Many mission-critical use cases require low latency data processing. Running these workloads close to the edge is mandatory if the applications cannot run in the cloud. This blog post explores architectures for low latency deployments leveraging a combination of cloud-native infrastructure at the edge, such as AWS Wavelength, 5G networks from Telco providers, and event streaming with Apache Kafka to integrate and process data in motion.
The blog post is structured as follows:
- Definition of “low latency data processing” and the relation to Apache Kafka
- Cloud-native infrastructure for low latency computing
- Low latency mission-critical use cases for Apache Kafka and its relation to analytical workloads
- Example for a hybrid architecture with AWS Wavelength, Verizon 5G, and Confluent
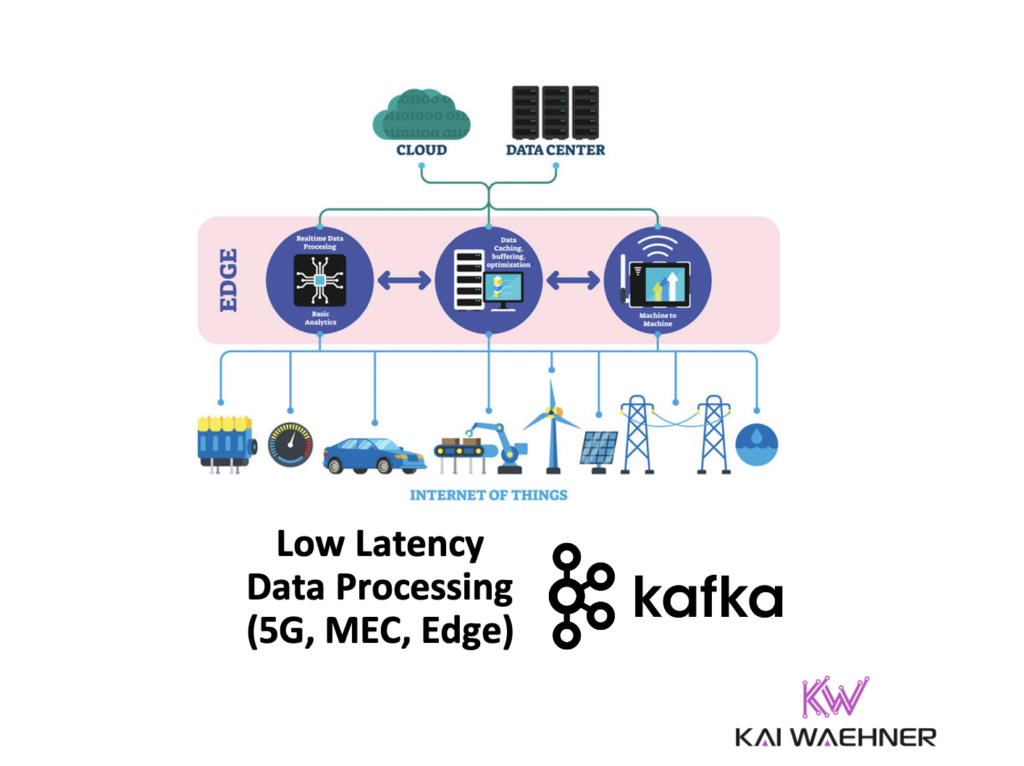
Low Latency Data Processing
Let’s begin with a definition. “Real-time” and “low latency” are terms that different industries, vendors, and consultants use very differently.
What is real-time and low latency data processing?
For the context of this blog, real-time data processing with low latency means processing low or high volumes of data in ~5 to 50 milliseconds end-to-end. On a high level, this includes three parts:
- Consume events from one or more data sources, either directly from a Kafka client or indirectly via a gateway or proxy.
- Process and correlate events from one or more data sources, either stateless or stateful, with the internal state in the application and stream processing features like sliding windows.
