
Apache Kafka became the central nervous system of many applications in various areas related to the automotive industry (and it’s not only connected cars). This blog post explores various real-world deployments across several fields, including connected vehicles, smart manufacturing, and innovative mobility services. Examples include car makers such as Audi, BMW, Porsche, and Tesla, plus a few mobility services such as Uber, Lyft, and Here Technologies.
I wrote about use cases for event streaming with Apache Kafka in the automotive industry shortly before the pandemic when I visited a few customers in Detroit. I recommend reading that post to learn about the general shift and innovation in the automotive industry. That post explores various use cases for data in motion, such as:
- Connected vehicle infrastructures for fleet management, emergency systems, and smart driving
- Smart manufacturing for improved supply chain management and analytics on the shop floor level
- Context-specific customer interactions including great customer experiences, aftersales, and data monetization
Real-World Deployments of Kafka in the Automotive Industry
This blog post explores various real-world success stories of Apache Kafka and its ecosystem in the automotive industry. Learn how carmakers, suppliers, mobility services built infrastructure to integrate and process data in motion across various fields and business units.
BMW – Smart Shop Floor and Industry 4.0
Felix Böhm, responsible for BMW Plant Digitalization and Cloud Transformation, spoke with Confluent CEO Jay Kreps at the Kafka Summit EU 2021 about their journey towards data in motion in manufacturing. The following are my notes. For more details, feel free to watch the complete conversation on Youtube.
Decoupled IoT Data and Manufacturing
BMW operates mission-critical workloads at the edge (i.e., in the factories) and in the public cloud. Kafka provides decoupling, transparency, and innovation. Confluent adds stability [via products and expertise]. The latter is key for success in manufacturing. Each minute of downtime costs a fortune. Read my related article “Apache Kafka as Data Historian – an IIoT / Industry 4.0 Real-Time Data Lake” to understand how Kafka improves the Overall Equipment Effectiveness (OEE) in manufacturing.
Logistics and supply chain in global plants
The discussed use case covered optimized supply chain management in real-time.
