
Data Streaming is not a race, it is a Journey! Event-driven architectures and technologies like Apache Kafka or Apache Flink require a mind shift in architecting, developing, deploying, and monitoring applications. Legacy integration, cloud-native microservices, and data sharing across hybrid and multi-cloud setups are the norm, not an exception. This blog post explores success stories from data streaming journeys across industries, including banking, retail, insurance, manufacturing, healthcare, energy & utilities, and software companies.

Data Streaming is a Journey, not a Race!
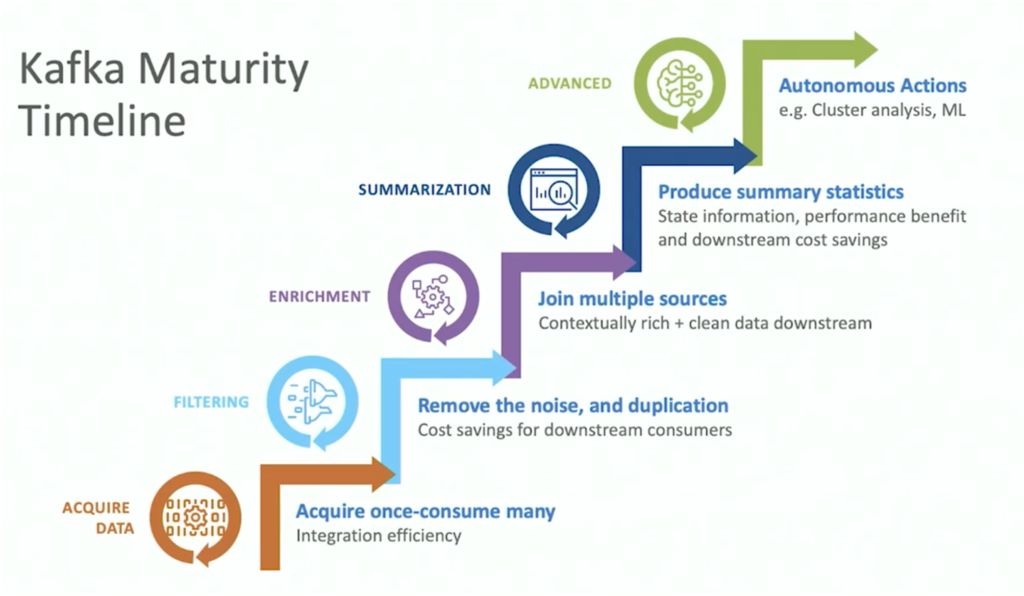
Confluent’s maturity model is used across thousands of customers to analyze the status quo, deploy real-time infrastructure and applications, and plan for a strategic event-driven architecture to ensure success and flexibility in the future of the multi-year data streaming journey:
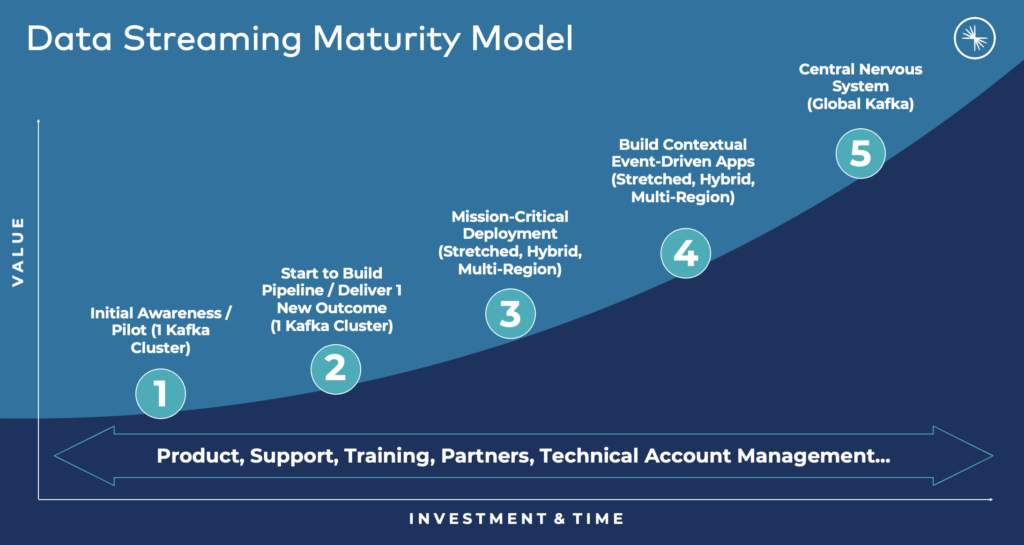
The following sections show success stories from various companies across industries that moved through the data streaming journey. Each journey looks different. Each company has different technologies, vendors, strategies, and legal requirements.
