
Generative AI (GenAI) enables automation and innovation across industries. This blog post explores a simple but powerful architecture and demo for the combination of Python, and LangChain with OpenAI LLM, Apache Kafka for event streaming and data integration, and Apache Flink for stream processing. The use case shows how data streaming and GenAI help to correlate data from Salesforce CRM, searching for lead information in public datasets like Google and LinkedIn, and recommending ice-breaker conversations for sales reps.

The Emergence of Generative AI
Generative AI (GenAI) refers to a class of artificial intelligence (AI) systems and models that generate new content, often as images, text, audio, or other types of data. These models can understand and learn the underlying patterns, styles, and structures present in the training data and then generate new, similar content on their own.
Generative AI has applications in various domains, including:
- Image Generation: Generating realistic images, art, or graphics.
- Text Generation: Creating human-like text, including natural language generation.
- Music Composition: Generating new musical compositions or styles.
- Video Synthesis: Creating realistic video content.
- Data Augmentation: Generating additional training data for machine learning models.
- Drug Discovery: Generating molecular structures for new drugs.
A key challenge of Generative AI is the deployment in production infrastructure with context, scalability, and data privacy in mind. Let’s explore an example of using CRM and customer data to integrate GenAI into an enterprise architecture to support sales and marketing.
Demo: LangChain + Kafka + Flink = Automated Cold Calls of Sales Leads with Salesforce CRM and LinkedIn Data
This article shows a demo that combines real-time data streaming powered by Apache Kafka and Flink with a large language model from OpenAI within LangChain. If you want to learn more about data streaming with Kafka and Flink in conjunction with Generative AI, check out these two articles:
- Use Cases for Apache Kafka as Mission Critical Data Fabric for GenAI
- Apache Kafka + RAG with Vector Database + LLM = Real-Time GenAI
- The Salesforce CRM creates new leads through other interfaces or by the human manually.
- The sales rep / SDR receives lead information in real time to call the prospect.
- A special GenAI service leverages the lead information (name and company) to search the web (mainly LinkedIn) to generate helpful content for the cold call of the lead, including: Summary, two interesting facts, topic of interest, and two creative ice-breaker for initiating a conversation.
Kudos to my colleague Carsten Muetzlitz who built the demo. The code is available on Github. Here is the architecture of the demo:
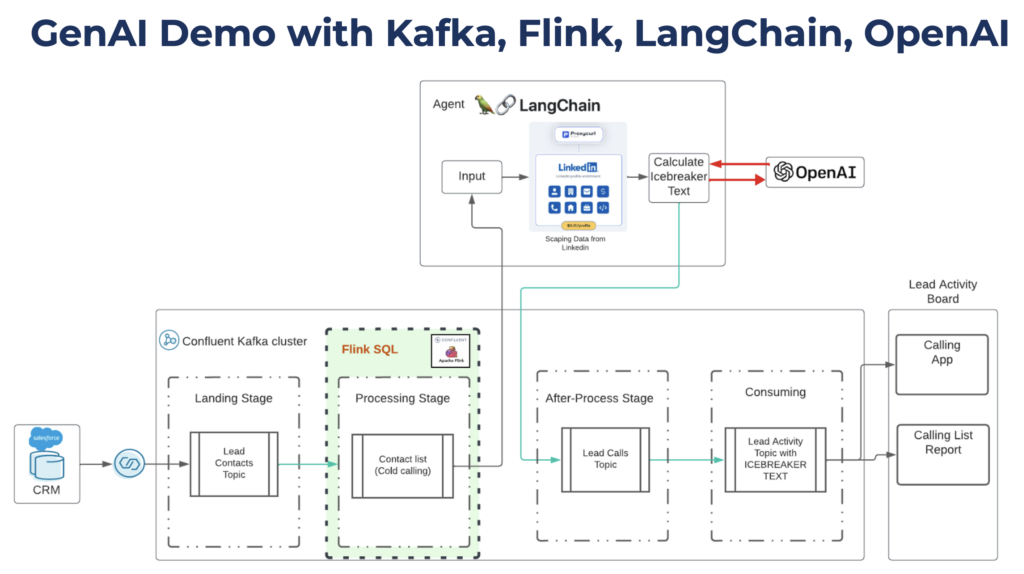
Technologies and Infrastructure in the Demo
The following technologies and infrastructure are used to implement and deploy the GenAI demo.