The solution provides information about the right stock in place, both physically and in ERP systems like SAP. “Just in time, just in sequence” is a key concept for many critical applications.
Things BMW couldn’t do before
- Get IoT data without interfering with others, and get it to the right place
- Collect once, process, and consume several times (by different consumers at different times with different communication paradigms like real-time, batch, request-response)
- Enable scalable real-time processing and improve time-to-market with new applications
The true decoupling between different interfaces is a unique advantage of Kafka vs. other messaging platforms such as IBM MQ, Rabbit MQ, or MQTT brokers. I also explored this in detail in my article about Domain-driven Design (DDD) with Kafka
BMW – Machine Learning and Natural Language Processing
Unrelated to the above, another exciting project: BMW has built an “Industry-ready NLP Service Framework Based on Kafka”. The implementation leverage the Kafka ecosystem as an orchestration and processing layer for different NLP (= natural language processing) services:
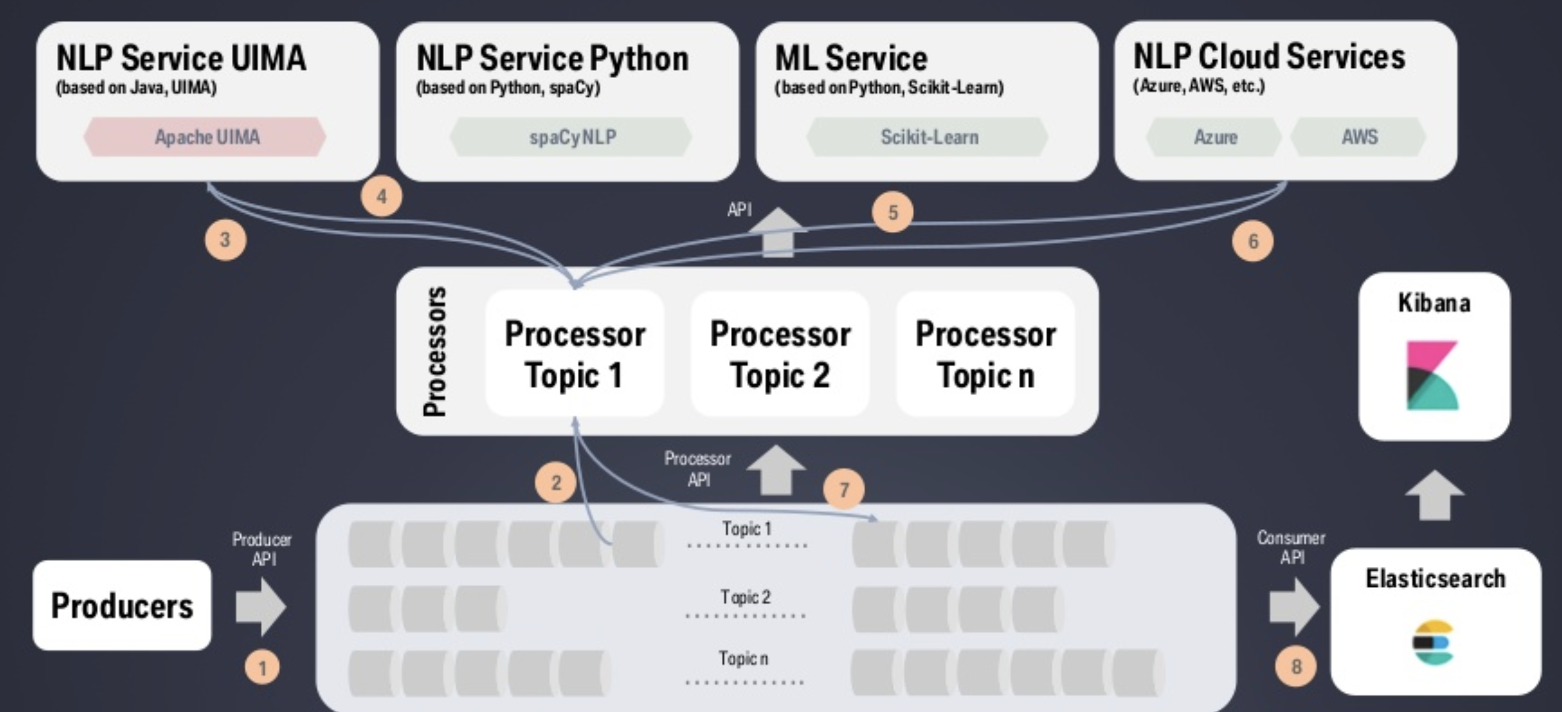
Kafka Streams applications do the preprocessing to consolidate and enrich the incoming text and speech data sets. Various machine learning / deep learning platforms and technologies consume events for language processing tasks such as speech-to-text translation.
That’s very similar to what I see at other enterprises: There is no single Machine Learning silver bullet. Different use cases – even in one category like NLP – require different technologies. The problem space does not just include model training but also model deployment and monitoring. Python is not the right choice for every data science problem. I explored how to solve the impedance mismatch between the data scientists and production engineers in the post “Apache Kafka + ksqlDB + TensorFlow for Data Scientists via Python + Jupyter Notebook“.
BMW leverage the NLP platform for various use cases, including digital contract intelligence, workplace assistance, machine translation, and service desk automation:

Check out the details in BMW’s Kafka Summit talk about their use cases for Kafka and Deep Learning / NLP.
Audi – Connected Vehicles
Audi has built a connected car infrastructure with Apache Kafka. Their Kafka Summit keynote explored the use cases and architecture:
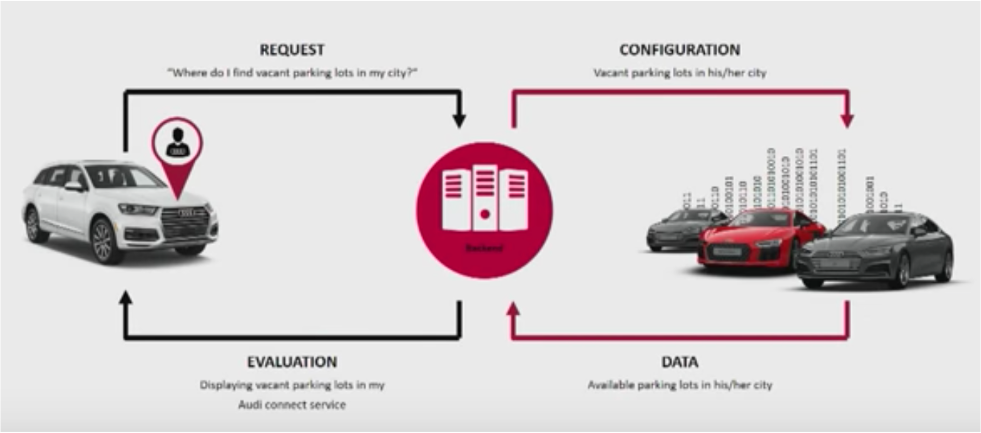
Use cases include real-time data analysis, swarm intelligence, collaboration with partners, and predictive AI.
