
The concepts and architectures of a data warehouse, a data lake, and data streaming are complementary to solving business problems. Storing data at rest for reporting and analytics requires different capabilities and SLAs than continuously processing data in motion for real-time workloads. Many open-source frameworks, commercial products, and SaaS cloud services exist. Unfortunately, the underlying technologies are often misunderstood, overused for monolithic and inflexible architectures, and pitched for wrong use cases by vendors. Let’s explore this dilemma in a blog series. Learn how to build a modern data stack with cloud-native technologies. This is part 3: Data Warehouse Modernization: From Legacy On-Premise to Cloud-Native Infrastructure.

Blog Series: Data Warehouse vs. Data Lake vs. Data Streaming
This blog series explores concepts, features, and trade-offs of a modern data stack using data warehouse, data lake, and data streaming together:
- Data Warehouse vs. Data Lake vs. Data Streaming – Friends, Enemies, Frenemies?
- Data Streaming for Data Ingestion into the Data Warehouse and Data Lake
- THIS POST: Data Warehouse Modernization: From Legacy On-Premise to Cloud-Native Infrastructure
- Case Studies: Cloud-native Data Streaming for Data Warehouse Modernization
- Lessons Learned from Building a Cloud-Native Data Warehouse
Stay tuned for a dedicated blog post for each topic as part of this blog series. I will link the blogs here as soon as they are available (in the next few weeks). Subscribe to my newsletter to get an email after each publication (no spam or ads).
Data warehouse modernization: From legacy on-premise to cloud-native infrastructure
Many people talk about data warehouse modernization when they move to a cloud-native data warehouse. Though, what does data warehouse modernization mean? Why do people move away from their on-premise data warehouse? What are the benefits?
Many projects I have seen in the wild went through the following steps:
- Select a cloud-native data warehouse
- Get data into the new data warehouse
- [Optional] Migrate from the old to the new data warehouse
Let’s explore these steps in more detail and understand the technology and architecture options.
1. Selection of a cloud-native data warehouse
Many years ago, cloud computing was a game-changer for operating infrastructure. AWS innovated by providing not just EC2 virtual machines but also storage, like AWS S3 as a service.
Cloud-native data warehouse offerings are built on the same fundamental change. Cloud providers brought their analytics cloud services, such as AWS Redshift, Azure Synapse, or GCP BigQuery. Independent vendors rolled out a cloud-native data warehouse or data lake SaaS such as Snowflake, Databricks, and many more. While each solution has its trade-offs, a few general characteristics are true for most of them:
- Cloud-native: A modern data warehouse is elastic, scales for small up to extreme workloads, and automates most business processes around development, operations, and monitoring.
- Fully managed: The vendor takes over the operations burden. This includes scaling, failover handling, upgrades, and performance tuning. Some offerings are truly serverless, while many services require capacity planning and manual or automated scaling up and down.
- Consumption-based pricing: Pay-as-you-go enables getting started in minutes and scaling costs with broader software usage. Most enterprise deployments allow commitment to getting price discounts.
- Data sharing: Replicating data sets across regions and environments is a common feature to offer data locality, privacy, lower latency, and regulatory compliance.
- Multi-cloud and hybrid deployments: While cloud providers usually only offer the 1st party service on their cloud infrastructure, 3rd party vendors provide a multi-cloud strategy. Some vendors even offer hybrid environments, including on-premise and edge deployments.
Plenty of comparisons exist in the community, plus analyst research from Gartner, Forrester, et al. Looking at vendor information and trying out the various cloud products using free credits is crucial, too. Finding the right cloud-native data warehouse is its own challenge and not in this blog post.
2. Data streaming as (near) real-time and hybrid integration layer
Data ingestion into data warehouses and data lakes was already covered in part two of this blog series. The more real-time, the better for most business applications. Near real-time ingestion is possible with specific tools (like AWS Kinesis or Kafka) or as part of the data fabric (the streaming data hub where a tool like Kafka plays a bigger role than just data ingestion).
