
Is Apache Kafka really real-time? This is a question I get asked every week. Real-time is a great marketing term to describe how businesses can add value by processing data as fast as possible. Most software and product vendors use it these days. Including messages frameworks (e.g., IBM MQ, RabbitMQ), event streaming platforms (e.g., Apache Kafka, Confluent), data warehouse/analytics vendors (e.g., Spark, Snowflake, Elasticsearch), and security / SIEM products (e.g., Splunk). This blog post explores what “real-time” really means and how Apache Kafka and other messaging frameworks accomplish the mission of providing real-time data processing.
Definition: What is real-time?
The definition of the term “real-time” is not easy. However, it is essential to define it before you start any discussion about this topic.
In general, real-time computing (sometimes called reactive computing) is the computer science term for hardware and software systems subject to a “real-time constraint”, for example, from event to system response. Real-time programs must guarantee a response within specified time constraints, often referred to as “deadlines”. Real-time processing fails if not completed within a specified deadline relative to an event; deadlines must always be met, regardless of system load.
Hard vs. soft vs. near real-time
Unfortunately, there is more than one “real-time”. The graphic from embedded.com describes it very well:
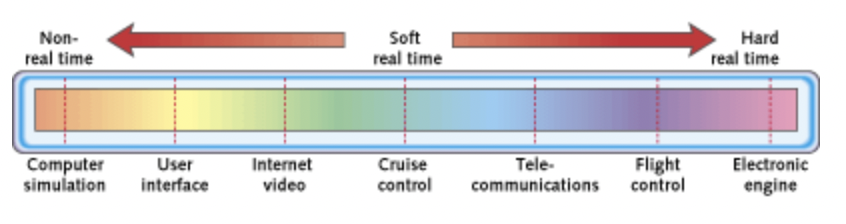
Here are a few different nuances of real-time data processing:
- Real-time: This is the marketing term. It can be anything from zero latency and zero spikes to minutes and beyond.
- Hard real-time: Missing a deadline is a total system failure. Delays or spikes are not accepted. Hence, the goal is to ensure that all deadlines are met,
- Soft real-time: The usefulness of a result degrades after its deadline, thereby degrading the system’s quality of service. The goal becomes meeting a certain subset of deadlines to optimize some application-specific criteria. The particular criteria optimized depend on the application.
- Near real-time: Refers to the time delay introduced, by automated data processing or network transmission, between the occurrence of an event and the use of the processed data. The range goes from microseconds and milliseconds to seconds, minutes, and sometimes even hours or days.
Technical implementation of hard real-time
From a more technical point of view, hard real-time is a synchronous push operation. The caller invokes something and must wait for the return. This cannot be implemented with event distribution effectively. It is rather an API call. Soft- and near real-time are asynchronous. The caller propagates an event but others do not affect the outcome.
Hermann Kopetz’s book “Real-Time Systems: Design Principles for Distributed Embedded Applications” is a great resource if you want to dig deeper. The Wikipedia article is also a good, detailed summary with further references.
Always question what is meant by the term “real-time” if the context is not clear yet. While it is not always accurate, it is okay to use the term “real-time” in many cases, especially when you talk to business people.
The use cases in the next sections will make different real-time scenarios more clear.
Use cases for hard real-time
Hard real-time requires a deterministic network with zero latency and no spikes. Common scenarios include embedded systems, field bus and PLCs in manufacturing, cars, robots, etc. Time-Sensitive Networking (TSN) is the right keyword if you want to do more research. TSN is a set of standards under development by the Time-Sensitive Networking task group of the IEEE 802.1 working group.
This is NOT Java, NOT Cloud, and NOT anything else a web developer knows and uses for daily routine.
Examples of hard real-time
Here are a few examples that are only doable (and safe) with hard real-time:
- A car engine control system is a hard real-time system because a delayed signal may cause engine failure or damage. This gets even more important with autonomous vehicles.
- Medical systems, such as heart pacemakers. Even though a pacemaker’s task is simple, because of the potential risk to human life, medical systems like these are typically required to undergo thorough testing and certification, which in turn requires hard real-time computing to offer provable guarantees that a failure is unlikely or impossible.