Depending on how you define the term and buzzword “Digital Twin”, this is a perfect example: All sensor data from the connected cars are processed in real-time and stored for historical analysis and reporting. Read more about “Kafka for Digital Twin Architectures” here.
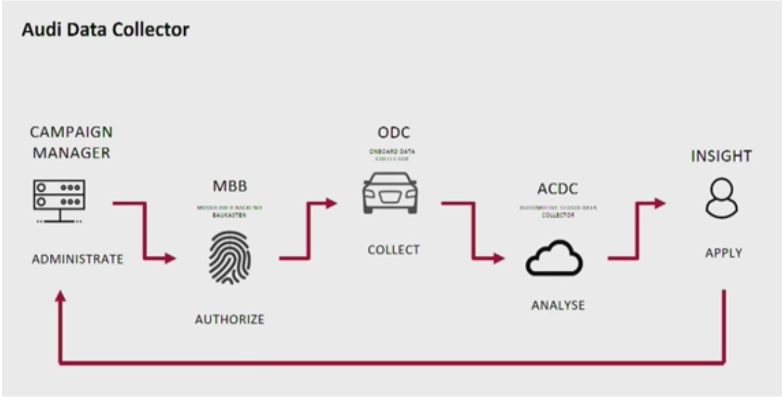
The architecture with the Kafka clusters is called “Audi Data Collector”:
Tesla – Connected Everything – Industrial IoT, Cars, Energy
Tesla is not just a car maker. Telsa is a tech company writing a lot of innovative and cutting-edge software. They provide an energy infrastructure for cars with their Telsa Superchargers, solar energy production at their Gigafactories, and much more. Processing and analyzing the data from their cars, smart grids, and factories and integrating with the rest of the IT backend services in real-time is a key piece of their success.
Tesla has built a Kafka-based data platform infrastructure “to support millions of devices and trillions of data points per day”. Tesla showed an interesting history and evolution of their Kafka usage at a Kafka Summit in 2019:
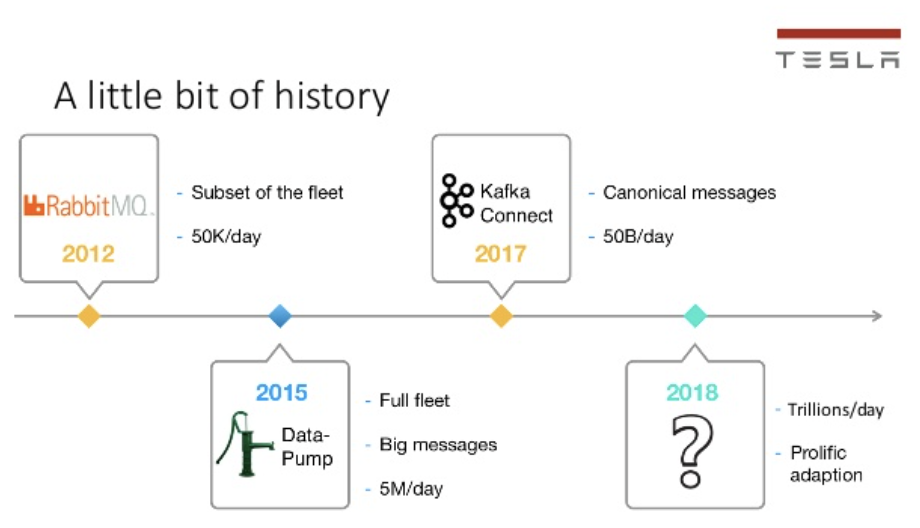
Why Kafka at Telsa?
