Many organizations use both Confluent and Databricks. While these platforms serve different primary goals—real-time data streaming vs. analytical processing—there are areas where they overlap. This blog explores how the Confluent Data Streaming Platform (DSP) and the Databricks Data Intelligence Platform handle data integration and processing. It explains their different roles, where they intersect, and when one might be a better fit than the other.
About the Confluent and Databricks Blog Series
This article is part of a blog series exploring the growing roles of Confluent and Databricks in modern data and AI architectures:
- Blog 1: The Past, Present and Future of Confluent (The Kafka Company) and Databricks (The Spark Company)
- Blog 2 (THIS ARTICLE): Confluent Data Streaming Platform vs. Databricks Data Intelligence Platform for Data Integration and Processing
- Blog 3: Shift-Left Architecture for AI and Data Warehousing with Confluent and Databricks
- Blog 4: Databricks and Confluent in Enterprise Software Environments (with SAP as Example)
- Blog 5: Databricks and Confluent Leading Data and AI Architectures – and How They Compare to Competitors
Learn how these platforms will affect data use in businesses in future articles. Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And download my free book about data streaming use cases, including technical architectures and the relation to analytical platforms like Databricks.
Data Integration and Processing: Shared Space, Different Strengths
Confluent is focused on continuous, event-based data movement and processing. It connects to hundreds of real-time and non-real-time data sources and targets. It enables low-latency stream processing using Apache Kafka and Flink, forming the backbone of an event-driven architecture. Databricks, on the other hand, combines data warehousing, analytics, and machine learning on a unified, scalable architecture.
Confluent: Event-Driven Integration Platform
Confluent is increasingly used as modern operational middleware, replacing traditional message queues (MQ) and enterprise service buses (ESB) in many enterprise architectures.
Thanks to its event-driven foundation, it supports not just real-time event streaming but also integration with request/response APIs and batch-based interfaces. This flexibility allows enterprises to standardize on the Kafka protocol as the data hub—bridging asynchronous event streams, synchronous APIs, and legacy systems. The immutable event store and true decoupling of producers and consumers help maintain data consistency across the entire pipeline, regardless of whether data flows in real-time, in scheduled batches or via API calls.
Databricks: Batch-Driven Analytics and AI Platform
Databricks excels in batch processing and traditional ELT workloads. It is optimized for storing data first and then transforming it within its platform, but it’s not built as a real-time ETL tool for directly connecting to operational systems or handling complex, upstream data mappings.
Databricks enables data transformations at scale, supporting complex joins, aggregations, and data quality checks over large historical datasets. Its Medallion Architecture (Bronze, Silver, Gold layers) provides a structured approach to incrementally refine and enrich raw data for analytics and reporting. The engine is tightly integrated with Delta Lake and Unity Catalog, ensuring governed and high-performance access to curated datasets for data science, BI, and machine learning.
For most use cases, the right choice is simple.
- Confluent is ideal for building real-time pipelines and unifying operational systems.
- Databricks is optimized for batch analytics, warehousing, and AI development.
Together, Confluent and Databricks cover both sides of the modern data architecture—streaming and batch, operational and analytical. And Confluent’s Tableflow and a shift-left architecture enable native integration with earlier data validation, simplified pipelines, and faster access to AI-ready data.
Data Ingestion Capabilities
Databricks recently introduced LakeFlow Connect and acquired Arcion to strengthen its capabilities around Change Data Capture (CDC) and data ingestion into Delta Lake. These are good steps toward improving integration, particularly for analytical use cases.
However, Confluent is the industry leader in operational data integration, serving as modern middleware for connecting mainframes, ERP systems, IoT devices, APIs, and edge environments. Many enterprises have already standardized on Confluent to move and process operational data in real time with high reliability and low latency.
Introducing yet another tool—especially for ETL and ingestion—creates unnecessary complexity. It risks a return to Lambda-style architectures, where separate pipelines must be built and maintained for real-time and batch use cases. This increases engineering overhead, inflates cost, and slows time to market.

In contrast, Confluent supports a Kappa architecture model: a single, unified event-driven data streaming pipeline that powers both operational and analytical workloads. This eliminates duplication, simplifies the data flow, and enables consistent, trusted data delivery from source to sink.

