
For years, data architects debated the merits of Lambda vs. Kappa architecture. While Lambda tried to offer the best of both batch and real-time worlds, the industry has spoken: Kappa has become the default architecture for modern data systems.
Now, the rise of Agentic AI—autonomous, event-driven systems powered by models that think and act—puts even more pressure on data infrastructure. These agents rely on low-latency, consistent, and contextual data to make decisions and operate in real time. Kappa architecture is uniquely positioned to deliver on these needs.
With the momentum of open table formats like Apache Iceberg and Delta Lake, and the growing adoption of Shift Left architecture patterns, Kappa is no longer a niche idea. It’s a scalable, resilient foundation for real-time pipelines that serve analytics, automation, and AI—from batch to stream, from people to agents.
Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases, including various real-world examples AI-related topics like fraud detection and generative AI for customer service.
Recap: The Shift from Lambda to Kappa Architecture
In my earlier blog post “Kappa Architecture is Mainstream – Replacing Lambda”, I explained the fundamental problems of Lambda:
- Two separate pipelines for batch and stream
- Increased complexity
- Code duplication and higher operational costs
- Inconsistent results across systems

Kappa, on the other hand, offers a single real-time pipeline for all workloads—whether transactional or analytical. Event streaming platforms like Apache Kafka serve as the central nervous system, enabling continuous, real-time processing with the ability to replay and reprocess data as needed.

Today, the Kappa model is not just theory. It’s already deployed by global leaders like Uber, Shopify, Twitter, and Disney- to name a few public success stories. In fact, if you’re designing a new modern architecture today, chances are it’s a Kappa architecture by default.
Open Table Format: Unified Storage Layer with Apache Iceberg / Delta Lake
The Open Table Format movement has revolutionized how data is stored, accessed, and shared across analytics and streaming platforms. Formats like Apache Iceberg and Delta Lake provide schema evolution, ACID transactions, time travel, and other critical capabilities for reliable data operations in the cloud.
What’s more, every major cloud and data platform supports open table formats around its storage and catalog services:
- AWS (Glue, Athena, Redshift, S3)
- Azure (Synapse, ADLS)
- Google Cloud (BigQuery, GCS)
- Databricks (Delta Lake)
- Snowflake (Polaris)
- Confluent (Tableflow)
- And many others
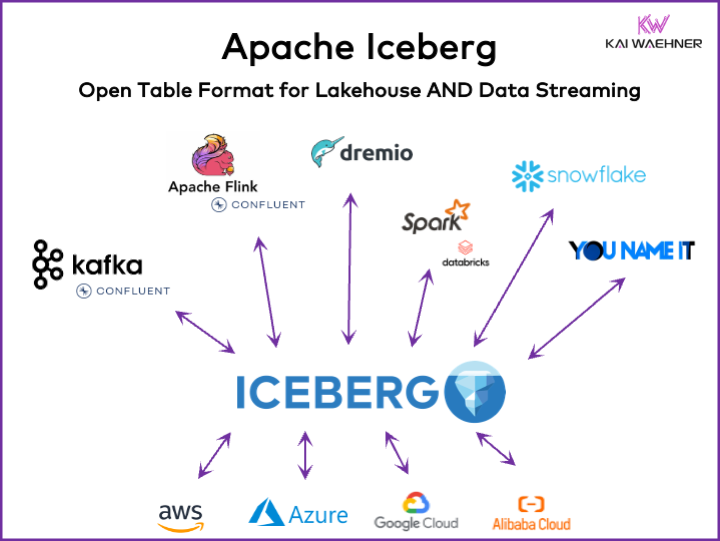
The value? Store data once. Own your object store. Access with any engine. Whether you use Flink for real-time stream processing, Snowflake for analytics, or Spark for ETL batch jobs, everything reads from the same storage layer.
The standardization with an open table format was the missing piece that made Kappa architectures much easier to implement—serving both real-time and batch consumers from one consistent dataset.
Shift Left Architecture: Moving Data Responsibility Closer to the Source
The Shift Left trend in data architecture is about moving data quality, governance, and observability earlier in the pipeline—closer to the developers and domain teams who understand the data best.