Telsa chose Kafka to solve the following design requirements (quote from their Kafka Summit presentation):
- “Just works”
- Flexible batching
- One-stream, one-app
- Scale with multiple degrees of freedom
Once again, another proof that Kafka is battle-tested, scalable, and reliable for massive IoT workloads across verticals and use cases.
Porsche – Customer 360 and Personalized Experience
‘My Porsche’ is the innovative and modern digital omnichannel platform from Porsche for keeping a great relationship with their customers. Porsche can describe it better than me:
“The way automotive customers interact with brands has changed, accompanied by a major transformation of customer needs and requirements. Today’s brand experience expands beyond the car and other offline touchpoints to include various digital touchpoints. Automotive customers expect a seamless brand experience across all channels — both offline and online.”
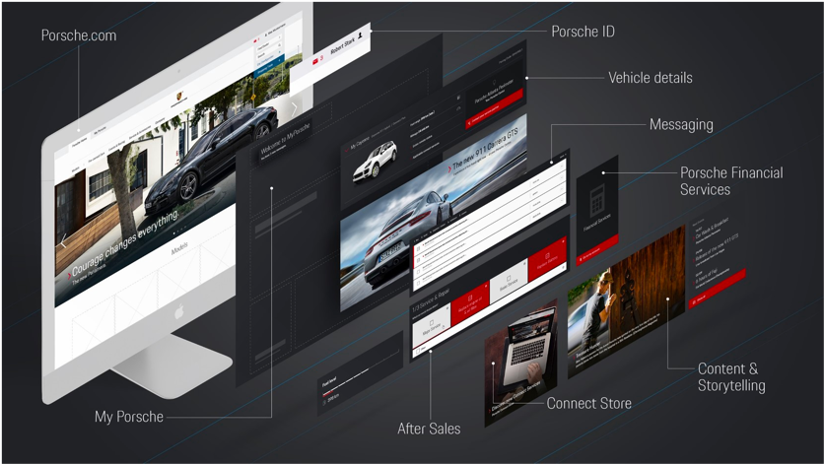
The ‘Porsche Dev‘ group from Porsche published a few great posts about their architecture. Here is a good overview:
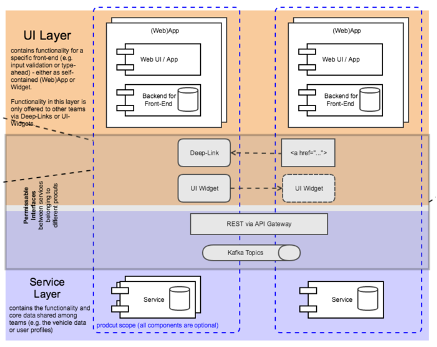
Kafka provides real decoupling between applications. Hence, Kafka became the defacto standard for microservices and Domain-driven Design (DDD) in many companies. It allows building independent and loosely coupled but scalable, highly available, and reliable applications.
That’s exactly what Porsche describes for their usage of Apache Kafka through its supply chain:
“The recent rise of data streaming has opened new possibilities for real-time analytics. At Porsche, data streaming technologies are increasingly applied across a range of contexts, including warranty and sales, manufacturing and supply chain, connected vehicles, and charging stations” writes Sridhar Mamella (Platform Manager Data Streaming at Porsche).
As you can see in the above architecture, there is no need to fight REST / HTTP and Event Streaming / Kafka enthusiasts! As I explained in detail before, most microservice architectures need Apache Kafka and API Management for REST. HTTP and Kafka complement each other very well!