- Produce events to one or more data sinks, either directly from a Kafka client or indirectly via a gateway or proxy. The data sinks can include the data sources and/or other applications.
These parts are the same as for “traditional event streaming use cases”. However, for low latency use cases with zero downtime and data loss, the architecture often looks different to reach the defined goals and SLAs. A single infrastructure is usually the better choice than using a best-of-breed approach with many different frameworks or products. That’s where the Kafka ecosystem shines! The Kafka vs. MQ/ETL/ESB/API blog explores this discussion in more detail.
Low latency = soft real-time; NOT hard real-time
Make sure to understand that real-time in the IT world (that includes Kafka) is not hard real-time. Latency spikes and non-deterministic network behavior exist. The chosen software or framework does not matter. Hence, in the IT world, real-time means soft real-time. Contrarily, in the OT world and Industrial IoT, real-time means zero latency and deterministic networks. This is embedded software for sensors, robots, or cars.
For more details, read the blog post “Kafka is NOT hard-real-time“.
Kafka support for low latency processing
Apache Kafka provides very low end-to-end latency for large volumes of data. This means the amount of time it takes for a record that is produced to Kafka to be fetched by the consumer is short.
For example, detecting fraud for online banking transactions has to happen in real-time to deliver business value without adding more than 50—100 ms of overhead to each transaction to maintain a good customer experience.
Here is the technical architecture for end-to-end latency with Kafka:
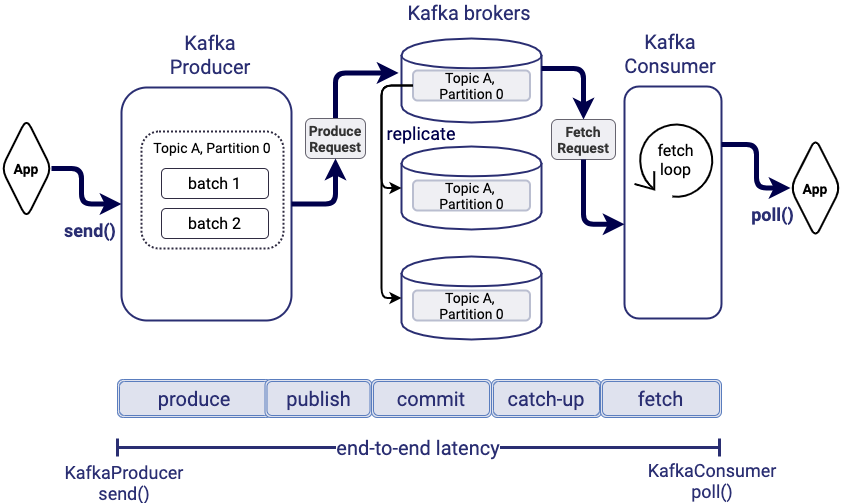
Latency objectives are expressed as both target latency and the importance of meeting this target. For instance, a latency objective says: “I would like to get 99th percentile end-to-end latency of 50 ms from Kafka.” The right Kafka configuration options need to be optimized to achieve this. The blog post “99th Percentile Latency at Scale with Apache Kafka” shares more details.
After exploring what low latency and real-time data processing mean in Kafka’s context, let’s now discuss the infrastructure options.
Infrastructure for Low Latency Data Processing
Low latency always requires a short distance between data sources, data processing platforms, and data sinks due to physics. Latency optimization is relatively straightforward if all your applications run in the same public cloud. Low end-to-end latency gets much more difficult as soon as some software, mobile apps, sensors, machines, etc., run elsewhere. Think about connected cars, mobile apps for mobility services like ride-hailing, location-based services in retail, machines/robots in factories, etc.
The remote data center or remote cloud region cannot provide low latency data processing! The focus of this post is software that has to provide low end-to-end latency outside a central data center or public cloud. This is where edge computing and 5G networks come into play.