Before we begin, I must stress that these journeys are NOT just successful because of the newest technologies like Apache Kafka, Kubernetes, and public cloud providers like AWS, Azure, and GCP. Success comes with a combination of technologies and expertise.
Consulting – Expertise from Software Vendors and System Integrators
All the below success stories combined open source technologies, software vendors, cloud providers, internal business and technical experts, system integrators, and consultants of software vendors.
Long story short: Technology and expertise are required to make your data streaming journey successful.
We not only sell data streaming products and cloud services but also offer advice and essential support. Note that the bundle numbers (1 to 5) in the following diagram are related to the above data streaming maturity curve:
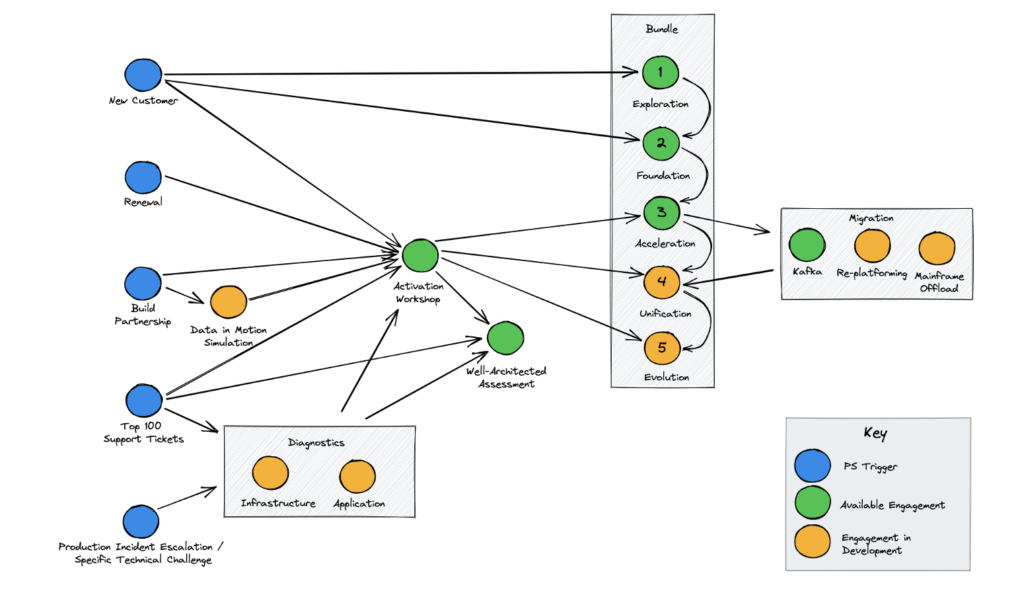
Other vendors have similar strategies to support you. The same is true for the system integrators. Learn together. Bring people from different companies into the room to solve your business problems.
With this background, let’s look at the fantastic data streaming journeys we heard about at past Kafka Summits, Data in Motion events, Confluent blog posts, or other similar public knowledge-sharing alternatives.
Customer Journeys across Industries powered by Apache Kafka
Apache Kafka is the DE FACTO standard for data streaming. However, each data streaming journey looks different. Don’t underestimate how much you can learn from other industries. These companies might have different legal or compliance requirements, but the overall IT challenges are often very similar.
We cover stories from various industries, including banks, retailers, insurers, manufacturers, healthcare organizations, energy providers, and software companies.
The following data streaming journeys are explored in the below sections:
- AO.com: Real-Time Clickstream Analytics
- Nordstrom: Event-driven Analytics Platform
- Migros: End-to-End Supply Chain with IoT
- NordLB: Bank-wide Data Streaming for Core Banking
- Raiffeisen Bank International: Strategic Real-Time Data Integration Platform Across 13 Countries
- Allianz: Legacy Modernization and Cloud-Native Innovation
- Optum (UnitedHealth Group): Self-Service Data Streaming
- Intel: Real-Time Cyber Intelligence at Scale with Kafka and Splunk
- Bayer: Transition from On-Premise to Multi-Cloud
- Tesla: Migration from a Message Broker (RabbitMQ) to Data Streaming (Kafka)
- Siemens: Integration between On-Premise SAP and Salesforce CRM in the Cloud
- 50Hertz: Transition from Proprietary SCADA to Cloud-Native Industrial IoT
There is no specific order besides industries. If you read the stories, you see that all are different, but you can still learn a lot from them, no matter what industry your business is in.