This aligns perfectly with data streaming:
- Apache Kafka and Flink allow you to process and validate data at ingestion time
- Kafka Connect integrates operational systems (like Oracle, SAP, Salesforce, MongoDB)
- Streaming jobs apply transformations, joins, and aggregations in-flight
- The output flows directly to both analytical sinks (Iceberg, Delta Lake) and operational systems (NoSQL, ERP, CRM)
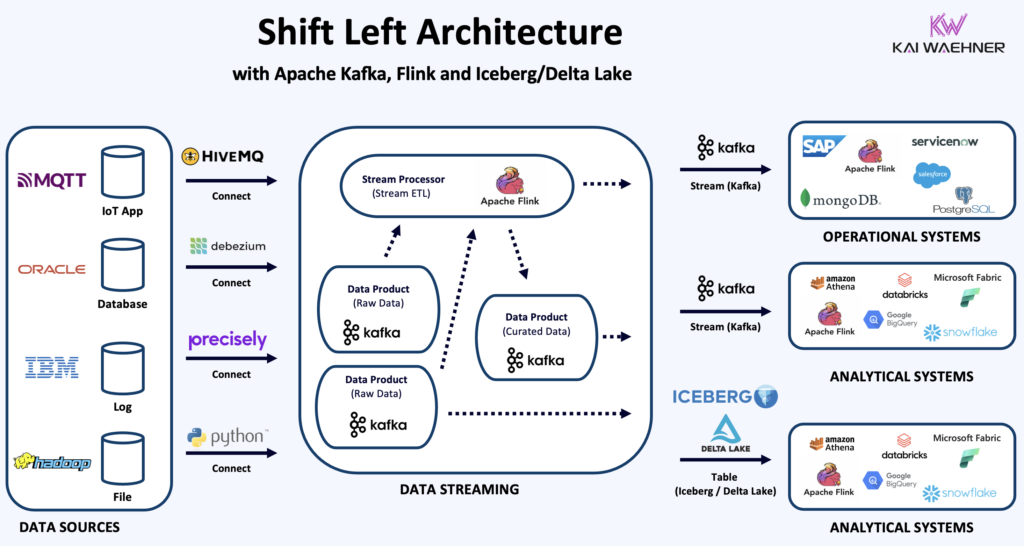
This model enables real-time data products that unify operational and analytical views, allowing faster time-to-market, better reusability, and more consistent data across the business.
With this approach, the Reverse ETL anti-pattern becomes obsolete. Instead of pushing batch updates back into operational tools after the fact, you integrate them properly from the start—in real time, with guaranteed delivery, ordering, and schema validation.
Kappa By Default – How Real-Time Architectures Are Evolving
What emerges from combining an Open Table Format like Apache Iceberg or Delta Lake with an event-driven architecture leveraging Shift Left principles and real-time data streaming?
You don’t have to declare you’re “doing Kappa.”
You’re already doing it—whether you realize it or not.
The Kappa architecture is the implicit foundation of this modern stack:
- One real-time event streaming pipeline
- Universal data products for transactional and analytical consumers
- Native support for schema evolution and time travel
- Built-in data governance and lineage
- Real-time observability and alerting
- No code duplication, no dual batch/streaming logic
Confluent’s Tableflow architecture shows how operational systems like Kafka and Flink can be integrated with analytical platforms such as Databricks and Snowflake leveraging the Open Table Format with Iceberg or Delta Lake.
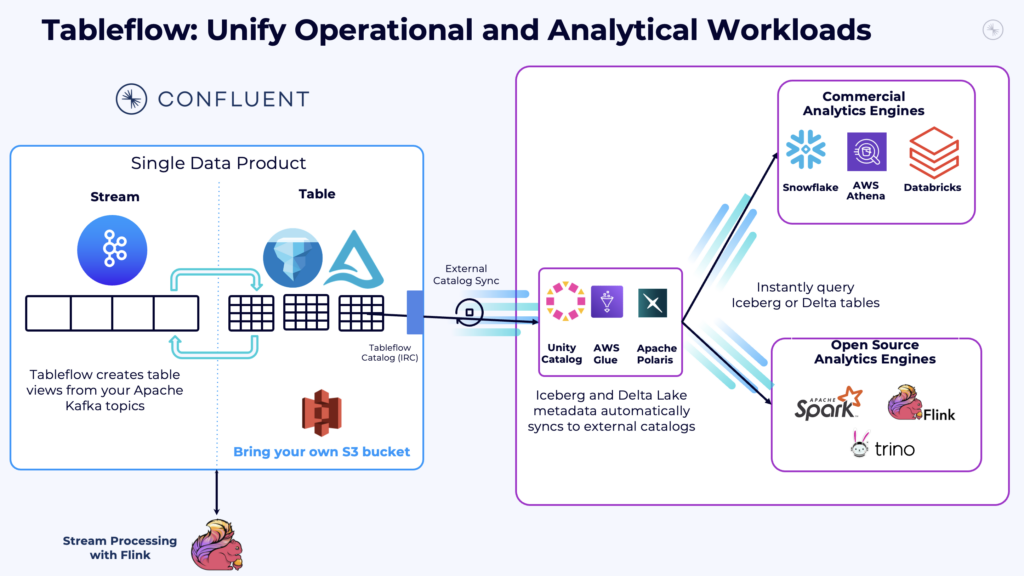
The end result: a scalable, cloud-native, resilient architecture that handles all workloads through a single pipeline and data model.