- Industrial process controllers, such as a machine on an assembly line. If the machine is delayed, the item on the assembly line could pass beyond the machine’s reach (leaving the product untouched), or the machine or the product could be damaged by activating the robot at the wrong time. If the failure is detected, both cases will lead to the assembly line stopping, which slows production. When the failure is not detected, a product with a defect could make it through production or could cause damage later production steps.
- Hard real-time systems are typically found interacting at a low level with physical hardware in embedded systems.
Most hard real-time implementations are proprietary and have a long history. Nevertheless, the industry is getting more and more open. Industry 4.0, Industrial IoT, autonomous driving, smart cities, and similar scenarios are impossible without an open architecture.
Use cases for soft real-time and near real-time
Soft real-time or near real-time is what most people actually talk about when they say “real-time”. The use cases include everything that is not “hard real-time”. End-to-end communication has latency, delays, and spikes. Near real-time can be very fast, but also take a long time. Most use cases across all verticals sit in this category.
Some verticals such as retailing or gaming might never have to think about hard real-time at all. Even though, if you dig deeper, retailing also often have production lines. Gaming also has game consoles and hardware. Hence, it always depends on your business department.
Examples of soft real-time
Some examples of soft/near real-time use cases:
- High-frequency trading on financial or energy markets. Messaging and processing typically have to happen in microseconds. This is probably the closest alternative to hard real-time. Only specific proprietory stream processing products such as TIBCO StreamBase or Software AG’s Apama can do this. Honestly, I am not aware of many other use cases where this speed is required and worth the trade-offs (such as high license cost, proprietary system, often single-server instead of distributed system, etc).
- Point-to-point message queuing is the most well-known approach to send data from A to B in near real-time. Alternatives include traditional, proprietary products like IBM MQ, and open source frameworks such as RabbitMQ or NATS. The big problem of message queues is that the real added value comes when the data is also used “now” instead of “too late”. Just sending the data to a database does not help. Hence, a near real-time processing framework is a mandatory combination for many use cases.
- Context-specific data processing and data correlation (often called event streaming or event stream processing) to provide the right information at the right time. This sounds generic but is probably what you require most of the time. No matter what industry or vertical. Apache Kafka is the de facto standard for event streaming, i.e., the combination of messaging, integration, storage, and processing of data. Often, Kafka is combined with dedicated stream processing frameworks such as Apache Flink. Example applications: Fraud detection, omnichannel cross-selling, predictive maintenance, regulatory reporting, or any other digital platform for innovative business models. The presentation “Use Cases and Architectures for Apache Kafka across Industries” covers plenty of examples in more detail.
- Analytics and reporting with data warehouse, data lake, ETL processes, and machine learning aggregates and analyses huge volumes of data. Near real-time can mean seconds (e.g., indexing into a search engine like Elasticsearch or DWH like Snowflake), minutes (e.g., regulatory reporting in financial services), or even hours (e.g., capacity planning for the next day in a supply chain process). Often, the main goal is to store the processed data at rest for further batch analytics with business intelligence tools or provide a human dashboard for operations monitoring.
Always define your meaning of “real-time!
As you can see, “near real-time” can mean many different things. It is okay to say “real-time” to these use cases. Not just in marketing, but also in business and technical meetings! But make sure to understand your requirements and find the appropriate technologies.
I will focus on Apache Kafka as it established itself as the de facto standard for near real-time processing in the market (aka event streaming). However, Kafka is also often used as a messaging platform, and to ingest data into other analytics tools. Hence, it fits into most of the near real-time use cases.
Kafka for real-time requirements? Yes and no!
Kafka is real-time. But not for everybody’s definition of real-time. Let’s understand this better…
Kafka is real-time!
Apache Kafka became the de facto standard for reliable data processing at scale in real-time. Most people agree with this in the IT world. Kafka provides capabilities to process trillions of events per day. Each Kafka broker (= server) can process tens of thousands of messages per second. End-to-end latency from producer to consumer can be as low as ~10ms if the hardware and network setup are good enough. Kafka is battle-tested at thousands of companies for hundreds of different use cases. It uses Apache 2.0 license and provides a huge community and ecosystem. So far so good…
Kafka is not real-time!