For more information about data streaming in a specific industry, just search my blog for case studies and architectures. Recent blog posts focus on the state of data streaming in manufacturing, in financial services, and so on.
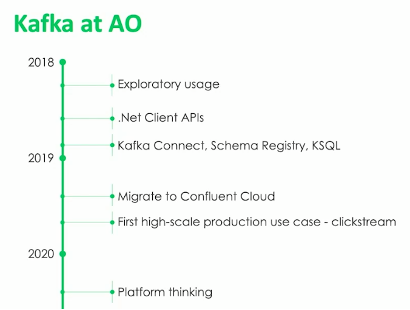
AO.com – Real-Time Clickstream Analytics
AO.com is an electrical retailer. The hyper-personalized online retail experience turns each customer visit into a one-on-one marketing opportunity. The technical implementations correlation of historical customer data with real-time digital signals.
Years ago, Apache Hadoop and Apache Spark referred to this kind of clickstream analytics as the “Hello World” example. AO.com does real-time clickstream analytics powered by data streaming.
AO.com’s journey started with relatively simple data streaming pipelines leveraging the Schema Registry for decoupling and API contracts. Over time, the platform thinking of data streaming added more business value, and operations shifted to the fully-managed Confluent Cloud to focus on implementing business applications, not operations infrastructure.
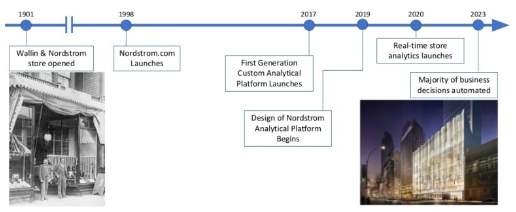
Nordstrom – Event-driven Analytics Platform
Nordstrom is an American luxury department store chain. In the meantime, 50+% of revenue comes from online sales. They built the Nordstrom Analytical Platform (NAP) as the heart of its event-driven architecture. Nordstrom can use a singular event for analytical, functional, operational, and model-building purposes.
As Nordstrom said at Kafka Summit: “If it’s not in NAP, it didn’t happen.”
Nordstrom’s journey started in 1901 with the first stores. The last 25 years brought the retailer into the digital world and online retail. NAP has been a core component since 2017 for real-time analytics. The future is all automated decision-making in real-time.
Migros – End-to-End Supply Chain with IoT
Migros is Switzerland’s largest retail company, the largest supermarket chain, and the largest employer. They leverage data streaming with Confluent to distribute master data across many systems.
Migros’ supply chain is optimized with a single data streaming pipeline (including replaying entire days of events). For instance, real-time transportation information is visualized with MQTT and Kafka. Afterward, more advanced business logic was implemented, like forecasting the truck arrival time and planning, respectively, rescheduling truck tours.
The data streaming journey started with a single Kafka cluster. And grew to various independent Kafka clusters and a strategic Kafka-powered enterprise integration platform.