Confluent for Data Ingestion into Databricks
Confluent’s integration capabilities provide:
- 100+ enterprise-grade connectors, including SAP, Salesforce, and mainframe systems
- Native CDC support for Oracle, SQL Server, PostgreSQL, MongoDB, Salesforce, and more
- Flexible integration via Kafka Clients for any relevant programming language, REST/HTTP, MQTT, JDBC, and other APIs
- Support for operational sinks (not just analytics platforms)
- Built-in governance, durability, and replayability
A good example: Confluent’s Oracle CDC Connector uses Oracle’s XStream API and delivers “GoldenGate-level performance”, with guaranteed ordering, high throughput, and minimal latency. This enables real-time delivery of operational data into Kafka, Flink, and downstream systems like Databricks.
Bottom line: Confluent offers the most mature, scalable, and flexible ingestion capabilities into Databricks—especially for real-time operational data. For enterprises already using Confluent as the central nervous system of their architecture, adding another ETL layer specifically for the lakehouse integration with weaker coverage and SLAs only slows progress and increases cost.
Stick with a unified approach—fewer moving parts, faster implementation, and end-to-end consistency.
Real-Time vs. Batch: When to Use Each
Batch ETL is well understood. It works fine when data does not need to be processed immediately—e.g., for end-of-day reports, monthly audits, or historical analysis.
Streaming ETL is best when data must be processed in motion. This enables real-time dashboards, live alerts, or AI features based on the latest information.
Confluent DSP is purpose-built for streaming ETL. Kafka and Flink allow filtering, transformation, enrichment, and routing in real time.
Databricks supports batch ELT natively. Delta Live Tables offers a managed way to build data pipelines on top of Spark. Delta Live Tables lets you declaratively define how data should be transformed and processed using SQL or Python. On the other side, Spark Structured Streaming can handle streaming data in near real-time. But it still requires persistent clusters and infrastructure management.
If you’re already invested in Spark, Structured Streaming or Delta Live Tables might be sufficient. But if you’re starting fresh—or looking to simplify your architecture — Confluent’s Tableflow provides a more streamlined, Kafka-native alternative. Tableflow represents Kafka streams as Delta Lake tables. No cluster management. No offset handling. Just discoverable, governed data in Databricks Unity Catalog.
Real-Time and Batch: A Perfect Match at Walmart for Replenishment Forecasting in the Supply Chain
Walmart demonstrates how real-time and batch processing can work together to optimize a large-scale, high-stakes supply chain.
At the heart of this architecture is Apache Kafka, powering Walmart’s real-time inventory management and replenishment system.
Kafka serves as the central data hub, continuously streaming inventory updates, sales transactions, and supply chain events across Walmart’s physical stores and digital channels. This enables real-time replenishment to ensure product availability and timely fulfillment for millions of online and in-store customers.
Batch processing plays an equally important role. Apache Spark processes historical sales, seasonality trends, and external factors in micro-batches to feed forecasting models. These forecasts are used to generate accurate daily order plans across Walmart’s vast store network.
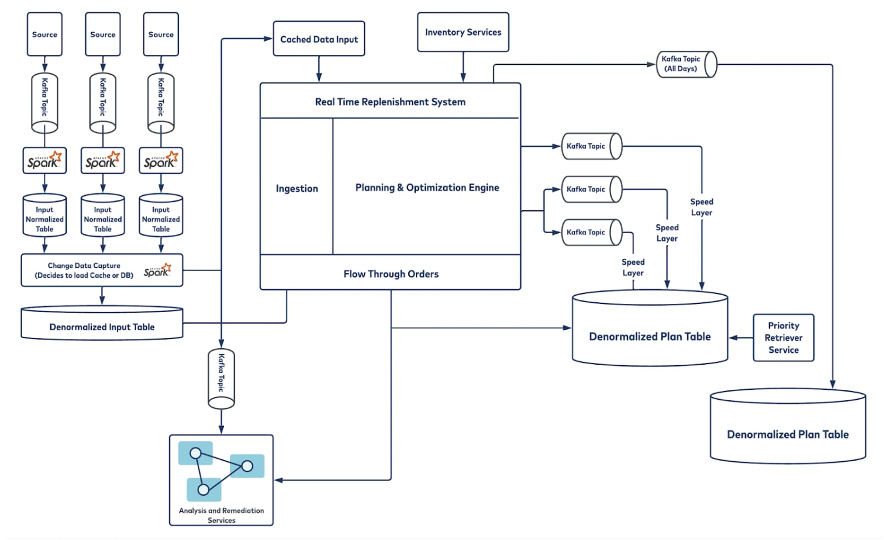
This hybrid architecture brings significant operational and business value:
- Kafka provides not just low latency, but true decoupling between systems, enabling seamless integration across real-time streams, batch pipelines, and request-response APIs—ensuring consistent, reliable data flow across all environments
- Spark delivers scalable, high-performance analytics to refine predictions and improve long-term planning
- The result: reduced cycle times, better accuracy, increased scalability and elasticity, improved resiliency, and substantial cost savings
Walmart’s supply chain is just one of many use cases where Kafka powers real-time business processes, decisioning and workflow orchestration at global scale—proof that combining streaming and batch is key to modern data infrastructure.
