The modern data landscape is shaped by platforms that excel in different but increasingly overlapping domains. Confluent leads in data streaming with enterprise-grade infrastructure for real-time data movement and processing. Databricks and Snowflake dominate the lakehouse and analytics space—each with unique strengths. Databricks is known for scalable AI and machine learning pipelines, while Snowflake stands out for its simplicity, governed data sharing, and performance in cloud-native analytics.
This final blog in the series brings together everything covered so far and highlights how these technologies power real customer innovation. At Erste Bank, Confluent and Databricks are combined to build an event-driven architecture for Generative AI use cases in customer service. At Siemens, Confluent and Snowflake support a shift-left architecture to drive real-time manufacturing insights and medical AI—using streaming data not just for analytics, but also to trigger operational workflows across systems.
Together, these examples show why so many enterprises adopt a multi-platform strategy—with Confluent as the event-driven backbone, and Databricks or Snowflake (or both) as the downstream platforms for analytics, governance, and AI.

About the Confluent and Databricks Blog Series
This article is part of a blog series exploring the growing roles of Confluent and Databricks in modern data and AI architectures:
- Blog 1: The Past, Present and Future of Confluent (The Kafka Company) and Databricks (The Spark Company)
- Blog 2: Confluent Data Streaming Platform vs. Databricks Data Intelligence Platform for Data Integration and Processing
- Blog 3: Shift-Left Architecture for AI and Data Warehousing with Confluent and Databricks
- Blog 4: Databricks and Confluent in Enterprise Software Environments (with SAP as Example)
- Blog 5 (THIS ARTICLE): Databricks and Confluent Leading Data and AI Architectures – and How They Compare to Competitors
Learn how these platforms will affect data use in businesses in future articles. Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And download my free book about data streaming use cases, including technical architectures and the relation to analytical platforms like Databricks and Snowflake.
The Broader Data Streaming and Lakehouse Landscape
The data streaming and lakehouse space continues to expand, with a variety of platforms offering different capabilities for real-time processing, analytics, and storage.
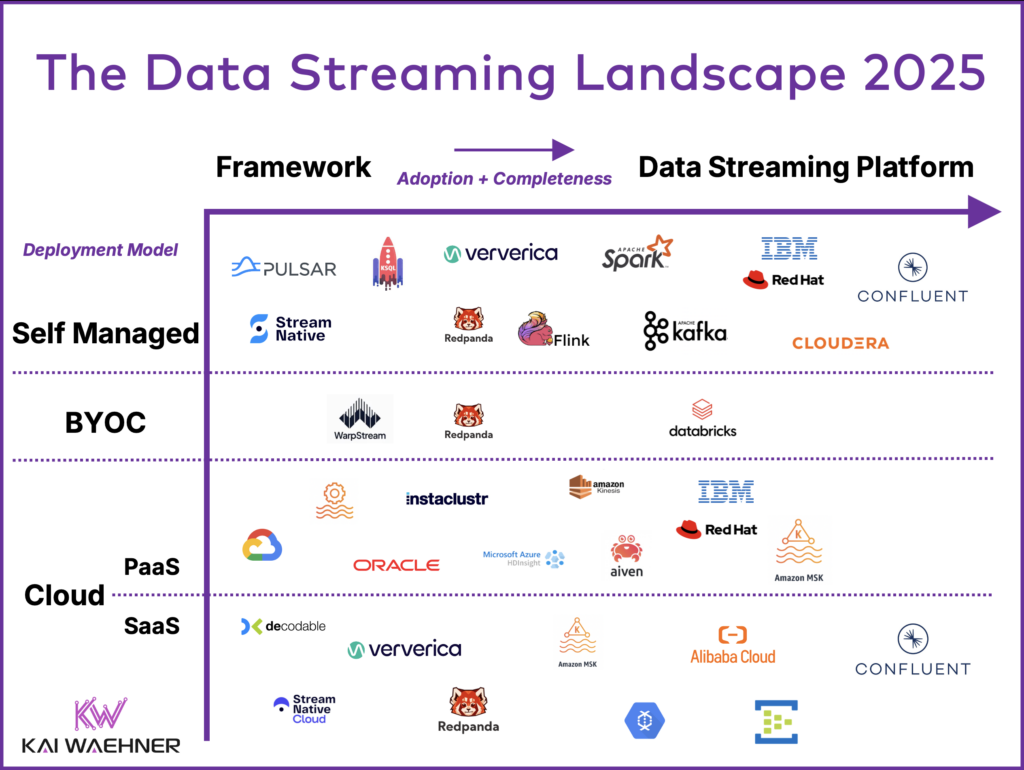
Data Streaming Market
On the data streaming side, Confluent is the leader. Other cloud-native services like Amazon MSK, Azure Event Hubs, and Google Cloud Managed Kafka provide Kafka-compatible offerings, though they vary in protocol support, ecosystem maturity, and operational simplicity. StreamNative, based on Apache Pulsar, competes with the Kafka offerings, while Decodable and DeltaStream leverage Apache Flink for real-time stream processing using a complementary approach. Startups such as AutoMQ and BufStream pitch reimagining Kafka infrastructure for improved scalability and cost-efficiency in cloud-native architectures.