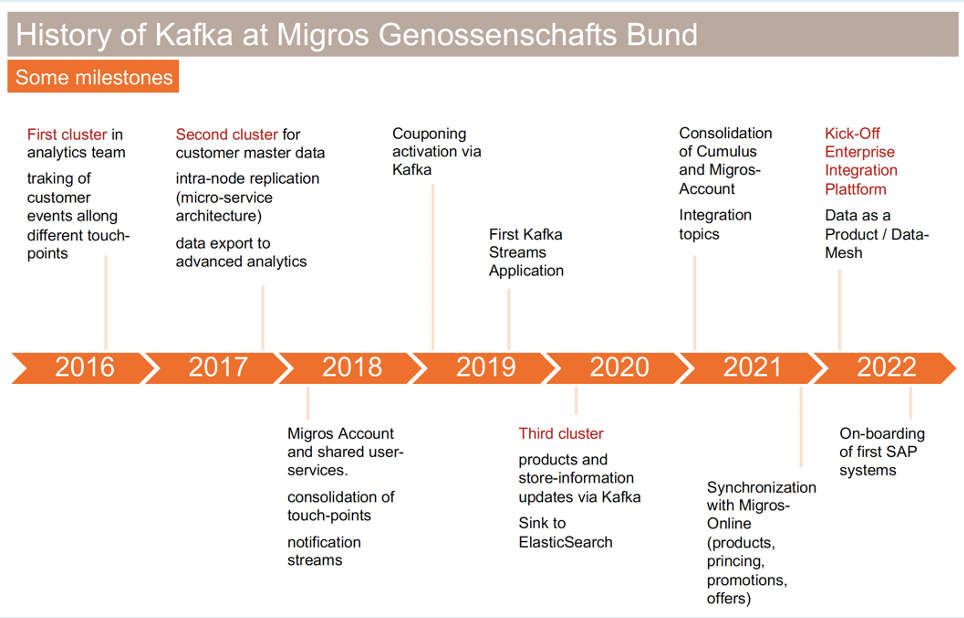
NordLB – Bank-wide Data Streaming for Core Banking
Norddeutsche Landesbank (NordLB) is one of the largest commercial banks in Germany. They implemented an enterprise-wide transformation. The new Confluent-powered core banking platform enables event-based and truly decoupled stream processing. Use cases include improved real-time analytics, fraud detection, and customer retention.
Unfortunately, NordLB’s slide is only available in German. But I guess you can still follow their data streaming journey moving over the years from on-premise big data batch processing with Hadoop to real-time data streaming and analytics in the cloud with Kafka and Confluent:
Raiffeisen Bank International – Strategic Real-Time Data Integration Platform across 13 Countries
Raiffeisen Bank International (RBI) operates as a corporate and investment bank in Austria and as a universal bank in Central and Eastern Europe (CEE).
RBI’s bank transformation across 13 countries includes various components:
- Bank-wide transformation program
- Realtime Integration Center of Excellence (“RICE“)
- Central platform and reference architecture for self-service re-use
- Event-driven integration platform (fully-managed cloud and on-premise)
- Group-wide API contracts (=schemas) and data governance
While I don’t have a nice diagram of RBI’s data streaming journey over the past few years, I can show you one of the most impressive migration stories. The context is horrible had to move from Ukraine data centers to the public cloud after the Russian invasion started in early 2022. The journey was super impressive from the IT perspective, as the migration happened without downtime or data loss.
“We did this migration in three months, because we didn’t have a choice.”

Allianz – Legacy Modernization and Cloud-Native Innovation
Allianz is a European multinational financial services company headquartered in Munich, Germany. Its core businesses are insurance and asset management. The company is one of the largest insurers and financial services groups.
A large organization like Allianz does not have just one enterprise architecture. This section has two independent stories of two separate Allianz business units.
One team of Allianz has built a so-called Core Insurance Service Layer (CISL). The Kafka-powered enterprise architecture is flexible and evolutionary. Why? Because it needs to integrate with hundreds of old and new applications. Some are running on the mainframe or use a batch file transfer. Others are cloud-native, running in containers or as a SaaS application in the public cloud.
Data streaming ensures the decoupling of applications via events and the reliable integration of different backend applications, APIs and communication paradigms. Legacy and new applications connect but also allow running in parallel (old V1 and new V2) before migrating away and shutting down from the legacy component.