Edge infrastructure for low latency data processing
As for real-time and low latency, we need to define the term first, as everyone uses it differently. When I talk about the edge in the context of Kafka, it means:
- Edge is NOT a regular data center or cloud region, but limited compute, storage, network bandwidth.
- Edge can be a regional cloud-native infrastructure enabled for low-latency use cases – often provided by Telco enterprises in conjunction with cloud providers.
- Kafka clients AND the Kafka broker(s) deployed here, not just the client applications.
- Often 100+ locations, like restaurants, coffee shops, or retail stores, or even embedded into 1000s of devices or machines.
- Offline business continuity, i.e., the workloads continue to work even if there is no connection to the cloud.
- Low-footprint and low-touch, i.e., Kafka can run as a normal highly available cluster or as a single broker (no cluster, no high availability); often shipped “as a preconfigured box” in OEM hardware (e.g., Hivecell).
- Hybrid integration, i.e., most use cases require uni- or bidirectional communication with a remote Kafka cluster in a data center or the cloud.
Check out my infrastructure checklist for Apache Kafka at the edge and use cases for Kafka at the edge across industries for more details.
Mobile Edge Compute / Multi-access Edge Compute (MEC)
In addition to edge computing, a few industries (especially everyone related to the Telco sector) uses the terms Mobile Edge Compute / Multi-access Edge Compute (MEC) to describe use cases around edge computing, low latency, 5G, and data processing.
MEC is an ETSI-defined network architecture concept that enables cloud computing capabilities and an IT service environment at the edge of the cellular network and, more generally, at the edge of any network. The basic idea behind MEC is that by running applications and performing related processing tasks closer to the cellular customer, network congestion is reduced, and applications perform better.
MEC technology is designed to be implemented at the cellular base stations or other edge nodes. It enables flexible and rapid deployment of new applications and services for customers. Combining elements of information technology and telecommunications networking, MEC also allows cellular operators to open their radio access network (RAN) to authorized third parties, such as application developers and content providers.
5G and cloud-native Infrastructure are a key piece of a MEC infrastructure!
Low-latency data processing outside a cloud region requires a cloud-native infrastructure and 5G networks. Let’s explore this combination in more detail.
5G infrastructure for low latency and high throughput SLAs
On a high level from a use case perspective, it is important to understand that 5G is much more than just higher speed and lower latency:
- Public 5G telco infrastructure: That’s what Verizon, AT&T, T-Mobile, Dish, Vodafone, Telefonica, and all the other telco providers talk about in their TV spots. The end consumer gets higher download speeds and lower latency (at least in theory). This infrastructure integrates vehicles (e.g., cars) and devices (e.g., mobile phones) to the 5G network (V2N).
- Private 5G campus networks: That’s what many enterprises are most interested in. The enterprise can set up private 5G networks with guaranteed quality of service (QoS) using acquired 5G slices from the 5G spectrum. Enterprise work with telco providers, telco hardware vendors, and sometimes also with cloud providers to provide cloud-native infrastructure (e.g., AWS Outposts, Azure Edge Zones, Google Anthos). This infrastructure is used similarly to the public 5G but deployed, e.g., in a factory or hospital. The trade-offs are guaranteed SLAs and increased security vs. higher cost. Lufthansa Technik and Vodafone’s standalone private 5G campus network at the aircraft hangar is a great example for various use cases like maintenance via video streaming and augmented reality.
- Direct connection between devices: That’s for interlinking the communication between two or more vehicles (V2V) or vehicles and infrastructure (V2I) via unicast or multicast. There is no need for a network hop to the cell tower due to using a 5G technique called 5G sidelink communications. This enables new use cases, especially in safety-critical environments (e.g., autonomous driving) where Bluetooth, Wi-Fi, and similar network communications do not work well for different reasons.
Cloud-native infrastructure
Cloud-native infrastructure provides capabilities to build applications in an elastic, scalable, and automated way. Software development concepts like microservices, DevOps, and containers usually play a crucial role here.