Kappa Architecture vs. Streaming Databases and Analytics Engines: Complementary, Not Competitive
Kappa architecture is a powerful pattern for real-time data pipelines, especially with Apache Kafka and Flink. But there is growing interest in new types of use cases supporting point-in-time queries on data streams. These scenarios treat the stream like a live, continuously updating database table. This form of real-time analytics goes beyond standard stream processing. It allows direct, ad-hoc queries on live data without needing to materialize intermediate results.
I’ve written about Kappa as a replacement for the complexity of Lambda, especially for event-driven architectures and data integration. But when it comes to interactive analytics, or queryable intermediate results, the limitations of a log-based approach become more apparent.
This is where modern streaming databases and analytical OLAP engines come into play. Examples include RisingWave, Materialize, Timeplus, Ververica Fluss, Trino, Apache Pino, et al. These systems are built to deliver:
- Sub-second query latency
- Ad-hoc access to real-time data streams
- Columnar storage optimized for analytics
- Native changelogs for consistent updates and historical insight
Unlike Kafka—which is built for reliable, ordered messaging—these newer engines act more like analytical layers on top of streaming data. They let you treat a stream like a table and run ad-hoc queries against it. This makes it possible to explore and analyze live data directly, while also supporting batch-style access in the same system.
Extending Data Streaming with Real-Time Query Engines
To be clear: streaming databases and analytical OLAP engines are NOT a replacement for Kappa architecture, but a complement. Kappa provides the architectural foundation for real-time pipelines. Streaming databases improve those pipelines by extending the analytic capabilities without introducing complex batch workflows or data duplication.
As always, it’s important to meet enterprises where they are. Most data platforms aren’t greenfield, and evolving from traditional architectures takes time. But for organizations looking to combine event streaming with real-time analytics, pairing Kappa with a streaming-native engine can unlock significant performance and agility gains.
That said, even in greenfield environments, a streaming database alone isn’t enough. Unifying streaming and lakehouse into one platform is hard—if not unrealistic. An event-driven architecture leveraging a data streaming platform as the backbone is still needed to make Kappa work across teams with true decoupling, flexibility and the right tools, SLAs and performance for each team.
AI Adoption: Why Kappa Is Critical for GenAI and Agentic Systems
Enterprises embracing AI and GenAI need more than dashboards. They need high-quality, low-latency, and trustworthy data pipelines—and Kappa is the only architecture that delivers this end-to-end.
Here’s how Kappa supports AI use cases:
- Consistent data -> data sourced from batches and streams have a common access pattern
- Good data quality → avoids hallucinations and poor predictions
- Real-time inference → use LLMs and ML models directly in streaming apps
- Low latency SLAs → critical for transactional agents and recommendation engines
- Bidirectional flows → stream context to the model and actions back to the business system
- Replayability → retrain models with real-world event history at scale
- AI application testing -> Evaluate business logic while making changes to the prompts, models, and tools
Without a Kappa-style backbone, AI pipelines fall apart. GenAI and Agentic AI needs both fresh, relevant input and the ability to take action—in real time.