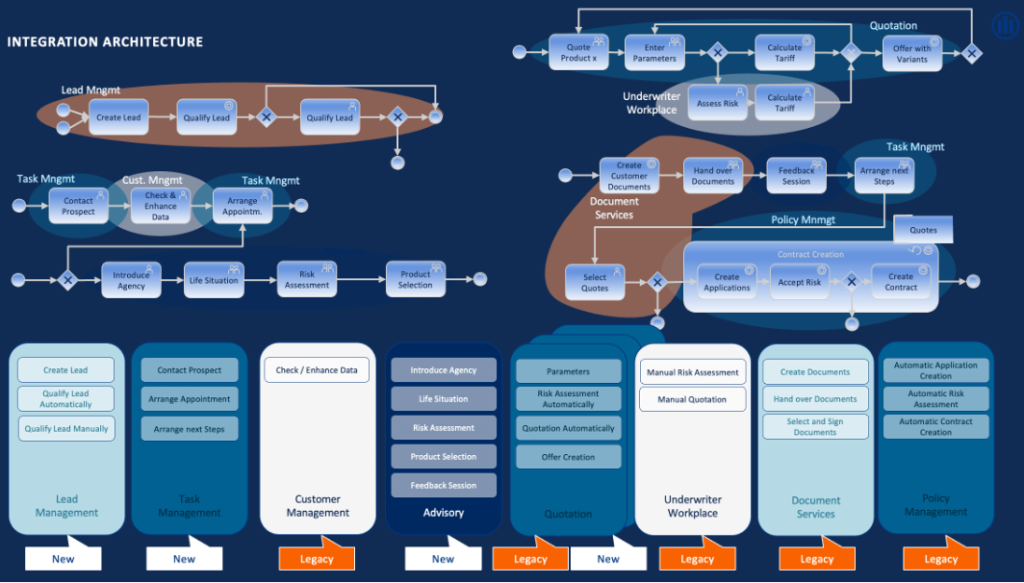
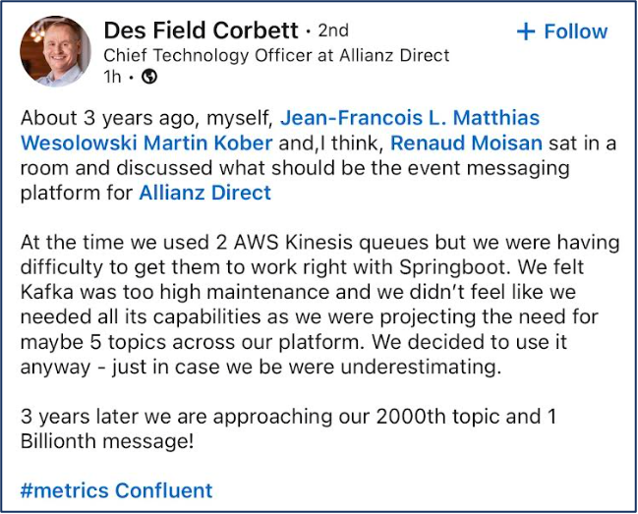
Allianz Direct is a separate Kafka deployment. This business unit started with a greenfield approach to build insurance as a service in the public cloud. The cloud-native platform is elastic, scalable, and open. Hence, one platform can be used across countries with different legal, compliance, and data governance requirements.
This data streaming journey is best described by looking at a quote from Allianz Direct’s CTO:
Optum – Self-Service Data Streaming
Optum is an American pharmacy benefit manager and healthcare provider
(UnitedHealth Group subsidiary). Optum started with a single data source connecting to Kafka. Today, they provide Kafka as a Service within the UnitedHealth Group. The service is centrally managed and used by over 200 internal application teams.
The benefits of this data streaming approach are the following characteristics: repeatable, scalable, and a cost-efficient way to standardize data. Optum leverages data streaming for many use cases, from mainframe via change data capture (CDC) to modern data processing and analytics tools.
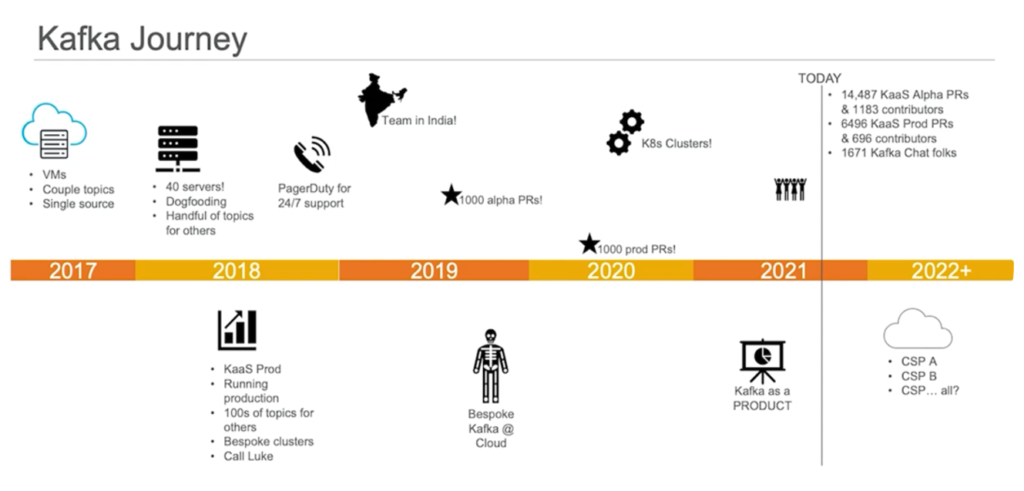
Intel – Real-Time Cyber Intelligence at Scale with Kafka and Splunk
Intel Corporation (commonly known as Intel) is an American multinational corporation and technology company headquartered in Santa Clara, California. It is one of the world’s largest semiconductor chip manufacturers by revenue.
