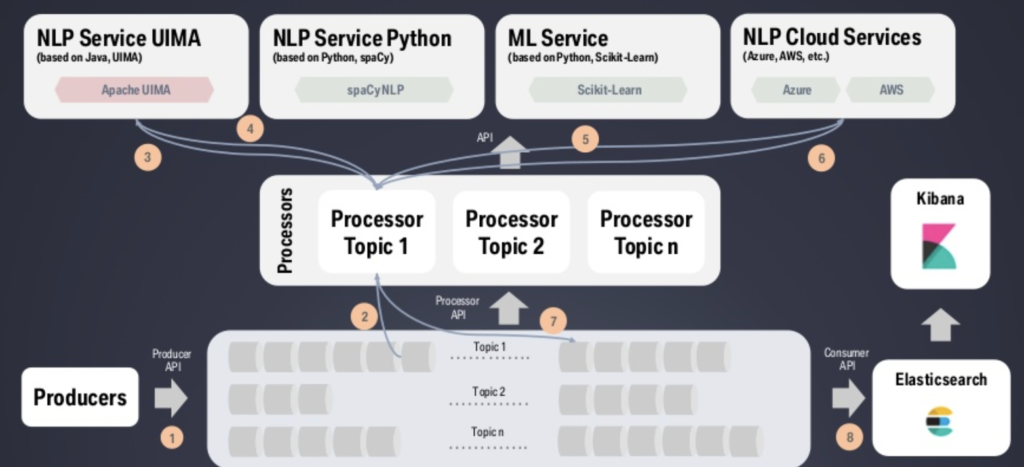
- Flexible integration: Multiple supported interfaces for different deployment scenarios, including various machine learning technologies, programming languages, and cloud providers
- Modular end-to-end pipelines: Services can be connected to provide full-fledged NLP applications.
- Configurability: High agility for each deployment scenario
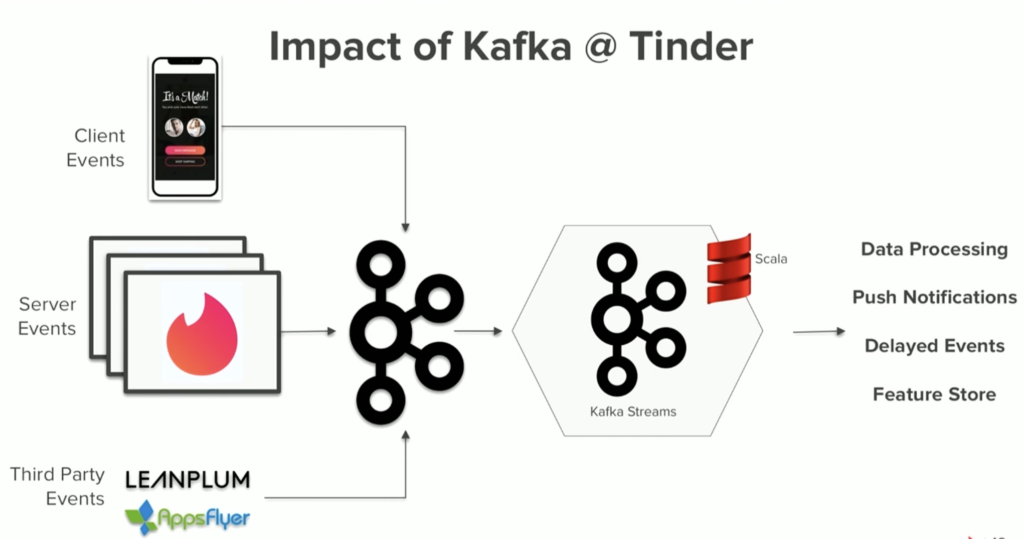
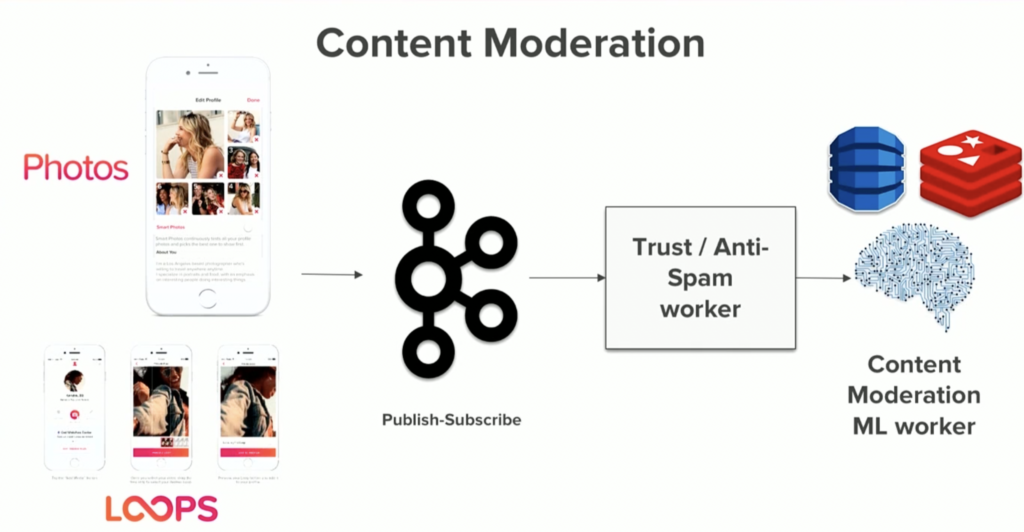
Tinder – Intelligent Content Moderation, Matching and Recommendations with Kafka and GenAI
The dating app Tinder is a great example where I can think of tens of use cases for NLP. Tinder talked at a past Kafka Summit about their Kafka-powered machine learning platform.
Tinder is a massive user of Kafka and its ecosystem for various use cases, including content moderation, matching, recommendations, reminders, and user reactivation. They used Kafka Streams as a Kafka-native stream processing engine for metadata processing and correlation in real-time at scale:
Kafka as Real-Time Data Fabric for Future GenAI Initiatives
Real-time data beats slow data. Generative AI only adds value if it provides accurate and up-to-date information. Data streaming technologies such as Apache Kafka and Apache Flink enable building a reliable, scalable real-time infrastructure for GenAI. Additionally, the event-based heart of the enterprise architecture guarantees data consistency between real-time and non-real-time systems (near real-time, batch, request-response).
The early adopters like BWM, Expedia, and Tinder proved that Generative AI integrated into a Kafka architecture adds enormous business value. The evolution of AI models with ChatGPT et al. makes the use case even more compelling across every industry.
How do you build conversational AI, chatbots, and other GenAI applications leveraging Apache Kafka? What technologies and architectures do you use? Are data streaming and Kafka part of the architecture? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