However, in the OT world, things are different: Kafka is only soft real-time. Many OT applications require hard real-time. Hence, scenarios around automotive, manufacturing, and smart cities need to make this distinction. Consortiums and standards provide hard real-time frameworks and guidelines on how to integrate with them from the IT side. Two examples:
- MISRA C is a set of software development guidelines for the C programming language developed by MISRA (Motor Industry Software Reliability Association).
- ROS-Industrial is an open-source project that extends ROS software’s advanced capabilities to industrial relevant hardware and applications.
Most companies I have talked to in these industries combine hard real-time and soft real-time. Both approaches are complementary and have different trade-offs.
The following section shows how enterprises combine the OT world (cars, machines, PLCs, robots, etc.) with the IT world (analytics, reporting, business applications).
How to combine Kafka with hard real-time applications
Kafka is not hard real-time, but most enterprises combine it with hard real-time applications to correlate the data, integrate with other systems in near real-time, and build innovative new business applications.
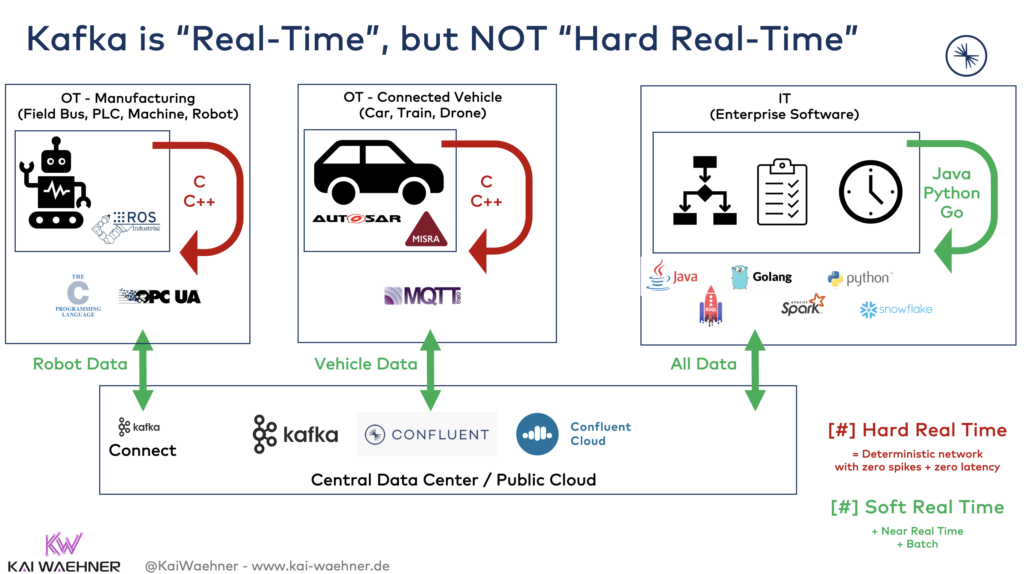
Some notes on the above architecture about the relation between Kafka and the OT world:
- Hard real-time requires C or even lower-level programming with an assembly language that is designed for exactly one specific computer architecture. If you are “lucky”, you are allowed to use C++. Hard real-time is required in automotive ECUs (electronic control unit), Cobots (collaborative robots), and similar things. Safety and zero latency are key. This is not Java! This is not Kafka!
- Most integration scenarios and almost all business applications only require near real-time data processing. Java, Golang, Python, and similar programming languages (and tool stacks/frameworks on top of that) are used because they are much more simple and convenient to use for most people.
- Open standards are mandatory for a connected world with manufacturing 4.0, innovative mobility services, and smart cities. I explored the relationship between proprietary monoliths and open, scalable platforms in the blog post “Apache Kafka as Data Historian – an IIoT / Industry 4.0 Real-Time Data Lake”.”
- Kafka is the perfect tool for integrating the OT and IT world – at scale, reliable, and near real-time. For instance, check out how to build a digital twin with OPC-UA and Kafka or do analytics in a connected car infrastructure with MQTT and Kafka. Sometimes, embedded systems directly integrate with Kafka via Confluent’s C or C++ client, or the REST Proxy for near real-time use cases.