Intel’s Cyber Intelligence Platform leverages the entire Kafka-native ecosystem, including Kafka Connect, Kafka Streams, Multi-Region Clusters (MRC), and more…
Their Kafka maturity curve shows how Intel started with a few data pipelines, for instance, getting data from various sources into Splunk for situational awareness and threat intelligence use cases. Later, Intel added Kafka-native stream processing for streaming ETL (to pre-process, filter, and aggregate data) instead of ingesting raw data (with high $$$ bills) and for advanced analytics by combining streaming analytics with Machine Learning.
Brent Conran (Vice President and Chief Information Security Officer, Intel) described the benefits of data streaming:
“Kafka enables us to deploy more advanced techniques in-stream, such as machine learning models that analyze data and produce new insights. This helps us reduce the meantime to detect and respond.”
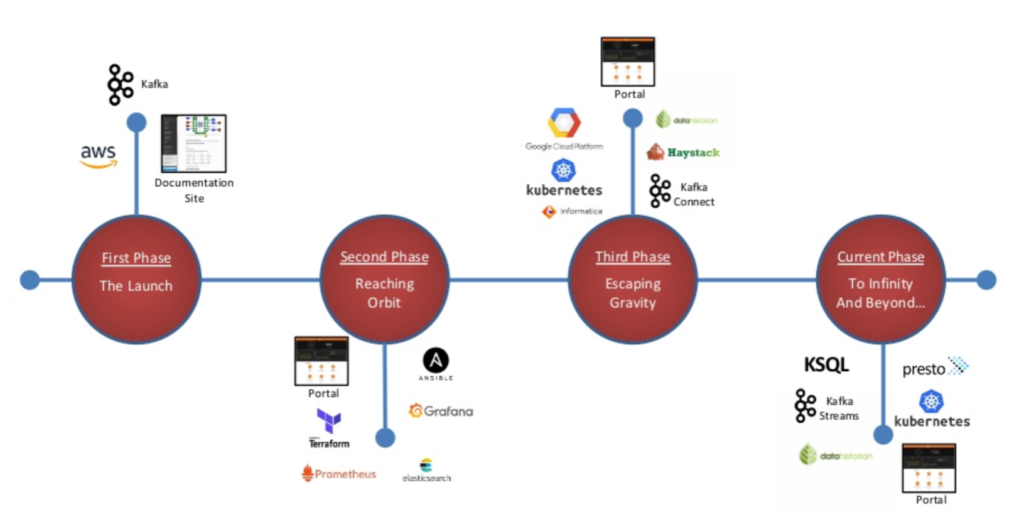
Bayer AG – Transition from On-Premise to Multi-Cloud
Bayer AG is a German multinational pharmaceutical and biotechnology company and one of the largest pharmaceutical companies in the world. They adopted a cloud-first strategy and started a multi-year transition to the cloud.
While Bayer AG has various data streaming projects powered by Kafka, my favorite is the success story of their Monsanto acquisition. The Kafka-based cross-data center DataHub was created to facilitate migration and to drive a shift to real-time stream processing.
Instead of using many words, let’s look at Bayer’s impressive data streaming journey from on-premise to multi-cloud, connecting various cloud-native Kafka and non-Kafka technologies over the years.
Tesla – Migration from a Message Broker (RabbitMQ) to Data Streaming (Kafka)
Tesla is a carmaker, utility company, insurance provider, and more. The company processes trillions of messages per day for IoT use cases.
Tesla’s data streaming journey is fascinating because it focuses on migrating from a message broker to stream processing. The initial reasons for Kafka were the scalability and reliability of processing high volumes of IoT sensor data.
But as you can see, more use cases were added quickly, such as Kafka Connect for data integration.