Batch as a Subset of Streaming in Apache Flink
Apache Flink supports both streaming and batch processing within the same engine. This enables teams to build unified pipelines that handle real-time events and batch-style computations without switching tools or architectures. In Flink, batch is treated as a special case of streaming—where a bounded stream (or a complete window of events) can be processed once all data has arrived.
This approach simplifies operations by avoiding the need for parallel pipelines or separate orchestration layers. It aligns with the principles of the shift-left architecture, allowing earlier processing, validation, and enrichment—closer to the data source. As a result, pipelines are more maintainable, scalable, and responsive.
That said, batch processing is not going away—nor should it. For many use cases, batch remains the most practical solution. Examples include:
- Daily financial reconciliations
- End-of-day retail reporting
- Weekly churn model training
- Monthly compliance and audit jobs
In these cases, latency is not critical, and workloads often involve large volumes of historical data or complex joins across datasets.
This is where Databricks excels—especially with its Delta Lake and Medallion architecture, which structures raw, refined, and curated data layers for high-performance analytics, BI, and AI/ML training.
In summary, Flink offers the flexibility to consolidate streaming and batch pipelines, making it ideal for unified data processing. But when batch is the right choice—especially at scale or with complex transformations—Databricks remains a best-in-class platform. The two technologies are not mutually exclusive. They are complementary parts of a modern data stack.
Streaming CDC and Lakehouse Analytics
Streaming CDC is a key integration pattern. It captures changes from operational databases and pushes them into analytics platforms. But CDC isn’t limited to databases. CDC is just as important for business applications like Salesforce, where capturing customer updates in real time enables faster, more responsive analytics and downstream actions.
Confluent is well suited for this. Kafka Connect and Flink can continuously stream changes. These change events are sent to Databricks as Delta tables using Tableflow. Streaming CDC ensures:
- Data consistency across operational and analytical workloads leveraging a single data pipeline
- Reduced ETL / ELT lag
- Near real-time updates to BI dashboards
- Timely training of AI/ML models
Streaming CDC also avoids data duplication, reduces latency, and minimizes storage costs.
Reverse ETL: An (Anti) Pattern to Avoid with Confluent and Databricks
Some architectures push data from data lakes or warehouses back into operational systems using reverse ETL. While this may appear to bridge the analytical and operational worlds, it often leads to increased latency, duplicate logic, and fragile point-to-point workflows. These tools typically reprocess data that was already transformed once, leading to inefficiencies, governance issues, and unclear data lineage.
Reverse ETL is an architectural anti-pattern. It violates the principles of an event-driven system. Rather than reacting to events as they happen, reverse ETL introduces delays and additional moving parts—pushing stale insights back into systems that expect real-time updates.
