
Data Streaming is one of the most relevant buzzwords in tech to build scalable real-time applications and innovative business models. Do you wonder about my predicted TOP 5 data streaming trends in 2024 to set data in motion? Learn what role Apache Kafka and Apache Flink play. Discover new technology trends and best practices for event-driven architectures, including data sharing, data contracts, serverless stream processing, multi-cloud architectures, and GenAI.
Some followers might notice that this became a series with past posts about the top 5 data streaming trends for 2021, the top 5 for 2022, and the top 5 for 2023. Trends change over time, but the huge value of having a scalable real-time infrastructure as the central data hub stays. Data streaming with Apache Kafka is a journey and evolution to set data in motion.

Gartner’s top strategic technology trends 2024
The research and consulting company Gartner defines the top strategic technology trends every year. This time, the trends are around building new (AI) platforms and delivering value by automation, but also protecting investment. On a higher level, it is all about automating, scaling, and pioneering. Here is what Gartner expects for 2024:

It is funny (but not surprising): Gartner’s predictions overlap and complement the five trends I focus on for data streaming with Apache Kafka looking forward to 2024. I explore how data streaming enables faster time to market, good data quality across independent data products, and innovation with technologies like Generative AI.
The top 5 data streaming trends for 2024
I see the following topics coming up more regularly in conversations with customers, prospects, and the broader data streaming community across the globe:
- Data sharing for faster innovation with independent data products
- Data contracts for better data governance and policy enforcement
- Serverless stream processing for easier building of scalable and elastic streaming apps
- Multi-cloud deployments for cost-efficient delivering value where the customers sit
- Reliable Generative AI (GenAI) with embedded accurate, up-to-date information to avoid hallucination
The following sections describe each trend in more detail. The trends are relevant for many scenarios; no matter if you use open source Apache Kafka or Apache Flink, a commercial platform, or a fully managed cloud service like Confluent Cloud. I start each section with a real-world case study. The end of the article contains the complete slide deck and video recording.
Data sharing across business units and organizations