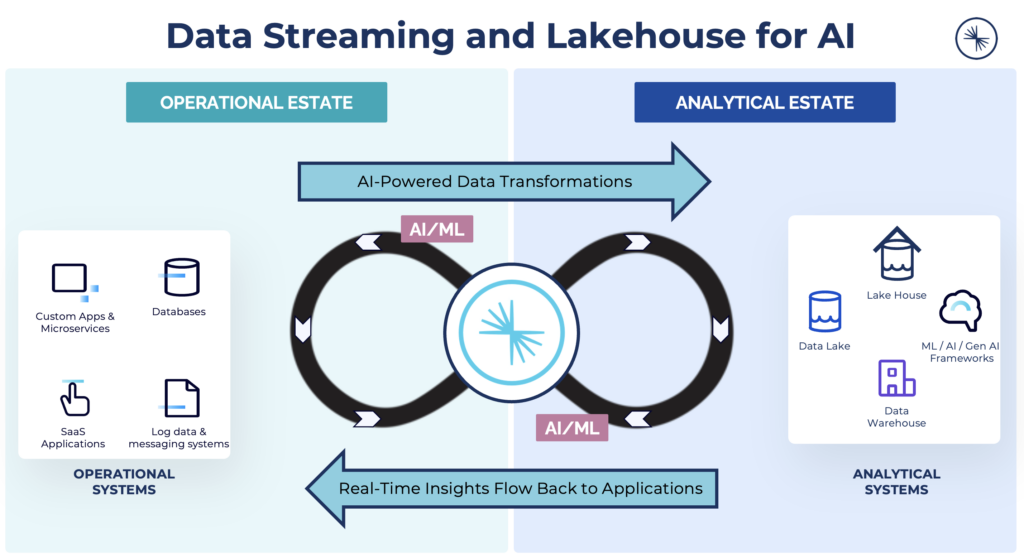
Memory and Real-Time Perception: Data Requirements for Intelligent Agents
Agentic AI is about building intelligent systems that go beyond prompting models—they coordinate actions, make decisions, and operate autonomously.
Building Agentic AI systems requires more than just powerful models—it demands a real-time, scalable infrastructure to support autonomous decision-making, context sharing, and coordination across domains. This is where Apache Kafka and Apache Flink come into play.
Together, they form the foundation for a modern agentic architecture: Kafka provides the persistent, event-driven backbone for communication, while Flink enables real-time processing and state management. The combination allows AI agents to interact, reason, and act autonomously in complex, distributed environments—with consistency, observability, and fault tolerance built in.
This architecture supports the two critical data needs of intelligent agents: access to historical context and awareness of current events. Just like humans, agents need both memory (from databases) and real-time perception (from streaming)—and it’s far more effective to bring historical data to the stream than to push live signals into a static backend.
How Data Streaming with Apache Kafka and Flink Enables Agentic AI with A2A and MCP Protocol
Recent developments such as the Agent2Agent (A2A) Protocol and Model Communication Protocol (MCP) formalize how agents interact in distributed systems. The event-driven architecture powered by data streaming plays a central role in enabling these interactions leveraging the MCP and A2A protocols:
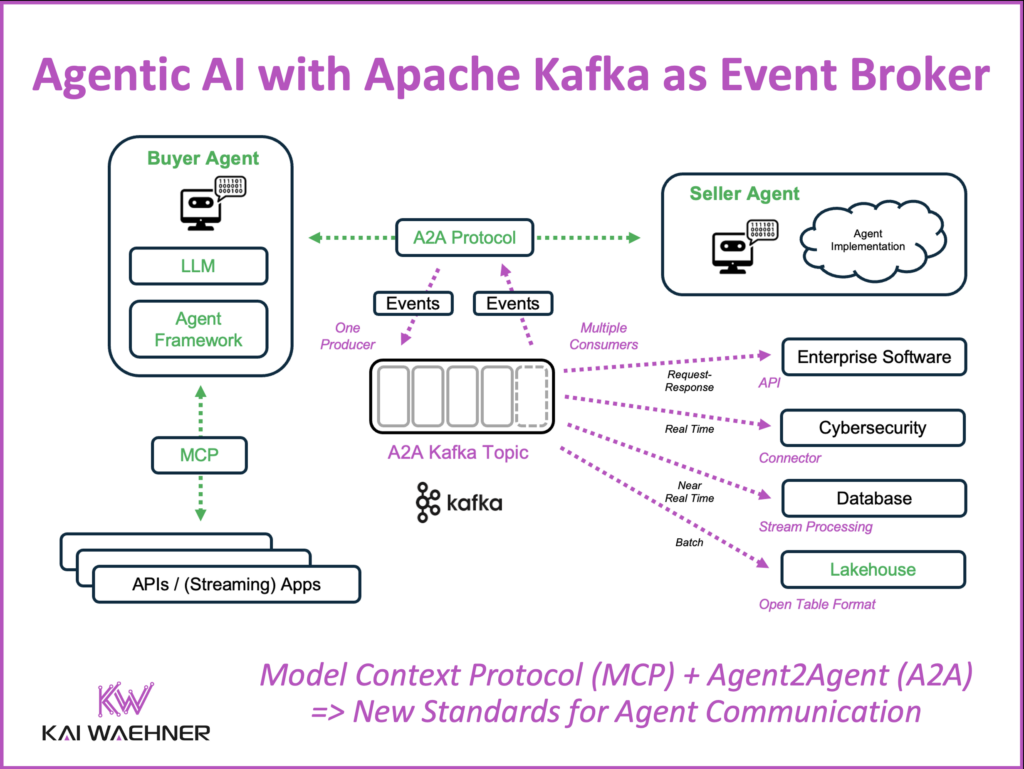
Data Streaming with Kafka and Flink provides the core infrastructure for enabling real-time, autonomous collaboration between AI agents across systems, domains, and models:
- A2A: Agent2Agent Protocol: Agents communicate asynchronously via Kafka topics. Kafka acts as a persistent, ordered message bus, allowing autonomous agents to exchange goals, state, and actions across domains in real time.
- MCP: Model Communication Protocol: MCP standardizes the communication between AI agents and tools. Kafka provides the infrastructure for reliable input/output exchange between models (e.g., LLMs, embeddings, recommender systems) and external systems (e.g., search engines, vector stores, databases).
- Event Choreography, Not Orchestration: Instead of one central controller making all decisions (orchestration), Kafka enables decentralized, event-driven workflows where each agent reacts to events independently but consistently. This aligns with Data Mesh principles and is ideal for scaling across teams.