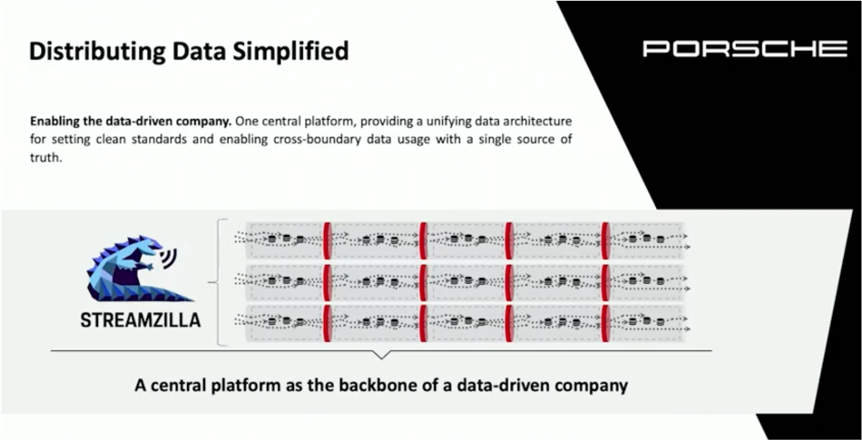
Porsche – A Central platform as the Backbone of a Data-driven Company
Porsche built a central platform strategy across data centers, clouds, and regions (with the really cool, innovative name Streamzilla) to enable the data-driven company. Their Kafka Summit talk shows this platform in more detail:
One interesting solution is the “Over The Air (OTA) update mechanism” powered by Apache Kafka to enable digital aftersales and other use cases:
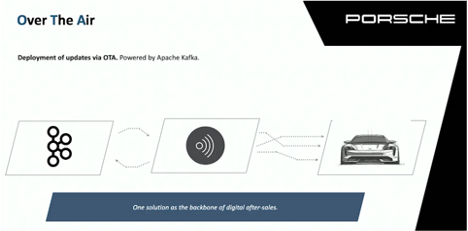
Last but not least, a great podcast link: The Porsche guys talked about “Apache Kafka and Porsche: Fast Cars and Fast Data” to explain Streamzilla.
DriveCentric – CRM for Automotive Dealerships
While I showed a lot of great use cases from OEMs, that’s not all. Many Tier 1 and Tier 2 suppliers and other third-party software providers leverage Apache Kafka to build innovative offerings. One example is DriveCentric, a scalable real-time CRM for automotive dealerships.
The solution provides a 360-degree customer experience with effective customer engagement across all channels. A few benefits: Boost engagement, shorten sales cycles, and spur growth. This is yet another great example of why Kafka became the de facto standard for decoupled microservice architectures and omnichannel scenarios.
DriveCentric wanted to focus on business, not infrastructure. For that reason, they started with Confluent Cloud, the (only) truly serverless offering for Kafka. If you don’t understand the difference between a partially managed Kafka offering and a truly fully-managed Kafka offering, check out this discussion about serverless Kafka offerings on the cloud market. A more general comparison of Kafka vendors is also available.
Uber / Lyft / Otonomo / Here Technologies – Innovative Mobility Services
The spectrum of mobility services is huge and still growing at an unbelievable speed. This is where I see most of the innovation for the improvement of customer experiences. This topic is worth its own blog post, but let me share a quick overview about a few of the examples:
- Uber uses Kafka at an extreme scale for trillions of messages and multiple petabytes of data per day to “Building the World’s Real-time Transit Infrastructure“.
- Lyft, similarly using Kafka everywhere, talked about a specific example for doing streaming analytics to implement map-matching, ETA, and cost calculation in real-time.
- Here Technologies, majority-owned by a consortium of German automotive companies (namely Audi, BMW, Daimler) and American semiconductor company Intel, captures location content such as road networks, buildings, parks, and traffic patterns. Its public API exposes a Kafka-native interface instead of just non-scalable REST/HTTP. For this reason, streaming API Management for Kafka gets more and more relevant.
- Otonomo is an open API platform for car data that enables you to accelerate time to market for new services. Kafka is part of their central infrastructure to integrate and process the high volumes of vehicle data.
- FREE NOW (former mytaxi) is a mobility as a service provider (a joint venture between BMW and Daimler Mobility). You can see them as the “European version of Uber”.