The often more challenging part is data integration. Most data warehouse and data lake pipelines require ETL to ingest data. As the next-generation analytics platform is crucial for making the right business decisions, the data ingestion and integration platform must also be cloud-native! Tools like Kafka provide the reliable and scalable integration layer to get all required data into the data warehouse.
Integration of legacy on-premise data into the cloud-native data warehouse
In a greenfield project, the project team is lucky. Data sources run in the same cloud, using open and modern APIs, and scale as well as the cloud-native data warehouse.
Unfortunately, the reality is brownfield almost always, even if all applications run in public cloud infrastructure. Therefore, the integration and replication of data from legacy and on-premise applications is a general requirement.
Data is typically consumed from legacy databases, data warehouses, applications, and other proprietary platforms. The replication into the cloud data warehouse usually needs to be near real-time and reliable.
A data streaming platform like Kafka is perfect for replicating data across data centers, regions, and environments because of its elastic scalability and true decoupling capabilities. Kafka enables connectivity to modern AND legacy systems via connectors, proprietary APIs, programming languages, or open REST interfaces:
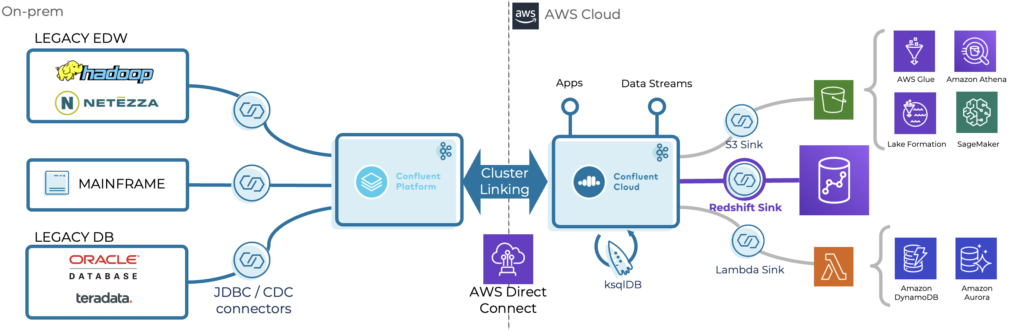
A common scenario in such a brownfield project is the clear separation of concerns and true decoupling between legacy on-premise and modern cloud workloads. Here, Kafka is deployed on-premise to connect to legacy applications.
Tools like MirrorMaker, Replicator, or Confluent Cluster Linking replicate events in real-time into the Kafka cluster in the cloud. The Kafka brokers provide access to the incoming events. Downstream consumers read the data into the data sinks at their own pace; real-time, near real-time, batch, or request-response via API. Streaming ETL is possible at any site – where it makes the most sense from a business or security perspective and is the most cost-efficient.
Example: Confluent Cloud + Snowflake = Cloud-native Data Warehouse Modernization
Here is a concrete example of data warehouse modernization using cloud-native data streaming and data warehousing with Confluent Cloud and Snowflake:
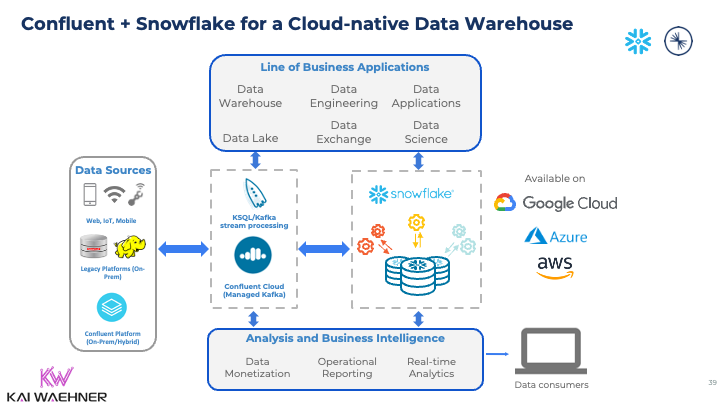
For modernizing the data warehouse, data is ingested from various legacy and modern data sources using different communication paradigms, APIs, and integration strategies. The data is transmitted in motion from data sources via Kafka (and optional preprocessing) into the Snowflake data warehouse. The whole end-to-end pipeline is scalable, reliable, and fully managed, including the connectivity and ingestion between the Kafka and Snowflake clusters.