- Replay, Time Travel, and State Handling: With Tiered Storage, Kafka allows replaying entire conversations or decision trees for debugging, auditing, or retraining. Flink manages stateful workflows, keeping track of long-running sessions between agents.
- Cross-Domain Agent Communication: AI agents don’t live in isolation. They interact with operational systems like SAP, Salesforce, and MongoDB, as well as analytical platforms like Iceberg and Snowflake. Kafka Connect bridges all these systems—a critical enabler for universal agent collaboration.
Apache Kafka serves as the central backbone of Agentic AI architectures, enabling systems that are scalable, resilient, low-latency, observable, replayable, and secure.
When combined with Apache Flink for stateful stream processing, it allows autonomous agents to react in real time, manage context, and maintain long-running, reliable decision workflows across distributed environments.
The Kappa architecture provides the implicit foundation for these capabilities—combining event streaming, operational and analytical integration, and AI orchestration into a single, unified platform.
Unifying Data Streaming and Agentic AI with Kappa Architecture
If you’re building real-time data products, integrating operational and analytical systems, and deploying AI across your business, then Kappa architecture is not a choice—it’s a requirement.
Thanks to open table formats like Apache Iceberg and Delta Lake, and the Shift Left movement in data ownership and quality, Kappa has matured into a complete, unified data platform for both batch and stream, operations and analytics, people and machines.
Kappa architecture provides the real-time foundation and contextual information Agentic AI systems need to perceive, reason, and act autonomously across distributed environments.
It’s time to move past the old Lambda model.
It’s time to stop duplicating pipelines, delaying insights, and bloating operations.
The Kappa architecture is here. And it works.
Related Reading:
- Kappa Architecture is Mainstream – Replacing Lambda
- Apache Iceberg: The Open Table Format for Lakehouse and Data Streaming
- Shift Left: From Batch to Real-Time Data Products with Data Streaming
- Real-Time Model Inference with Apache Kafka and Flink for Predictive AI and GenAI
- How Apache Kafka and Flink Power Event-Driven Agentic AI in Real Time
- Agentic AI with the Agent2Agent Protocol (A2A) and MCP using Apache Kafka as Event Broker
Join the data streaming community and stay informed about new blog posts by subscribing to my newsletter and follow me on LinkedIn or X (former Twitter) to stay in touch. And make sure to download my free book about data streaming use cases, including various real-world examples AI-related topics like fraud detection and generative AI for customer service.