A fantastic example is Dish Network in the US. Dish builds a brand new 5G network completely on cloud-native AWS infrastructure with cloud-native 1st and 3rd party software. Thus, even the network providers – where enterprises build their applications – build the underlying infrastructure this way.
Cloud-native infrastructure is required in the public cloud (where it is the norm) and at the edge. Flexibility for agile development and deployment of applications is only possible this way. Hence, technologies such as Kubernetes and on-premise solutions from cloud providers are adopted more and more to achieve this goal.
The combination of 5G and cloud-native infrastructure enables building low latency applications for data processing everywhere.
Software for Low Latency Data Processing
5G and cloud-native infrastructure provide the foundation for building mission-critical low latency applications everywhere. Let’s now talk about the software part and with that about event streaming with Kafka.
Why event streaming with Apache Kafka for low latency?
Apache Kafka provides a complete software stack for real-time data processing, including:
- Messaging (real-time pub/sub)
- Storage (caching, backpressure handling, decoupling)
- Data integration (IoT data, legacy platforms, modern microservices, and databases)
- Stream processing (stateless/stateful correlation of data).
This is super important because simplicity and cost-efficient operations matter much more at the edge than in a public cloud infrastructure where various SaaS services can be glued together.
Hence, Kafka is uniquely positioned to run mission-critical and analytics workloads at the edge on cloud-native infrastructure via 5G networks. Bi-directional replication to “regular” data centers or public clouds for integration with other systems is also possible via the Kafka protocol.
Use Cases for Low Latency Data processing with Apache Kafka
Low latency and real-time data processing are crucial for many use cases across industries. Hence, no surprise that Kafka plays a key role in many architectures – whether the infrastructure runs at the edge or in a close data center or cloud.
Mobile Edge Compute / Multi-access Edge Compute (MEC) use cases for Kafka across industries
Let’s take a look at a few examples:
- Telco: Infrastructure like cloud-native 5G networks, OSS applications, integration with BSS and OTT services require to integrate, orchestrate and correlate huge volumes of data in real-time.
- Manufacturing: Predictive maintenance, quality assurance, real-time locating systems (RTLS), and other shop floor applications are only effective and valuable with stable, continuous data processing.
- Mobility Services: Ride-hailing, car sharing, or parking services can only provide a great customer experience if the events from thousands of regional end-users are processed in real-time.
- Smart City: Cars from various carmakers, infrastructures such as traffic lights, smart buildings, and many other things need to get real-time information from a central data hub to improve safety and new innovative customer experiences.
- Media: Interactive live video streams, real-time interactions, a hyper-personalized experience, augmented reality (AR) and virtual reality (VR) applications for training/maintenance/customer experience, and real-time gaming can only work well with stable, high throughput, and low latency.
- Energy: Utilities, oil rigs, solar parks, and other energy upstream/distribution/downstream infrastructures are supercritical environments and very expensive. Every second counts for safety and efficiency/cost reasons. Optimizations combine data from all machines in a plant to achieve greater efficiency – not just optimizing one unit but for the entire system.
- Retail: Location-based services for better customer experience and cross-/upselling need notifications while customers are looking at a product or in front of the checkout.
- Military: Border control, surveillance, and other location-based applications only work efficiently with low latency.
- Cybersecurity: Continuous monitoring and signal processing for thread detection and practice prevention are fundamental for any security operation center (SOC) and SIEM/SOAR implementation.
For a concrete example, check out my blog “Building a Smart Factory with Apache Kafka and 5G Campus Networks“.
NOT every use case requires low latency or real-time
Real-time data in motion beats data at rest in databases or data lakes in most scenarios. However, not every use case can be or needs to be real-time. Therefore, low latency networks and communication are not required. A few examples:
- Reporting (traditional business intelligence)
- Batch analytics (processing high volumes of data in a bundle, for instance, Hadoop and Spark’s map-reduce, shuffling, and other data processing only make sense in batch mode)
- Model training as part of a machine learning infrastructure (while model scoring and monitoring often require real-time predictions, the model training is batch in almost all currently available ML algorithms).