However, there is more to the integration and ingestion layer: The data streaming platform stores the data for true decoupling and slow downstream applications; not every consumer is or can be real-time. Most enterprise architectures do not ingest data into a single data warehouse or data lake or lakehouse. The reality is that different downstream applications need access to the same information; even though vendors of data warehouses and data lakes tell you differently, of course 🙂
By consuming events from the streaming data hub, each application domain decides by itself if it
- processes events within Kafka with stream processing tools like Kafka Streams or ksqlDB
- builds own downstream applications with its code and technologies (like Java, .NET, Golang, Python)
- integrates with 3rd party business applications like Salesforce or SAP
- ingests the raw or preprocessed and curated data from Kafka into the sink system (like a data warehouse or data lake)
3. Data warehouse modernization and migration from legacy to cloud-native
An often misunderstood concept is the buzz around data warehouse modernization: Companies rarely take the data of the existing on-premise data warehouse or data lake, write a few ETL jobs, and put the data into a cloud-native data warehouse for the sake of doing it.
If you think about a one-time lift-and-shift from an on-premise data warehouse to the cloud, then a traditional ETL tool or a replication cloud service might be the easiest. However, usually, data warehouse modernization is more than that!
What is data warehouse modernization?
A data warehouse modernization can mean many things, including replacing and migrating the existing data warehouse, building a new cloud-native data warehouse from scratch, or optimizing a legacy ETL pipeline of a cloud-native data warehouse.
In all these cases, data warehouse modernization requires business justification, for instance:
- Application issues in the legacy data warehouse, such as too slow data processing with legacy batch workloads, result in wrong or conflicting information for the business people.
- Scalability issues in the on-premise data warehouse as the data volume grows too much.
- Cost issues because the legacy data warehouse does not offer reasonable pricing with pay-as-you-go models.
- Connectivity issues as legacy data warehouses were not built with an open API and data sharing in mind. Cloud-native data warehouses run on cost-efficient and scalable object storage, separate storage from computing, and allow data consumption and sharing. (but keep in mind that Reverse ETL is often an anti-pattern!)
- A strategic move to the cloud with all infrastructure. The analytics platform is no exception if all old and new applications go to the cloud.
Cloud-native applications usually come with innovation, i.e., new business processes, data formats, and data-driven decision-making. From a data warehouse perspective, the best modernization is to start from scratch. Consume data directly from the existing data sources, ETL it, and do business intelligence on top of the new data structures.
I have seen many more projects where customers use change data capture (CDC) from Oracle databases (i.e., the leading core system) instead of trying to replicate data from the legacy data warehouse (i.e., the analytics platform) as scalability, cost, and later shutdown of legacy infrastructure benefits from this approach.