The data streaming landscape is growing year by year. Here is the latest overview of the data streaming market:
Lakehouse Market
In the lakehouse and analytics platform category, Databricks leads with its cloud-native model combining compute and storage, enabling modern lakehouse architectures. Snowflake is another leading cloud data platform, praised for its ease of use, strong ecosystem, and ability to unify diverse analytical workloads. Microsoft Fabric aims to unify data engineering, real-time analytics, and AI on Azure under one platform. Google BigQuery offers a serverless, scalable solution for large-scale analytics, while platforms like Amazon Redshift, ClickHouse, and Athena serve both traditional and high-performance OLAP use cases.
The Forrester Wave for Lakehouses analyzes and explores the vendor options, showing Databricks, Snowflake and Google as the leaders. Unfortunately, it is not allowed to post the Forrester Wave, so you need to download it from a vendor.
Confluent + Databricks
This blog series highlights Databricks and Confluent because they represent a powerful combination at the intersection of data streaming and the lakehouse paradigm. Together, they enable real-time, AI-driven architectures that unify operational and analytical workloads across modern enterprise environments.
Each platform in the data streaming and Lakehouse space has distinct advantages, but none offer the same combination of real-time capabilities, open architecture, and end-to-end integration as Confluent and Databricks.
It’s also worth noting that open source remains a big – if not the biggest – competitor to all of these vendors. Many enterprises still rely on open-source data lakes built on Elastic, legacy Hadoop, or open table formats such as Apache Hudi—favoring flexibility and cost control over fully managed services.
Confluent: The Leading Data Streaming Platform (DSP)
Confluent is the enterprise-standard platform for data streaming, built on Apache Kafka and extended for cloud-native, real-time operations at global scale. The data streaming platform (DSP) delivers a complete and unified platform with multiple deployment options to meet diverse needs and budgets:
- Confluent Cloud – Fully managed, serverless Kafka and Flink service across AWS, Azure, and Google Cloud
- Confluent Platform – Self-managed software for on-premises, private cloud, or hybrid environments
- WarpStream – Kafka-compatible, cloud-native infrastructure optimized for BYOC (Bring Your Own Cloud) using low-cost object storage like S3
Together, these options offer cost efficiency and flexibility across a wide range of streaming workloads:
- Small-volume, mission-critical use cases such as payments or fraud detection, where zero data loss, strict SLAs, and low latency are non-negotiable
- High-volume, analytics-driven use cases like clickstream processing for real-time personalization and recommendation engines, where throughput and scalability are key
Confluent supports these use cases with:
- Cluster Linking for real-time, multi-region and hybrid cloud data movement
- 100+ prebuilt connectors for seamless integration with enterprise systems and cloud services
- Apache Flink for rich stream processing at scale
- Governance and observability with Schema Registry, Stream Catalog, role-based access control, and SLAs
- Tableflow for native integration with Delta Lake, Apache Iceberg, and modern lakehouse architectures
While other providers offer fragments—such as Amazon MSK for basic Kafka infrastructure or Azure Event Hubs for ingestion—only Confluent delivers a unified, cloud-native data streaming platform with consistent operations, tooling, and security across environments.