- Python: The programming language almost every data engineer and data scientist uses.
- LangChain: The Python framework implements the application to support sales conversations.
- OpenAI: The language model and API help to build simple but powerful GenAI applications.
- Salesforce: The cloud CRM tool stores the lead information and other sales and marketing data.
- Apache Kafka: Scalable real-time data hub decoupling the data sources (CRM) and data sinks (GenAI application and other services).
- Kafka Connect: Data integration via Change Data Capture (CDC) from Salesforce CRM.
- Apache Flink: Stream processing for enrichment and data quality improvements of the CRM data.
- Confluent Cloud: Fully managed Kafka (stream and store), Flink (process), and Salesforce connector (integrate).
- SerpAPI: Scrape Google and other search engines with the lead information.
- proxyCurl: Pull rich data about the lead from LinkedIn without worrying about scaling a web scraping and data-science team.
Live Demo of Python + LangChain + OpenAI + Kafka + Flink
Here is a 15 minute video walking you through the demo:
- Use case
- Technical architecture
- GitHub project with Python code using Kafka and LangChain
- Fully managed Kafka and Flink in the Confluent Cloud UI
- Push new leads in real-time from Salesforce CRM via CDC using Kafka Connect
- Streaming ETL with Apache Flink
- Generative AI with Python, LangChain and OpenAI
You are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
Missing: No Vector DB and RAG with Model Embeddings in the LangChain Demo
This demo does NOT use advanced GenAI technologies for RAG (retrieval augmented generation), model embeddings, or vector search via a Vector database (Vector DB) like Pinecone, Weaviate, MongoDB or Oracle.
The principle of the demo is KISS (“keep it as simple as possible”). These technologies can and will be integrated into many real-world architectures.
The demo has limitations regarding latency and scale. Kafka and Flink run as fully managed and elastic SaaS. But the AI/ML part around LangChain could have improved latency, using a SaaS for hosting, and integration with other dedicated AI platforms. Especially data-intensive applications will need a vector database and advanced retrieval and semantic search technologies like RAG.
Fun fact: The demo breaks when I search for my name instead of Carsten’s. Because the web scraper finds too much content in the web about me and as a result the LangChain app crashes… This is a compelling event for complementary technologies like Pinecone or MongoDB that can do indexing, RAG and semantic search at scale. These technologies provide fully managed integration with Confluent Cloud so the demo could easily be extended.
The Role of LangChain in GenAI
LangChain is an open-source framework for developing applications powered by language models. LangChain is also the name of the commercial vendor behind the framework. The tool provides the needed “glue code” for data engineers to build GenAI applications with intuitive APIs for chaining together large language models (LLM), prompts with context, agents that drive decision making with stateful conversations, and tools that integrate with external interfaces.
LangChain supports:
- Context-awareness: connect a language model to sources of context (prompt instructions, few shot examples, content to ground its response in, etc.)
- Reason: rely on a language model to reason (about how to answer based on provided context, what actions to take, etc.)
The main value props of the LangChain packages are:
- Components: composable tools and integrations for working with language models. Components are modular and easy-to-use, whether you are using the rest of the LangChain framework or not.
- Off-the-shelf chains: built-in assemblages of components for accomplishing higher-level tasks.