These use cases can be outsourced to a remote data center or public cloud. Low latency networking in terms of milliseconds does not matter and likely increases the infrastructure cost. For that reason, most architectures are hybrid to separate low latency from analytics workloads.
Let’s now take a concrete example after all the theory in the last sections.
Hybrid Architecture for Critical Low Latency and Analytical Batch Workloads
Many enterprises I talk to don’t have and don’t want to build their own infrastructure at the edge. Cloud providers understand this pain and started rolling out offerings to provide cloud-native infrastructure close to the customer’s sites. AWS Outposts, Azure Edge Zones, Google Anthos exist for this reason. This solves the problem of providing cloud-native infrastructure.
But what about low latency?
AWS is once again the first to build a new product category: AWS Wavelength is a service that enables you to deliver ultra-low latency applications for 5G devices. It is built on top of AWS Outposts. AWS works with Telco providers like Verizon, Vodafone, KDDI, or SK Telecom to build this offering. A win-win-win: Cloud-native + low latency + no need to build own data centers at the edge.
This is the foundation for building low latency applications at the edge for mission-critical workloads, plus bi-directional integration with the regular public cloud region for analytics workloads and integration with other cloud applications.
Let’s see how this looks like in a real example.
Use case: Energy Production and distribution
Energy production and distribution are perfect examples. They require reliability, flexibility, sustainability, efficiency, security, and safety. These are perfect ingredients for a hybrid architecture powered by cloud-native infrastructure, 5G networks, and event streaming.
The energy sector usually separates analytical capabilities (in the data center or cloud) and low-latency computing for mission-critical workloads (at the edge). Kafka became a critical component for various energy use cases.
For more details, check out the blog post “Apache Kafka for Smart Grid, Utilities and Energy Production” which also covers real-world examples from EON, Tesla, and Devon Energy.
