Apache Kafka in the Public Sector – Part 2: Smart City
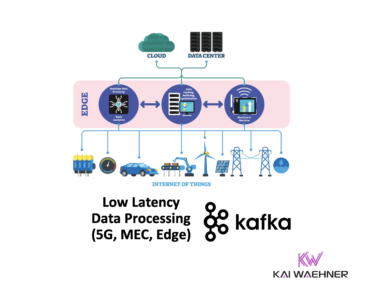
The public sector includes many different areas. Some groups leverage cutting-edge technology, like military leverage. Others like the public administration are years or even decades behind. This blog series explores both edges to show how data in motion powered by Apache Kafka adds value for innovative new applications and modernizing legacy IT infrastructures. This is part 2: Use cases and architectures for a Smart City.