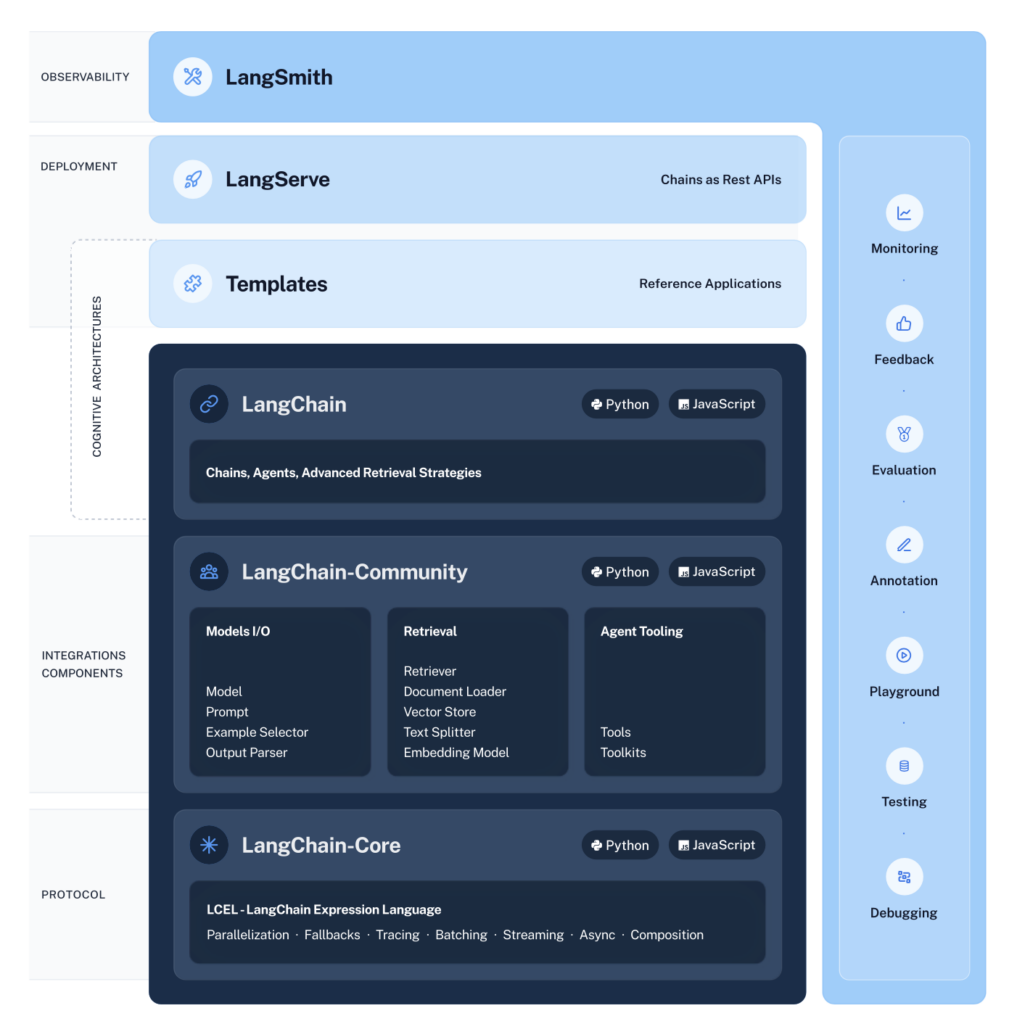
Together, these products simplify the entire application lifecycle:
- Develop: Write your applications in LangChain/LangChain.js. Hit the ground running using Templates for reference.
- Productionize: Use LangSmith to inspect, test and monitor your chains, so that you can constantly improve and deploy with confidence.
- Deploy: Turn any chain into an API with LangServe.
LangChain in the Demo
The demo uses several LangChain concepts such as Prompts, Chat Models, Chains using the LangChain Expression Language (LCEL), Agents using a language model to choose a sequence of actions to take
Here is the logical flow of the LangChain business process:
- Get new leads: Collect full name and company of the lead from Salesforce CRM in real-time from a Kafka Topic.
- Find LinkedIn profile: Use the Google Search API “SerpAPI” to search for the URL of the lead’s LinkedIn profile.