Confluent is trusted by over 6,000 enterprises and backed by deep experience in large-scale streaming deployments, hybrid architectures, and Kafka migrations. It combines industry-leading technology with enterprise-grade support, expertise, and consulting services to help organizations turn real-time data into real business outcomes—securely, efficiently, and at any scale.
Databricks: The Leading Lakehouse for AI and Analytics
Databricks is the leading platform for unified analytics, data engineering, and AI—purpose-built to help enterprises turn massive volumes of data into intelligent, real-time decision-making. Positioned as the Data Intelligence Platform, Databricks combines a powerful lakehouse foundation with full-spectrum AI capabilities, making it the platform of choice for modern data teams.
Its core strengths include:
- Delta Lake + Unity Catalog – A robust foundation for structured, governed, and versioned data at scale
- Apache Spark – Distributed compute engine for ETL, data preparation, and batch/stream processing
- MosaicML – End-to-end tooling for efficient model training, fine-tuning, and deployment of custom AI models
- AI/ML tools for data scientists, ML engineers, and analysts—integrated across the platform
- Native connectors to BI tools (like Power BI, Tableau) and MLOps platforms for model lifecycle management
Databricks directly competes with Snowflake, especially in the enterprise AI and analytics space. While Snowflake shines with simplicity and governed warehousing, Databricks differentiates by offering a more flexible and performant platform for large-scale model training and advanced AI pipelines.
The platform supports:
- Batch and (sort of) streaming analytics
- ML model training and inference on shared data
- GenAI use cases, including RAG (Retrieval-Augmented Generation) with unstructured and structured sources
- Data sharing and collaboration across teams and organizations with open formats and native interoperability
Databricks is trusted by thousands of organizations for AI workloads, offering not only powerful infrastructure but also integrated governance, observability, and scalability—whether deployed on a single cloud or across multi-cloud environments.
Combined with Confluent’s real-time data streaming capabilities, Databricks completes the AI-driven enterprise architecture by enabling organizations to analyze, model, and act on high-quality, real-time data at scale.
Stronger Together: A Strategic Alliance for Data and AI with Tableflow and Delta Lake
Confluent and Databricks are not trying to replace each other. Their partnership is strategic and product-driven.