FREE NOW – Real-time Streaming Analytics in the Cloud
Let’s talk about FREE NOW in more detail to explore at least one scenario for mobility services. The use case is very similar to other ride-hailing app: Data correlation for huge volumes of events from various data sources. Real-time. 24/7. A perfect fit for the Kafka ecosystem. The following example show how they leverage stream processing to calculate the surge factor (i.e. the price of the ride depending on the current demand in the region) in real-time:
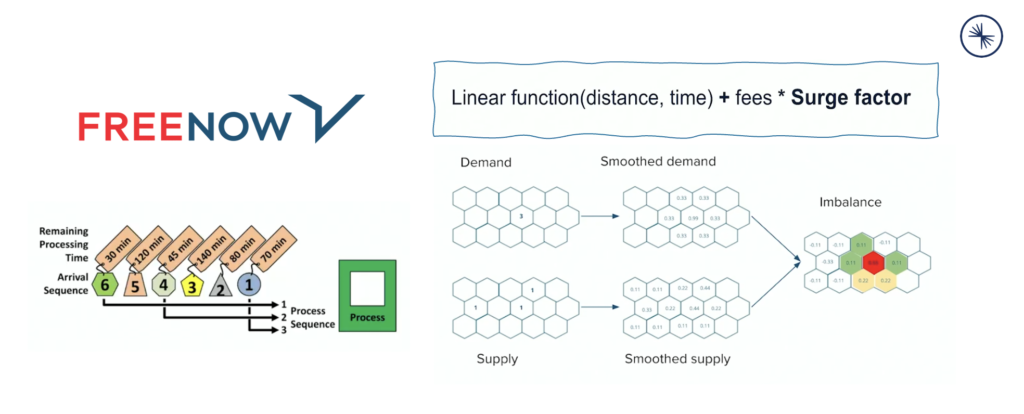
A few notes from FREE NOW’s Kafka summit talk:
- Stateful stream processing with Confluent Cloud, Kafka Connect, Kafka Streams, Schema Registry
- Cloud-native application elasticity and scalability leveraging Kafka and Kubernetes capabilities
- Use cases: Dynamic pricing, fraud detection, real-time analytics for marketing campaigns, etc.
- Various information about the trip, location and business performance
Where Kafka can (not) help in the automotive industry
The various real-world deployments show how well Kafka and its ecosystem fit into the automotive industry. Let’s conclude the post with a few notes about aspects that Kafka is NOT built for:
- Hard real-time and safety-critical car IT: Kafka has latency spikes and no detemernistic network (like almost all IT frameworks). Kafka is soft real-time for 10+ milliseconds end-to-end processing. That’s sufficient for most use cases and scalaes for high volumes. But it is not built for safety critical logic in the vehicle, robot or machine. Learn more in the post “Apache Kafka is NOT Hard Real Time BUT Used Everywhere in Automotive and Industrial IoT“.
- Last mile integration: Kafka can integrate with the OT world (machines, PLCs, sensors, etc.). Frameworks like PLC4X provide a Kafka Connect connector. Some customers also use Eclipse Kura for IoT integration. The Confluent REST Proxy and other gateways can connect to smart devices and mobile apps. Having said this, in most cases, the last mile integration is implemented with dedicated IoT platforms or HTTP proxies. Kafka itself cannot connect to hundreds of thoudands of devices. It does also not speak low level proprietary legacy protocols. Additionally, Kafka does not work well in unreliable networks. I have several posts covering this discussion, including PLC4X integration, MQTT integration, Kafka as Modern Data Historian, and many more.
Slides and Video for Kafka in the Automotive Industry
I summarized the content in a presentation. Here is the slide deck:
https://www.slideshare.net/KaiWaehner/apache-kafka-in-the-automotive-industry-connected-vehicles-manufacturing-40-mobility-services-smart-city
And here is the on-demand video recording walking you through the above slides:
You are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
Data in Motion is the new Black in the Automotive Industry
Apache Kafka became the central nervous system of many applications in various different areas related to the automotive industry. You have seen real-world deployments across different fields including connected vehicles, smart manufacturing, and innovative mobility services. Exciting examples covered car makers such as Audi, BMW, Porsche, and Tesla, plus a few mobility services such as Uber, Lyft, and Here Technologies.
How do you leverage Apache Kafka and its ecosystem in the automotive industry? What projects did you already deploy? What technologies do you combine with Kafka and why? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