- Collect information about the lead: Use Proxycurl to collect the required information about the lead from LinkedIn.
- Create cold call recommendations for the sales rep or automated script: Ingest all information into the ChatGPT LLM via OpenAI API and send the generated text to a Kafka Topic.
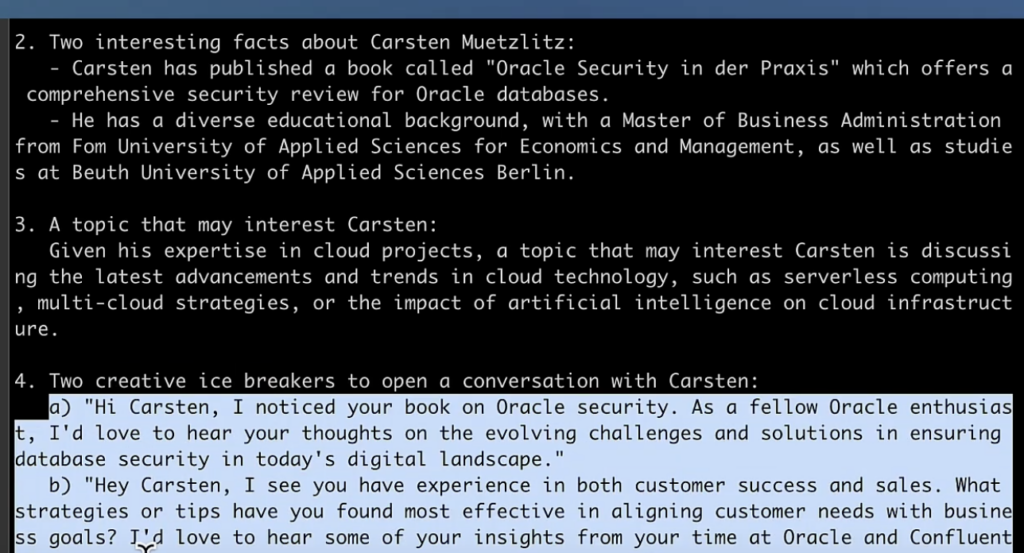
The following screenshot shows a snippet of the generated content. It includes context-specific icebreaker conversations based on the LinkedIn profile. For the context, Carsten worked at Oracle for 24 years before joining Confluent. The LLM uses this context of the LangChain prompt to generate related content:
The Role of Apache Kafka in GenAI
Apache Kafka is a distributed streaming platform used for building real-time data pipelines and streaming applications. It plays a crucial role in handling and managing large volumes of data streams efficiently and reliably.
Generative AI typically involves models and algorithms for creating new data, such as images, text, or other types of content. Apache Kafka supports Generative AI by providing a scalable and resilient infrastructure for managing data streams. In a Generative AI context, Kafka can be used for:
- Data Ingestion: Kafka can handle the ingestion of large datasets, including the diverse and potentially high-volume data needed to train Generative AI models.
- Real-time Data Processing: Kafka’s real-time data processing capabilities help in scenarios where data is constantly changing, allowing for the rapid updating and training of Generative AI models.
- Event Sourcing: Event sourcing with Kafka captures and stores events that occur over time, providing a historical record of data changes. This historical data is valuable for training and improving Generative AI models.
- Integration with other Tools: Kafka can be integrated into larger data processing and machine learning pipelines, facilitating the flow of data between different components and tools involved in Generative AI workflows.
While Apache Kafka itself is a tool specifically designed for Generative AI, its features and capabilities contribute to the overall efficiency and scalability of the data infrastructure. Kafka’s capabilities are crucial when working with large datasets and complex machine learning models, including those used in Generative AI applications.
Apache Kafka in the Demo
Kafka is the data fabric connecting all the different applications. Ensuring data consistency is a sweet spot of Kafka. No matter if a data source or sink is real time, batch or a request-response API.