Data sharing refers to the process of exchanging or providing access to data among different individuals, organizations, or systems. This can involve sharing data within an organization or sharing data with external entities. The goal of data sharing is to make information available to those who need it, whether for collaboration, analysis, decision-making, or other purposes. Obviously, real-time data beats slow data for almost all data sharing use cases.
NASA: Real-time data sharing with Apache Kafka

Apache Kafka plays an essential role in astronomy research for data sharing. Particularly where black holes and neutron stars are involved, astronomers are increasingly seeking out the “time domain” and want to study explosive transients and variability. In response, observatories are increasingly adopting streaming technologies to send alerts to astronomers and to get their data to their science users in real time.
The talk “General Coordinates Network: Harnessing Kafka for Real-Time Open Astronomy at NASA” explores architectural choices, challenges, and lessons learned in adapting Kafka for open science and open data sharing at NASA.
NASA’s approach to OpenID Connect / OAuth2 in Kafka is designed to securely scale Kafka from access inside a single organization to access by the general public.
Stream data exchange with Kafka using cluster linking, stream sharing, and AsyncAPI
The Kafka ecosystem provides various functions to share data in real-time at any scale. Some are vendor-specific. I look at this from the perspective of Confluent, so that you see a lot of innovative options (even if you want to build it by yourself with open source Kafka):
- Kafka Connect connector ecosystem to integrate with other data sources and sinks out-of-the-box
- HTTP/REST proxies and connectors for Kafka to use simple and well understood request-response (HTTP is, unfortunately, also an anti-pattern for streaming data)
- Cluster Linking for replication between Kafka clusters using the native Kafka protocol (instead of separate infrastructure like MirrorMaker)
- Stream Sharing for exposing a Kafka Topic through a simple button click with access control, encryption, quotas, and chargeback billing APIs
- Generation of AsyncAPI specs to share data with non-Kafka applications (like other message brokers or API gateways that support AsyncAPI, which is an open data for contract for asynchronous event-based messaging (similar to Swagger for HTTP/REST APIs)
Here is an example for Cluster Linking for bi-directional replication between Kafka clusters in the automotive industry:
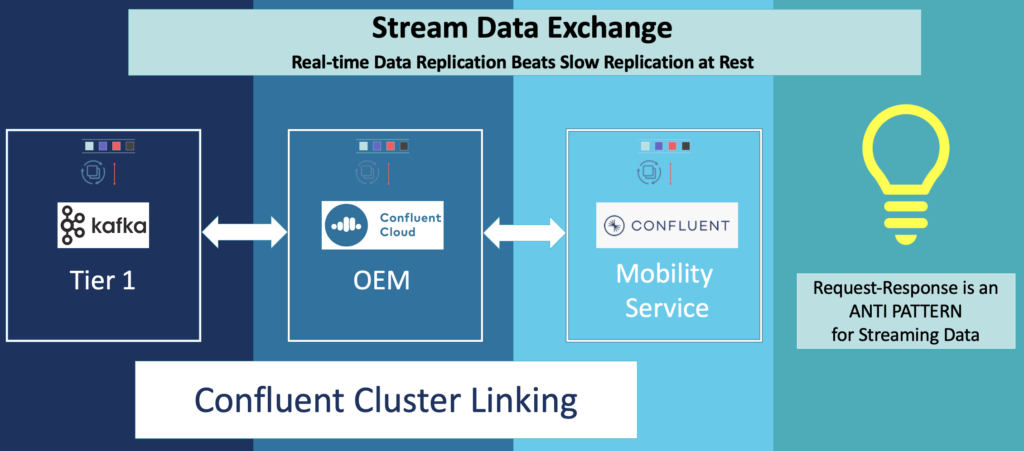
And another example of stream sharing for easy access to a Kafka Topic in financial services:
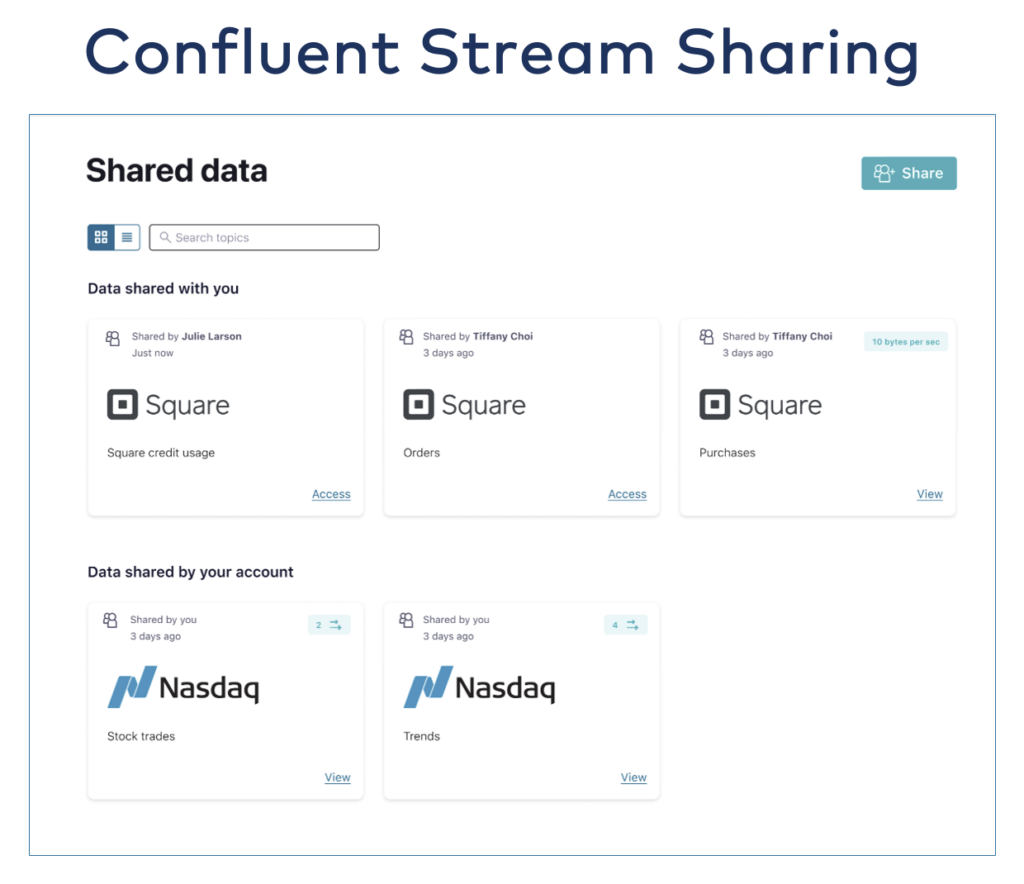
To learn more, check out the article “Streaming Data Exchange with Kafka and a Data Mesh in Motion“.