Recent innovation: Tableflow + Delta Lake – this feature enables bi-directional data exchange between Kafka and Delta Lake.
- Direction 1: Confluent streams → Tableflow → Delta Lake (via Unity Catalog)
- Direction 2: Databricks insights → Tableflow → Kafka → Flink or other operational systems
This simplifies architecture, reduces cost and latency, and removes the need for Spark jobs to manage streaming data.
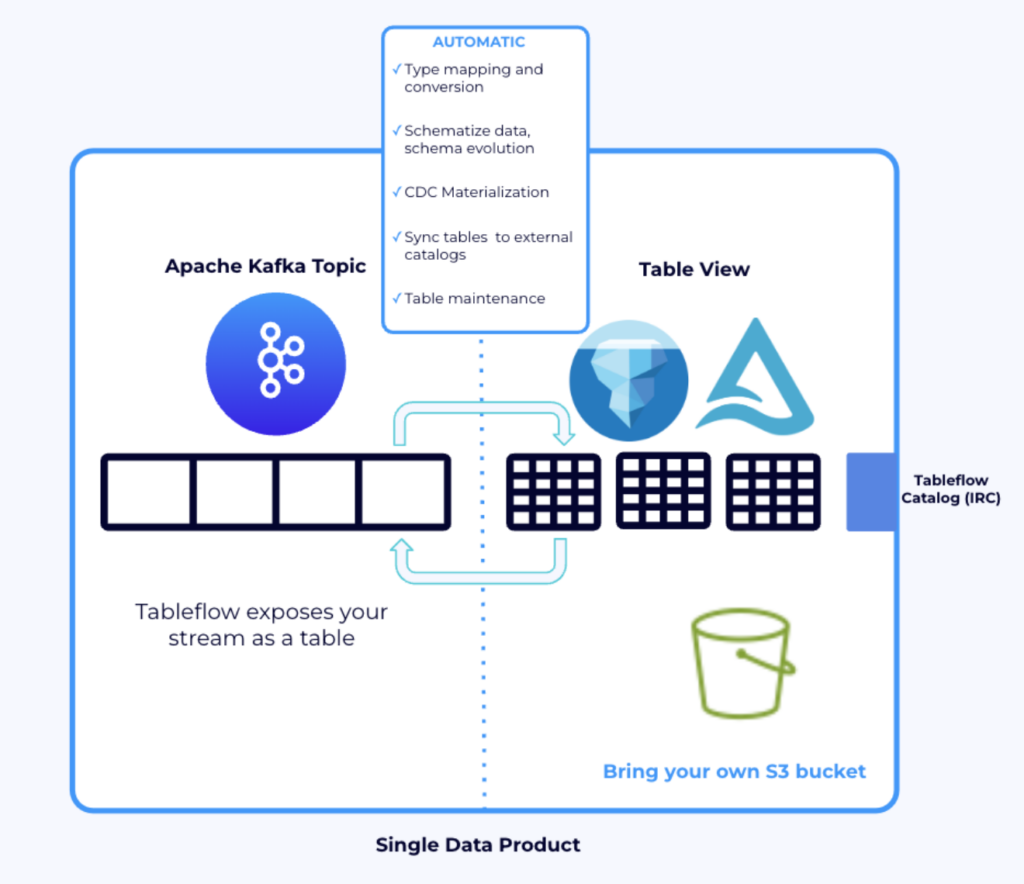
Confluent becomes the operational data backbone for AI and analytics. Databricks becomes the analytics and AI engine fed with data from Confluent.
Where needed, operational or analytical real-time AI predictions can be done within Confluent’s data streaming platform: with embedded or remote model inference, native integration for search with vector databases, and built-in models for common predictive use cases such as forecasting.
Erste Bank: Building a Foundation for GenAI with Confluent and Databricks
Erste Group Bank AG, one of the largest financial services providers in Central and Eastern Europe, is leveraging Confluent and Databricks to transform its customer service operations with Generative AI. Recognizing that successful GenAI initiatives require more than just advanced models, Erste Bank first focused on establishing a solid foundation of real-time, consistent, and high-quality data leveraging data streaming and an event-driven architecture.
Using Confluent, Erste Bank connects real-time streams, batch workloads, and request-response APIs across its legacy and cloud-native systems in a decoupled way but ensuring data consistency through Kafka. This architecture ensures that operational and analytical data — whether from core banking platforms, digital channels, mobile apps, or CRM systems — flows reliably and consistently across the enterprise. By integrating event streams, historical data, and API calls into a unified data pipeline, Confluent enables Erste Bank to create a live, trusted digital representation of customer interactions.
With this real-time foundation in place, Erste Bank leverages Databricks as its AI and analytics platform to build and scale GenAI applications. At the Data in Motion Tour 2024 in Frankfurt, Erste Bank presented a pilot project where customer service chatbots consume contextual data flowing through Confluent into Databricks, enabling intelligent, personalized responses. Once a customer request is processed, the chatbot triggers a transaction back through Kafka into the Salesforce CRM, ensuring seamless, automated follow-up actions.