Data warehouse migration: Continuous vs. cut-over
The project is usually a cut-over when you need to do a real modernization (i.e., migration) from a legacy data warehouse to a cloud-native one. This way, the first project phase integrates the legacy data sources with the new data warehouse. The old and new data warehouse platforms operate in parallel, so that old and new business processes go on. After some time (months or years later), when the business is ready to move, the old data warehouse will be shut down after legacy applications are either migrated to the new data warehouse or replaced with new applications:
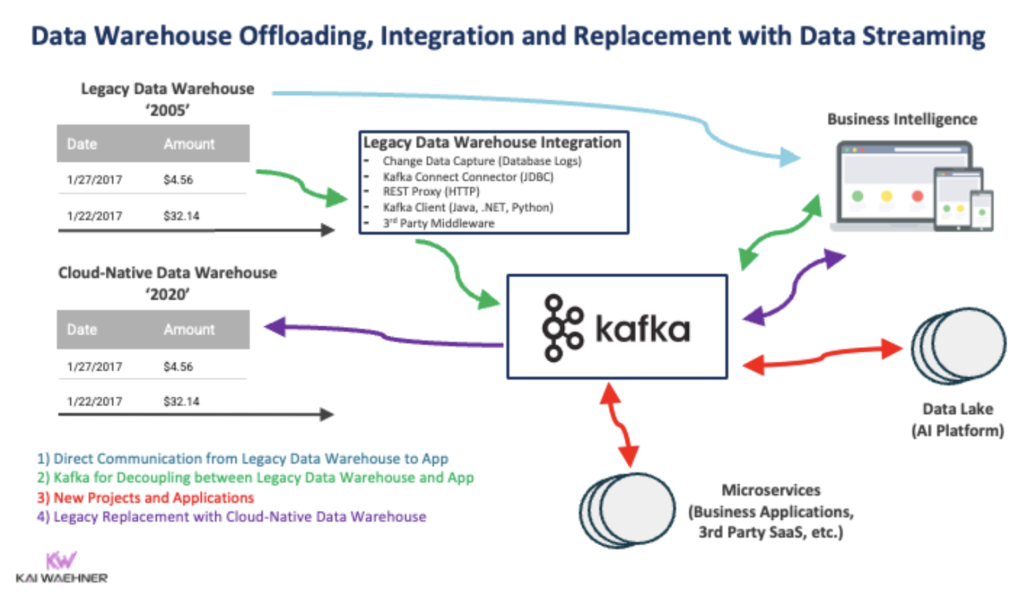
My article “Mainframe Integration, Offloading and Replacement with Apache Kafka” illustrates this offloading and long-term migration process. Just scroll to the section “Mainframe Offloading and Replacement in the Next 5 Years” in that post and replace the term ‘mainframe’ with ‘legacy data warehouse’ in your mind.
A migration and cut-over is its project and can include the legacy data warehouse; or not. Data lake modernization (e.g., from a self- or partially managed Cloudera cluster running on-premise in the data center to a fully managed Databricks or Snowflake cloud infrastructure) follows the same principles. And mixing the data warehouse (reporting) and data lake (big data analytics) into a single infrastructure does not change this either.
Data warehouse modernization is NOT a big bang and NOT a single tool approach!
Most data warehouse modernization projects are ongoing efforts over a long period. You must select a cloud-native data warehouse, get data into the new data warehouse from various sources, and optionally migrate away from legacy on-premise infrastructure.
Data streaming for data ingestion, business applications, or data sharing in real-time should always be a separate component in the enterprise architecture. It has very different requirements regarding SLAs, uptime, through, latency, etc. Putting all real-time and analytical workloads into the same cluster makes little sense from a cost, risk, or business value perspective. The idea of a modern data flow and building a data mesh is the separation of concerns with domain-driven design and focusing on data products (using different, independent APIs, technologies, and cloud services).
For more details, browse other posts of this blog series:
- Data Warehouse vs. Data Lake vs. Data Streaming – Friends, Enemies, Frenemies?
- Data Streaming for Data Ingestion into the Data Warehouse and Data Lake
- THIS POST: Data Warehouse Modernization: From Legacy On-Premise to Cloud-Native Infrastructure
- Case Studies: Cloud-native Data Streaming for Data Warehouse Modernization
- Lessons Learned from Building a Cloud-Native Data Warehouse
What cloud-native data warehouse(s) do you use? How does data streaming fit into your journey? Did you integrate or replace your legacy on-premise data warehouse(s); or start from greenfield in the cloud? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