Data contracts for data governance and policy enforcement
A data contract is an agreement or understanding that defines the terms and conditions governing the exchange or sharing of data between parties. It is a formal arrangement specifying how data will be handled, used, protected, and shared among entities. Data contracts are crucial when multiple parties need to interact with and utilize shared data, ensuring clarity and compliance with agreed-upon rules.
Raiffeisen Bank International: Data contracts for data sharing across countries
Raiffeisen Bank International (RBI) is scaling an event-driven architecture across the group as part of a bank-wide transformation program. This includes the creation of a reference architecture and the re-use of technology and concepts across 12 countries.
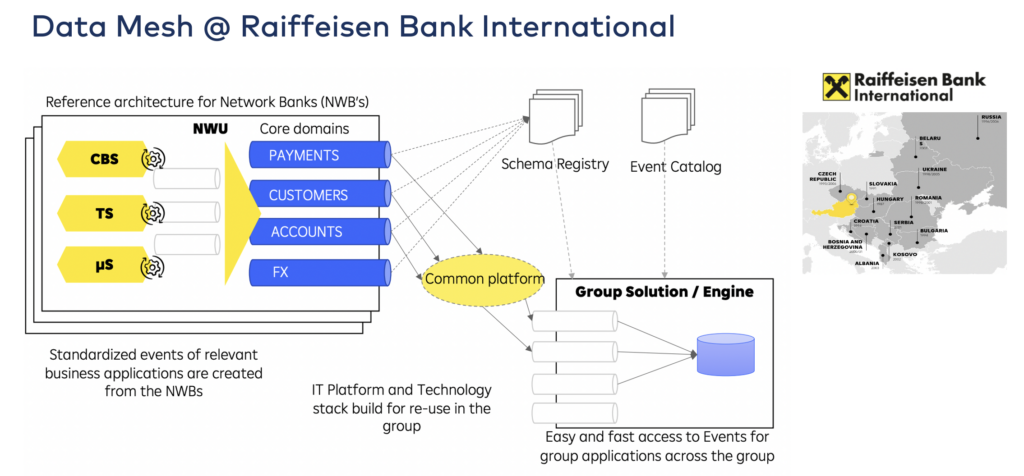
Learn more in the article “Decentralized Data Mesh with Data Streaming in Financial Services“.
Policy enforcement and data quality for Apache Kafka with Schema Registry
Good data quality is one of the most critical requirements in decoupled architectures like microservices or data mesh. Apache Kafka became the de facto standard for these architectures. But Kafka is a dumb broker that only stores byte arrays. The Schema Registry for Apache Kafka enforces message structures.
This blog post examines Schema Registry enhancements to leverage data contracts for policies and rules to enforce good data quality on field-level and advanced use cases like routing malicious messages to a dead letter queue.

For more details: Building a data mesh with decoupled data products and good data quality, governance, and policy enforcement.
Serverless stream processing with Apache Flink for scalable, elastic streaming apps
Serverless stream processing refers to a computing architecture where developers can build and deploy applications without having to manage the underlying infrastructure.
In the context of stream processing, it involves the real-time processing of data streams without the need to provision or manage servers explicitly. This approach allows developers to focus on writing code and building applications. The cloud service takes care of the operational aspects, such as scaling, provisioning, and maintaining servers.
Sencrop: Smart agriculture with Apache Kafka and Apache Flink
Designed to answer professional farmers’ needs, Sencrop offers a range of connected
weather stations that bring you precision agricultural weather data straight from your plots.
- Over 20,000 connected ag-weather stations throughout Europe.
- An intuitive, user-friendly application: Access accurate, ultra-local data to optimize your daily actions.
- Prevent risks, reduce costs: Streamline inputs and reduce your environmental impact and associated costs.