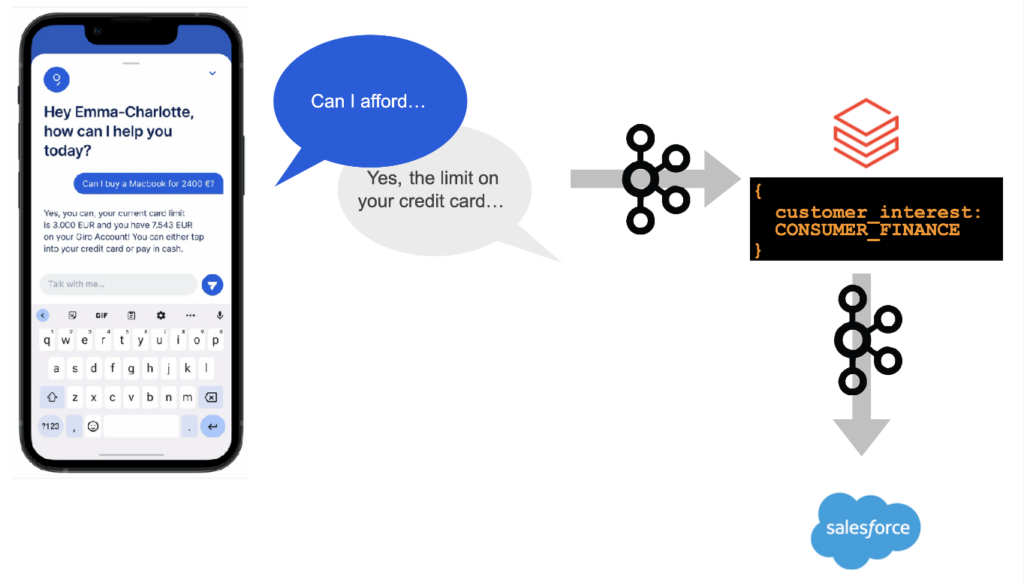
By combining Confluent’s real-time data streaming capabilities with Databricks’ powerful AI infrastructure, Erste Bank is able to:
- Deliver highly contextual, real-time customer service interactions
- Automate CRM workflows through real-time event-driven architectures
- Build a scalable, resilient platform for future AI-driven applications
This architecture positions Erste Bank to continue expanding GenAI use cases across financial services, from customer engagement to operational efficiency, powered by consistent, trusted, and real-time data.
Confluent: The Neutral Streaming Backbone for Any Data Stack
Confluent is not tied to a monolithic compute engine within a cloud provider. This neutrality is a strength:
- Bridges operational systems (mainframes, SAP) with modern data platforms (AI, lakehouses, etc.)
- An event-driven architecture built with a data streaming platform feeds multiple lakehouses at once
- Works across all major cloud providers, including AWS, Azure, and GCP
- Operates at the edge, on-prem, in the cloud and in hybrid scenarios
- One size doesn’t fit all – follow best practices from microservices architectures and data mesh to tailor your architecture with purpose-built solutions.
The flexibility makes Confluent the best platform for data distribution—enabling decoupled teams to use the tools and platforms best suited to their needs.
Confluent’s Tableflow also supports Apache Iceberg to enable seamless integration from Kafka into lakehouses beyond Delta Lake and Databricks—such as Snowflake, BigQuery, Amazon Athena, and many other data platforms and analytics engines.
Example: A global enterprise uses Confluent as its central nervous system for data streaming. Customer interaction events flow in real time from web and mobile apps into Confluent. These events are then:
- Streamed into Databricks once for multiple GenAI and analytics use cases.
- Written to an operational PostgreSQL database to update order status and customer profiles
- Pushed into an customer-facing analytics engine like StarTree (powered by Apache Pinot) for live dashboards and real-time customer behavior analytics
- Shared with Snowflake through a lift-and-shift M&A use case to unify analytics from an acquired company
This setup shows the power of Confluent’s neutrality and flexibility: enabling real-time, multi-directional data sharing across heterogeneous platforms, without coupling compute and storage.
Snowflake: A Cloud-Native Companion to Confluent – Natively Integrated with Apache Iceberg and Polaris Catalog
Snowflake pairs naturally with Confluent to power modern data architectures. As a cloud-native SaaS from the start, Snowflake has earned broad adoption across industries thanks to its scalability, simplicity, and fully managed experience.
Together, Confluent and Snowflake unlock high-impact use cases:
- Near real-time ingestion and enrichment: Stream operational data into Snowflake for immediate analytics and action.
- Unified operational and analytical workloads: Combine Confluent’s Tableflow with Snowflake’s Apache Iceberg support through its open source Polaris catalog to bridge operational and analytical data layers.