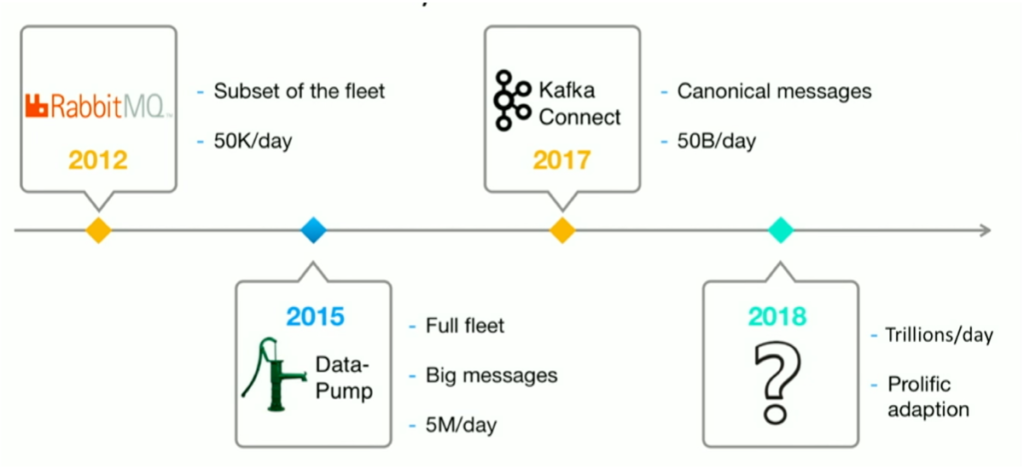
Tesla’s blog post details its advanced stream processing use cases. I often call streaming analytics the “secret sauce” (as data is only valuable if you correlate it in real-time instead of just ingesting it into a batch data warehouse or data lake).
Siemens – Integration between On-Premise SAP and Salesforce CRM in the Cloud
Siemens is a German multinational conglomerate corporation and the largest industrial manufacturing company in Europe.
One strategic data-streaming use case allowed Siemens to move “from batch to faster“ data processing. For instance, Siemens connected its SAP PMD to Kafka on-premise. The SAP infrastructure is very complex, with 80% ”customized ERP”. They improved the business processes and integration workflow from daily or weekly batches to real-time communication by integrating SAP’s proprietary IDoc messages within the event streaming platform.
Siemens later migrated from self-managed on-premise Kafka to Confluent Cloud via Confluent Replicator. Integrating Salesforce CRM via Kafka Connect was the first step of Siemens’ cloud strategy. As usual, more and more projects and applications join the data streaming journey as it is super easy to tap into the event stream and connect it to your favorite tools, APIs, and SaaS products.
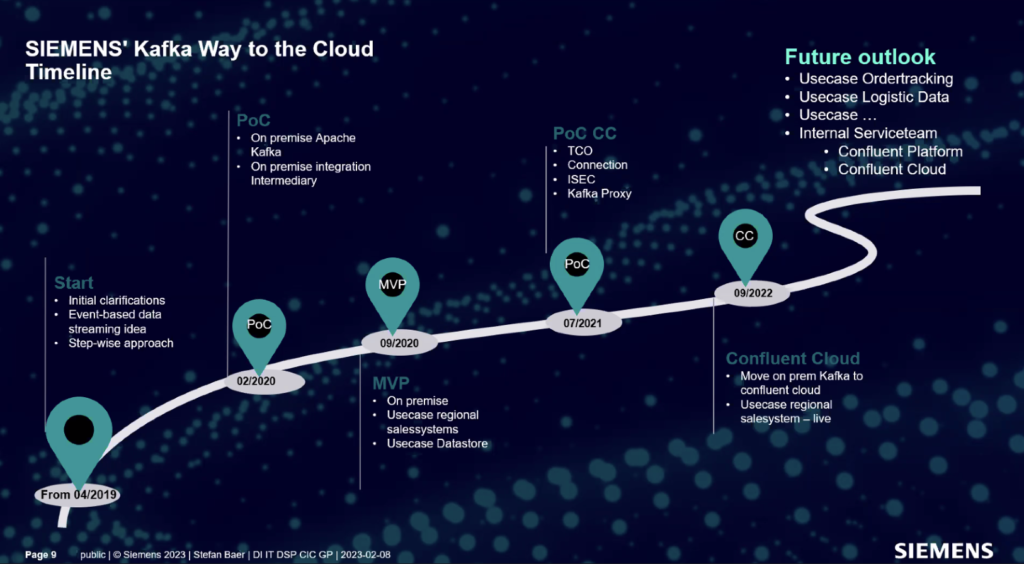
A few important notes on this migration:
- Confluent Cloud was chosen because it enables focusing on business logic and handing over complex operations to the expert, including mission-critical SLAs and support.