Architecture with AWS Wavelength, Verizon 5G, and Confluent
The concrete example uses:
- AWS Public Cloud for analytics workloads
- Confluent Cloud for event streaming in the cloud and integration with 1st party (e.g., AWS S3 and Amazon Redshift) and 3rd party SaaS (e.g., MongoDB Atlas, Snowflake, Salesforce CRM)
- AWS Wavelength with Verizon 5G for low latency workloads
- Confluent Platform with Kafka Connect and ksqlDB for low latency competing in the Wavelength 5G zone
- Confluent Cluster Linking to glue together the Wavelength zone and the public AWS region using the native Kafka protocol for bi-directional replication in real-time
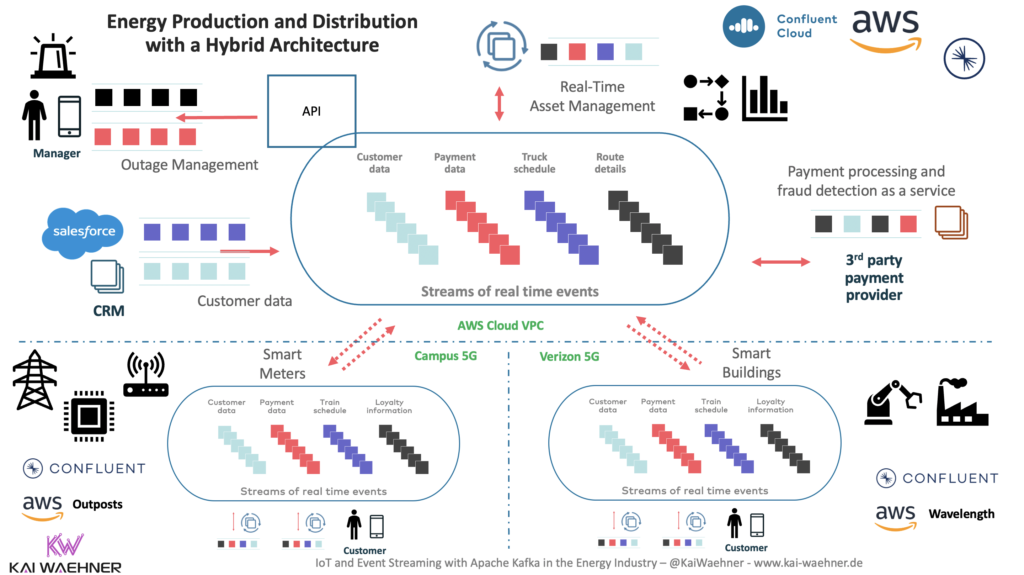
The following diagram shows the same architecture from the perspective of the Wavelength zone where the low latency processing happens:
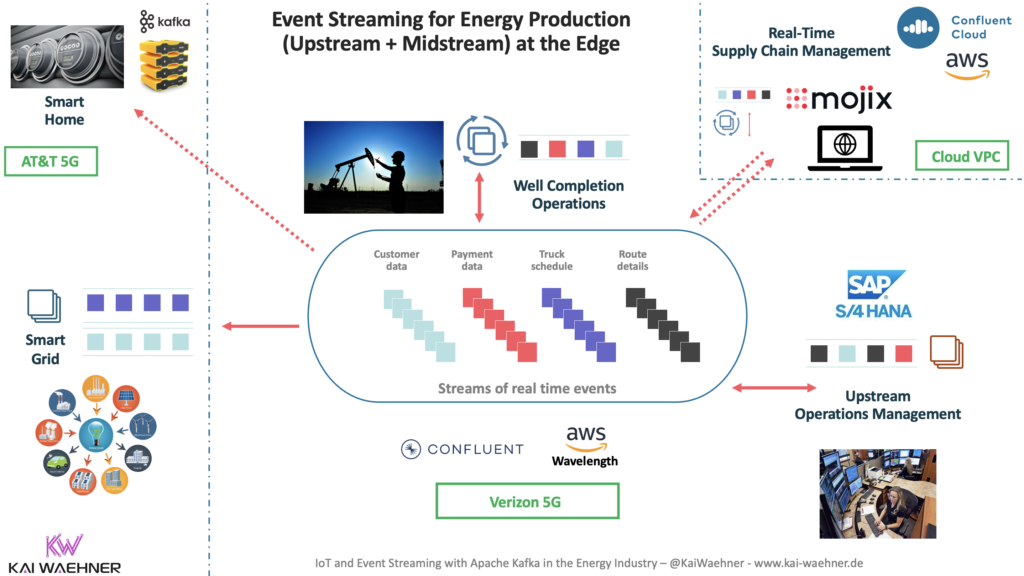
Implementation: Hybrid data processing with Kafka/Confluent, AWS Wavelength, and Verizon 5G
Diagrams are nice. But a real implementation is even better to demonstrate the value of low latency computing close to the edge, plus the integration with the edge devices and public cloud. My colleague Joseph Morais had the lead in implementing a low-latency Kafka scenario with infrastructure provided by AWS and Verizon:
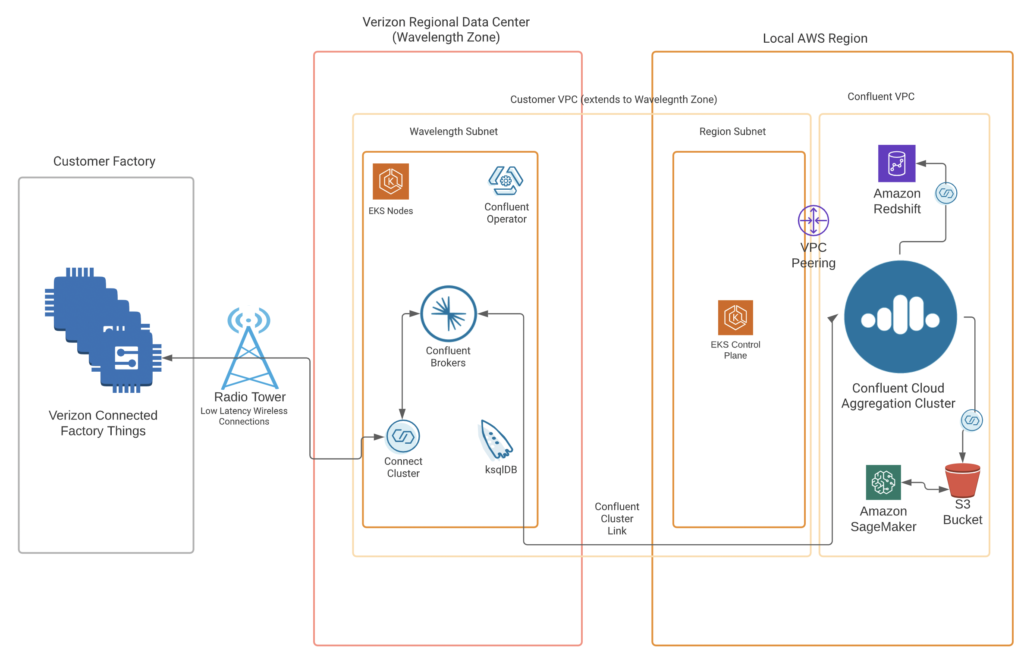
We implemented a use case around real-time analytics with Machine Learning. A single data pipeline collects provides end-to-end integration in real-time across locations. The data comes from edge locations. The low latency processing happens in the AWS Wavelength zone. This includes data integration, preprocessing like filtering/aggregations, and model scoring for anomaly detection.
Cluster Linking (a Kafka-native built-in replication feature) replicates the relevant data to Confluent Cloud in the local AWS region. The cloud is used for batch use cases such as model training with AWS Sagemaker.
This demo demonstrates a realistic hybrid end-to-end scenario to combine mission-critical low latency and analytics batch workloads.