- Shift-left data quality: Improve reliability and reduce costs by validating and shaping data upstream, before it hits storage.
With Confluent as the streaming backbone and Snowflake as the analytics engine, enterprises get a cloud-native stack that’s fast, flexible, and built to scale. Many enterprises use Confluent as data ingestion platform for Databricks, Snowflake, and other analytical and operational downstream applications.
Shift Left at Siemens: Real-Time Innovation with Confluent and Snowflake
Siemens is a global technology leader operating across industry, infrastructure, mobility, and healthcare. Its portfolio includes industrial automation, digital twins, smart building systems, and advanced medical technologies—delivered through units like Siemens Digital Industries and Siemens Healthineers.
To accelerate innovation and reduce operational costs, Siemens is embracing a shift-left architecture to enrich data early in the pipeline before it reaches Snowflake. This enables reusable, real-time data products in the data streaming platform leveraging an event-driven architecture for data sharing with analytical and operational systems beyond Snowflake.
Siemens Digital Industries applies this model to optimize manufacturing and intralogistics, using streaming ETL to feed real-time dashboards and trigger actions like automated inventory replenishment—while continuing to use Snowflake for historical analysis, reporting, and long-term data modeling.
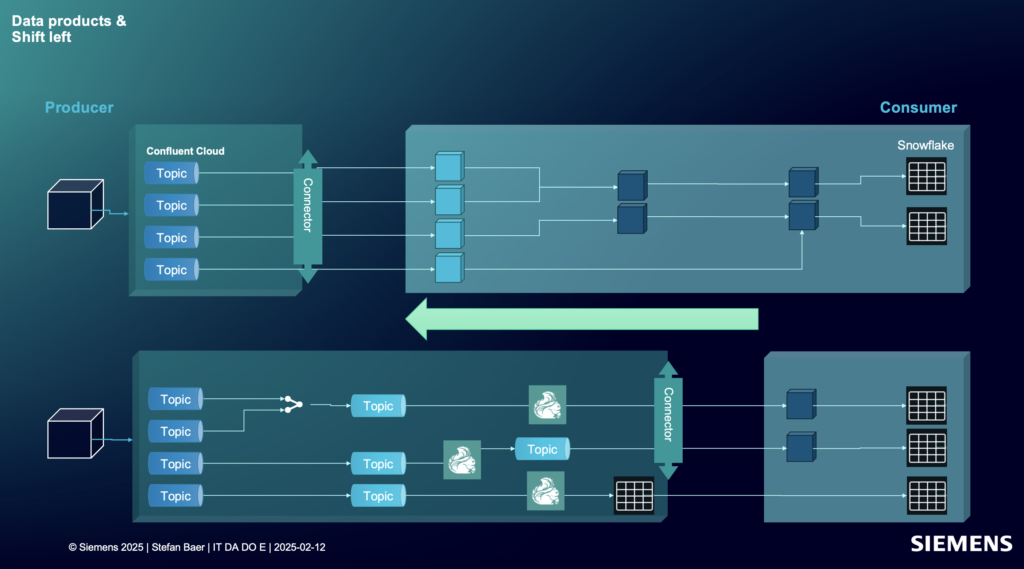
Siemens Healthineers embeds AI directly in the stream processor to detect anomalies in medical equipment telemetry, improving response time and avoiding costly equipment failures—while leveraging Snowflake to power centralized analytics, compliance reporting, and cross-device trend analysis.
These success stories are part of The Data Streaming Use Case Show, my new industry webinar series. Learn more about Siemens’ usage of Confluent and Snowflake and watch the video recording about “shift left”.
Open Outlook: Agentic AI with Model-Context Protocol (MCP) and Agent2Agent Protocol (A2A)
While data and AI platforms like Databricks and Snowflake play a key role, some Agentic AI projects will likely rely on emerging, independent SaaS platforms and specialized tools. Flexibility and open standards are key for future success.
What better way to close a blog series on Confluent and Databricks (and Snowflake) than by looking ahead to one of the most exciting frontiers in enterprise AI: Agentic AI.