- Migration from one Kafka cluster to another (in this case, from open source to Confluent Cloud) is possible with zero downtime and no data loss. Confluent Replicator and Cluster Linking, in conjunction with the expertise and skills of consultants, make such a migration simple and safe.
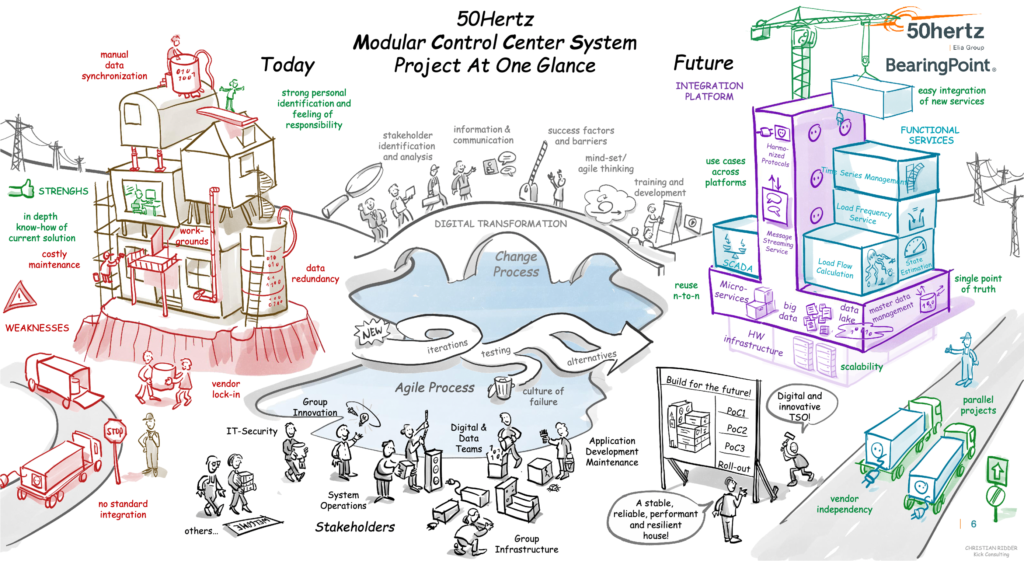
50Hertz – Transition from Proprietary SCADA to Cloud-Native Industrial IoT
50hertz is a transmission system operator for electricity in Germany. They built a cloud-native 24/7 SCADA system with Confluent. The solution is developed and tested in the public cloud but deployed in safety-critical air-gapped edge environments. A unidirectional hardware gateway helps replicate data from the edge into the cloud safely and securely.
This data streaming journey is one of my favorites as it combines so many challenges well known in any OT/IT environment across industries like manufacturing, energy and utilities, automotive, healthcare, etc.:
- From monolithic and proprietary systems to open architectures and APIs
- From batch with mainframe, files, and old Windows servers to real-time data processing and analytics
- From on-premise data centers (and air-gapped production facilities) to a hybrid edge and cloud strategy, often with a cloud-first focus for new use cases.
The following graphic is fantastic. It shows the data streaming journey from left to right, including the bridge in the middle (as such a project is not a big bang but usually takes years, at a minimum):
Technical Evolution during the Data Streaming Journey
The different data streaming journeys showed you a few things: It is not a big bang. Old and new technology and processes need to work together. Only technology AND expertise drive successful projects.
Therefore, I want to share a few more resources to think about this from a technical perspective:
- Apache Kafka is NOT a message broker
- ETL tools differ from data streaming
- APIs and data streaming are friends, not enemies
- Data warehouse, data lake, and data streaming are complementary
- Reverse ETL is NOT a great architecture to start with
- Data Mesh is not a technology, but the heart of the enterprise architecture should beat in real-time
The data streaming journey never ends. Apache Kafka and Apache Flink increasingly join forces to build innovative real-time stream processing applications. We are just at the beginning.
What does your data streaming journey look like? Where are you right now, and what are your plans for the next few years? Let’s connect on LinkedIn and discuss it! Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter.