Curious about the relation between Kafka and Machine Learning? I wrote various blogs. One good starter: “Machine Learning and Real-Time Analytics in Apache Kafka Applications“.
Last mile integration: Direct Kafka connection vs gateway / bridge (MQTT / HTTP)?
The last mile integration is an important aspect. How do you integrate “the last mile”? Examples include mobile apps (e.g., ride-hailing), connected vehicles (e.g., predictive maintenance), or machines (e.g., quality assurance for the production line).
This is worth a longer discussion in its own blog post, but let’s do a summary here:
Kafka was not built for bad networks. And Kafka was not built for tens of thousands of connections. Hence, it is pretty straightforward to decide. Option 1 is a direct connection with a Kafka client (using Kafka client APIs for Java, C++, Go, etc.). Option 2 is a scalable gateway or bridge (like MQTT or HTTP Proxy). When to use which one?
- Use a direct connection via a Kafka client API if you have a stable network and only a limited number of connections (usually not higher than 1000 or so).
- Use a gateway or bridge if you have a bad network infrastructure and/or tens of thousands of connections.
The blog series “Use Case and Architectures for Kafka and MQTT” gives you some ideas about use cases that require a bridge or gateway, for instance, connected cars and mobility services. But keep it as simple as possible. If a direct connection works for your use case, why add yet another technology with all its implications regarding complexity and cost?
Low Latency Data Processing Requires the Right Architecture
Low latency data processing is crucial for many use cases across industries. Processing data close to the edge is necessary if the applications cannot run in the cloud. Dedicated cloud-native infrastructure such as AWS Wavelength leverages 5G networks to provide the infrastructure. Event streaming with Apache Kafka provides the capabilities to implement edge computing and the integration with the cloud.
What are your experiences and plans for low latency use cases? What use case and architecture did you implement? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.