In this demo, Kafka consumes events from Salesforce CRM as the main data source of customer data. Different applications (Flink, LangChain, Salesforce) consume the data in different steps of the business process. Kafka Connect provides the capability for data integration with no need for another ETL, ESB or iPaaS tool. This demo uses Confluent’s Change Data Capture (CDC) connector to consume changes from the Salesforce database in real-time for further processing.
Fully managed Confluent Cloud is the infrastructure for the entire Kafka and Flink ecosystem in this demo. The focus of the developer should always build business logic, not worrying about operating infrastructure.
While the heart of Kafka is event-based, real-time and scalable, it also enables domain-driven design and data mesh enterprise architectures out-of-the-box.
The Role of Apache Flink in GenAI
Apache Flink is an open-source distributed stream processing framework for real-time analytics and event-driven applications. Its primary focus is on processing continuous streams of data efficiently and at scale. While Apache Flink itself is not a specific tool for Generative AI, it plays a role in supporting certain aspects of Generative AI workflows. Here are a few ways in which Apache Flink is relevant:
- Real-time Data Processing: Apache Flink can process and analyze data in real-time, which can be useful for scenarios where Generative AI models need to operate on streaming data, adapting to changes and generating responses in real-time.
- Event Time Processing: Flink has built-in support for event time processing, allowing for the handling of events in the order they occurred, even if they arrive out of order. This can be beneficial in scenarios where temporal order is crucial, such as in sequences of data used for training or applying Generative AI models.
- Stateful Processing: Flink supports stateful processing, enabling the maintenance of state across events. This can be useful in scenarios where the Generative AI business process needs to maintain context or memory of past events to generate coherent and context-aware outputs.
- Integration with Machine Learning Libraries: While Flink itself is not a machine learning framework, it can be integrated with other tools and libraries that are used in machine learning, including those relevant to Generative AI. This integration can facilitate the deployment and execution of machine learning models within Flink-based streaming applications.
The specific role of Apache Flink in Generative AI depends on the particular use case and the architecture of the overall system.
Apache Flink in the Demo
This demo leverages Apache Flink for streaming ETL (enrichment, data quality improvements) of the incoming Salesforce CRM events.
FlinkSQL provides a simple and intuitive way to implement ETL with any Java or Python code. Fully managed Confluent Cloud is the infrastructure for Kafka and Flink in this demo. Serverless FlinkSQL allows you to scale up as much as needed, but also scale down to zero if no events are consumed and processed.
The demo is just the starting point. Many powerful applications can be built with Apache Flink. This includes streaming ETL, but also business applications like you find them at Netflix, Uber and many other tech giants.
LangChain + Fully-Managed Kafka and Flink = Simple, Powerful Real-Time GenAI
LangChain is an easy-to-use AI/ML framework to connect large language models to other data sources and create valuable applications. The flexibility and open approach enables developers and data engineers to build all sorts of applications, from chatbots to smart systems that answer your questions.
Data streaming with Apache Kafka and Flink provide a reliable and scalable data fabric for data pipelines and stream processing. The event store of Kafka ensures data consistency across real-time, batch, and request-response APIs. Domain-driven design, microservice architectures and data products build in a data mesh more and more leverage on Kafka for these reasons.
The combination of LangChain, GenAI technologies like OpenAI and data streaming with Kafka and Flink make a powerful combination for context-specific decision in real-time powered by AI.
Most enterprises have a cloud-first strategy for AI use cases. Data streaming infrastructure is available in SaaS like Confluent Cloud so that the developers can focus on business logic with much faster time-to-market. Plenty of alternatives exist for building AI applications with Python (the de facto standard for AI). For instance, you could build a user-defined function (UDF) in a FlinkSQL application executing the Python code and consuming from Kafka. Or use a separate application development framework and cloud platform like Quix Streams or Bytewax for Python apps instead of a framework like LangChain.
How do you combine Python, LangChain and LLMs with data streaming technologies like Kafka and Flink? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