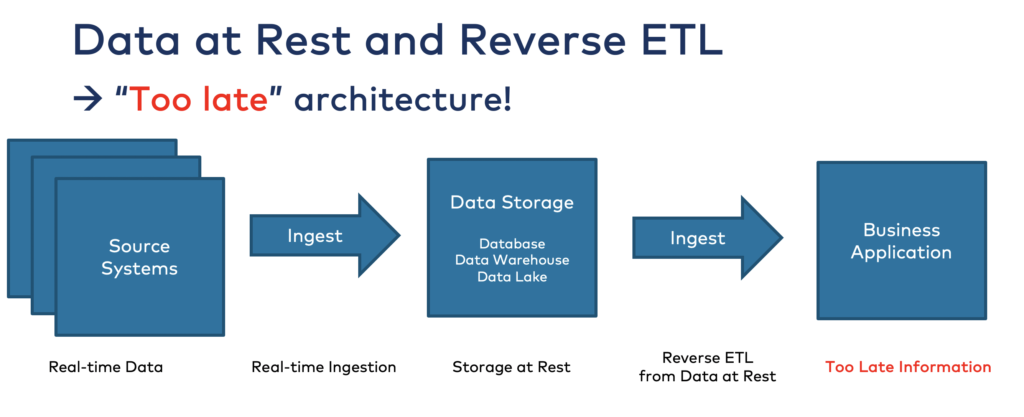
With the upcoming bidirectional integration of Tableflow with Delta Lake, these issues can be avoided entirely. Insights generated in Databricks—from analytics, machine learning, or rule-based engines—can be pushed directly back into Kafka topics.
This approach removes the need for reverse ETL tools, reduces system complexity, and ensures that both operational and analytical layers operate on a shared, governed, and timely data foundation.
It also brings lineage, schema enforcement, and observability into both directions of data flow—streamlining feedback loops and enabling true event-driven decisioning across the enterprise.
In short: Don’t pull data back into operational systems after the fact. Push insights forward at the speed of events.
Multi-Cloud and Hybrid Integration with an Event-Driven Architecture
Confluent is designed for distributed data movement across environments in real-time for operational and analytical use cases:
- On-prem, cloud, and edge
- Multi-region and multi-cloud
- Support for SaaS, BYOC, and private networking
Features like Cluster Linking and Schema Registry ensure consistent replication and governance across environments.
Databricks runs only in the cloud. It supports hybrid access and partner integrations. But the platform is not built for event-driven data distribution across hybrid environments.
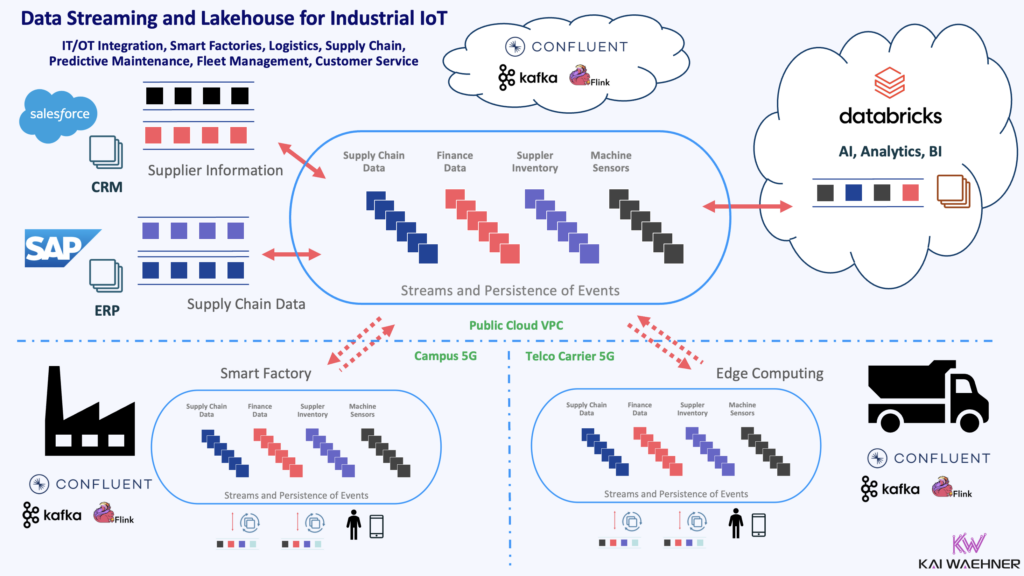
In a hybrid architecture, Confluent acts as the bridge. It moves operational data securely and reliably. Then, Databricks can consume it for analytics and AI use cases. Here is an example architecture for industrial IoT use cases:
Uniper: Real-Time Energy Trading with Confluent and Databricks
Uniper, a leading international energy company, leverages Confluent and Databricks to modernize its energy trading operations.