- Kafka runs everywhere. This includes any data center or cloud but also the edge (e.g., a factory or even a vehicle). Check out various use cases where Kafka is deployed at the edge outside the data center.
- Hybrid and global Kafka deployments are the new black. Tools are battle-tested and deployed across all verticals and continents.
Example: Kafka for cybersecurity and SIEM in the smart factory
Let’s conclude this post with a specific example for combining hard real-time systems and near real-time using Apache Kafka: Cybersecurity and SIEM in the smart factory.
Most factories require hard real-time for their machines, PLCs, DCS, robots, etc. Unfortunately, many applications are 10, 20, 30 years, and older. They run on unsecured and unsupported operating systems (Windows XP is still far from going away in factories!)
I have seen a few customers leveraging Apache Kafka as a cybersecurity platform in the middle. I.e., between the monolithic, proprietary legacy systems and the modern IT world.
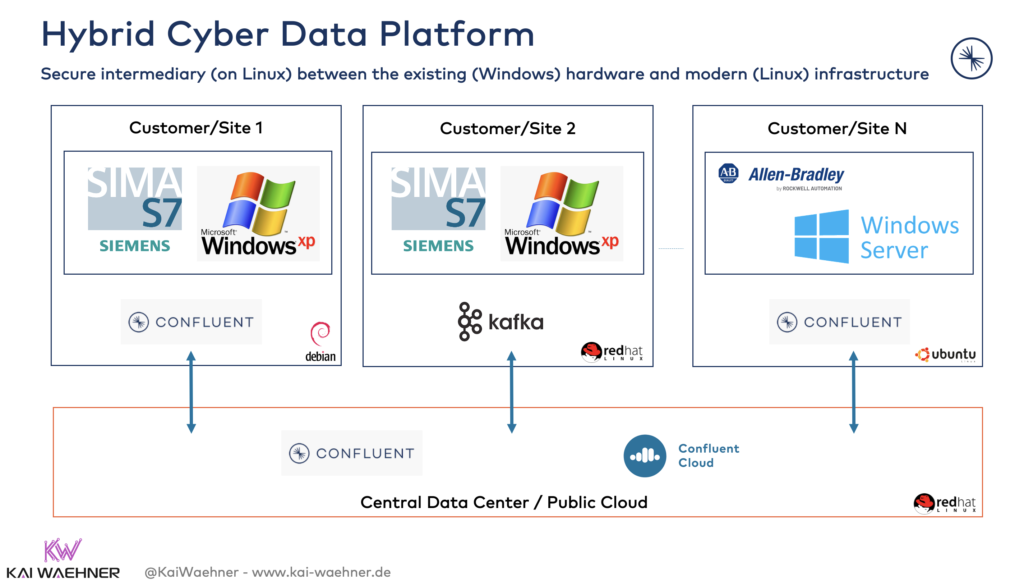
Kafka monitors all data communication in near real-time to implement access control, detect anomalies, and provide secure communication. This architecture enables the integration with non-connected legacy systems to collect sensor data but also ensures that no external system gets access to the unsecured machines. Intel is a great public example for building a modern, scalable cyber intelligence platform with Apache Kafka and Confluent Platform.
One common security design pattern in Industrial IoT is the data diode. Implementations often include a hardware/software combination such as the products from Owl Cyber Defense. Another option is the Kafka Connect based Data Diode Connector (Source and Sink) to build a Kafka-native high-security unidirectional network. In such networks, the network settings do not permit TCP/IP packets and UDP packets are only allowed in one direction.
Soft real-time is what you need for most use cases!
Hard real-time is critical for some use cases, such as car engines, medical systems, and industrial process controllers. However, most other use cases only require near real-time. Apache Kafka comes into play to build scalable, reliable, near real-time applications and connect to the OT world. The open architecture and backpressure handling of huge volumes from IoT interfaces are two of the key reasons why Kafka is such a good fit in OT/IT architectures.
How do you use Kafka for (near) real-time applications? How is it combined with machines, PLCs, cars, and other hard real-time applications? What are your strategy and timeline? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