As enterprise AI matures, there is growing interest in bi-directional interfaces between operational systems and AI agents. Google’s A2A (Agent-to-Agent) architecture reinforces this shift—highlighting how intelligent agents can autonomously communicate, coordinate, and act across distributed systems.
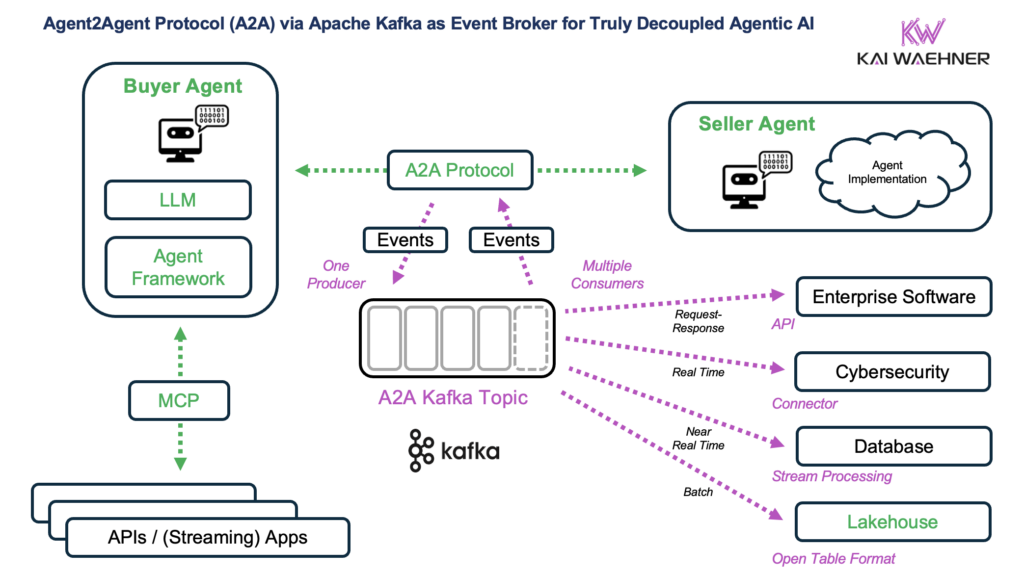
Confluent + Databricks is an ideal combination to support these emerging Agentic AI patterns, where event-driven agents continuously learn from and act upon streaming data. Models can be embedded directly in Flink for low-latency applications or hosted and orchestrated in Databricks for more complex inference workflows.
The Model-Context-Protocol (MCP) is gaining traction as a design blueprint for standardized interaction between services, models, and event streams. In this context, Confluent and Databricks are well positioned to lead:
- Confluent: Event-driven delivery of context, inputs, and actions
- Databricks: Model hosting, training, inference, and orchestration
- Jointly: Closed feedback loops between business systems and AI agents
Together with protocols like A2A and MCP, this architecture will shape the next generation of intelligent, real-time enterprise applications.
Confluent + Databricks: The Future-Proof Data Stack for AI and Analytics
Databricks and Confluent are not just partners. They are leaders in their respective domains. Together, they enable real-time, intelligent data architectures that support operational excellence and AI innovation.
Other AI and data platforms are part of the landscape, and many bring valuable capabilities. As explored in this blog series, the true decoupling using an event-driven architecture with Apache Kafka allows using any kind of combination of vendors and cloud services. I see many enterprises using Databricks and Snowflake integrated to Confluent. However, the alignment between Confluent and Databricks stands out due to its combination of strengths:
- Confluent’s category leadership in data streaming, powering thousands of production deployments across industries
- Databricks’ strong position in the lakehouse and AI space, with broad enterprise adoption for analytics and machine learning
- Shared product vision and growing engineering and go-to-market alignment across technical and field organizations
For enterprises shaping a long-term data and AI strategy, this combination offers a proven, scalable foundation—bridging real-time operations with analytical depth, without forcing trade-offs between speed, flexibility, or future-readiness.
Stay tuned for deep dives into how these platforms are shaping the future of data-driven enterprises. Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And download my free book about data streaming use cases, including technical architectures and the relation to analytical platforms like Databricks and Snowflake.