I covered the value of data streaming with Apache Kafka and Flink for energy trading in a dedicated blog post already.
Confluent Cloud with Apache Kafka and Apache Flink provides a scalable real-time data streaming foundation for Uniper, enabling efficient ingestion and processing of market data, IoT sensor inputs, and operational events. This setup supports the full trading lifecycle, improving decision-making, risk management, and operational agility.
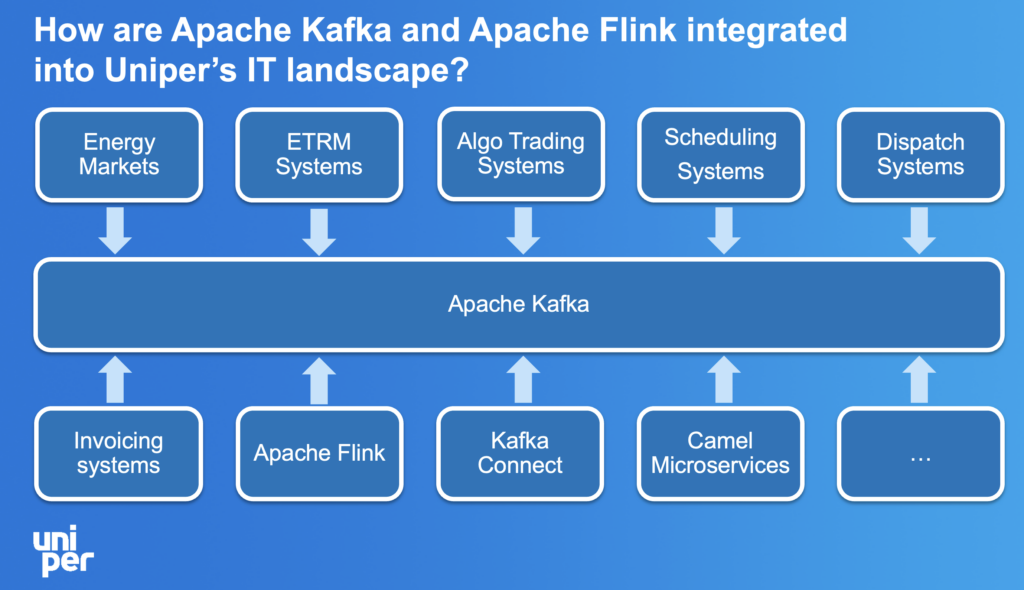
Within its Azure environment, Uniper uses Databricks to empower business users to rapidly build trading decision-support tools and advanced analytics applications. By combining a self-service data platform with scalable processing power, Uniper significantly reduces the lead time for developing data apps—from weeks to just minutes.
To deliver real-time insights to its teams, Uniper also leverages Plotly’s Dash Enterprise, creating interactive dashboards that consolidate live data from Databricks, Kafka, Snowflake, and various databases. This end-to-end integration enables dynamic, collaborative workflows, giving analysts and traders fast, actionable insights that drive smarter, faster trading strategies.
By combining real-time data streaming, advanced analytics, and intuitive visualization, Uniper has built a resilient, flexible data architecture that meets the demands of today’s fast-moving energy markets.
From Ingestion to Insight: Modern Data Integration and Processing for AI with Confluent and Databricks
While both platforms can handle integration and processing, their roles are different:
- Use Confluent when you need real-time ingestion and processing of operational and analytical workloads, or data delivery across systems and clouds.
- Use Databricks for AI workloads, analytics and data warehousing.
When used together, Confluent and Databricks form a complete data integration and processing pipeline for AI and analytics:
- Confluent ingests and processes operational data in real time.
- Tableflow pushes this data into Delta Lake in a discoverable, secure format.
- Databricks performs analytics and model development.
- Tableflow (bidirectional) pushes insights or AI models back into Kafka for use in operational systems.
This is the foundation for modern data and AI architectures—real-time pipelines feeding intelligent applications.
Stay tuned for deep dives into how these platforms are shaping the future of data-driven enterprises. Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And download my free book about data streaming use cases, including technical architectures and the relation to analytical platforms like Databricks.