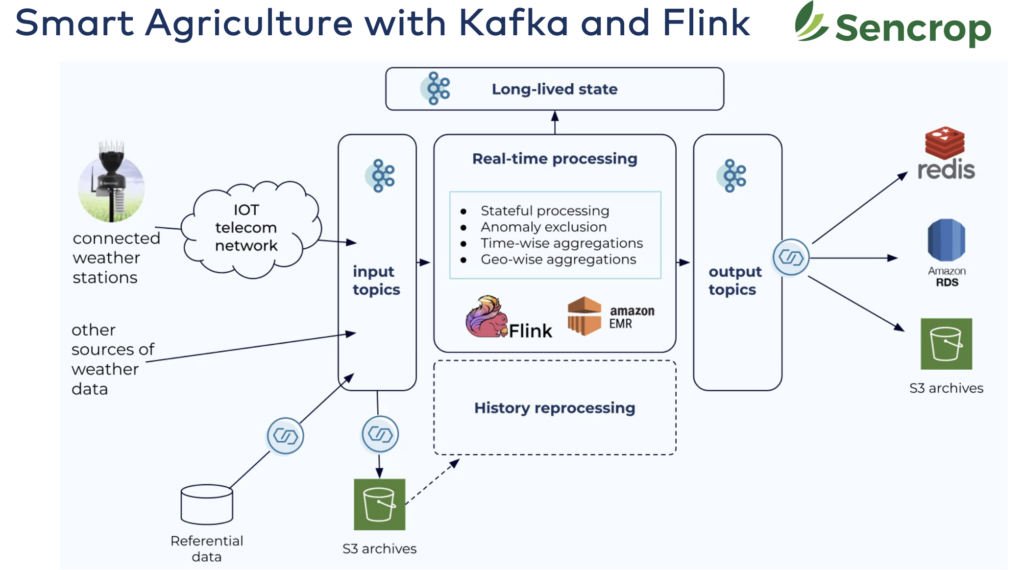
Apache Flink becomes the de facto standard for stream processing
Apache Kafka and Apache Flink increasingly join forces to build innovative real-time stream processing applications.
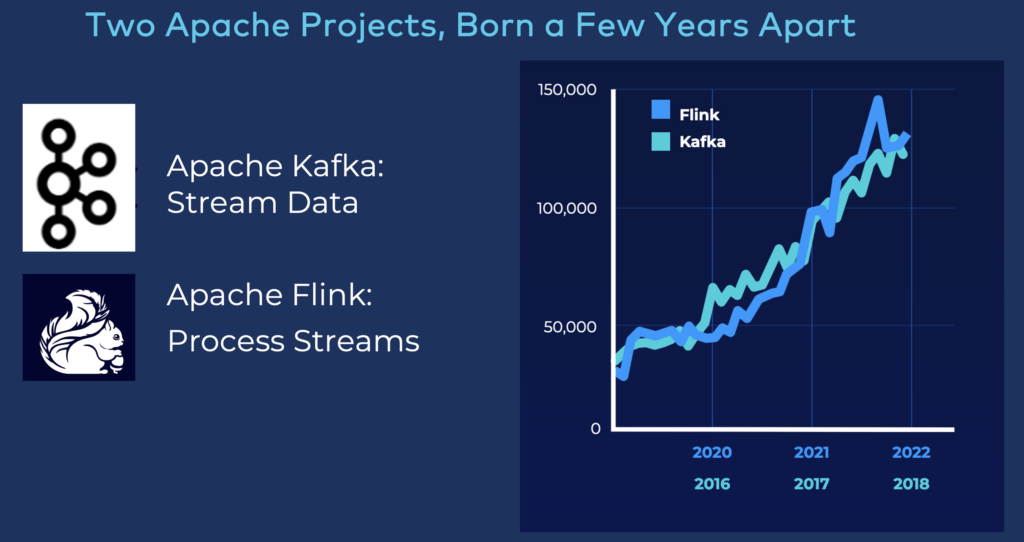
The Y-axis in the diagram shows the monthly unique users (based on statistics of Maven downloads).
“Apache Kafka + Apache Flink = Match Made in Heaven” explores the benefits of combining both open-source frameworks. The article shows unique differentiators of Flink versus Kafka, and discusses when to use a Kafka-native streaming engine like Kafka Streams instead of Flink.
Unfortunately, operating a Flink cluster is really hard. Even harder than Kafka. Because Flink is not just a distributed system, it also has to keep state of applications for hours or even longer. Hence, serverless stream processing helps taking over the operation burden. And it makes the life of the developer easier, too.
Staying tuned for exciting cloud products offering serverless Flink in 2024. But be aware that some vendors use the same trick as for Kafka: Provisioning a Flink cluster and handing it over to you is NOT a serverless or fully-managed offering! For that reason, I compared Kafka products as self-driving cars vs. self-driving cars, i.e. cloud-based Kafka clusters you operate vs. truly fully managed services.
Multi-cloud for cost-efficient and reliable customer experience
Multi-cloud refers to a cloud computing strategy that uses services from multiple cloud providers to meet specific business or technical requirements. In a multi-cloud environment, organizations distribute their workloads across two or more cloud platforms, including public clouds, private clouds, or a combination of both.
The goal of a multi-cloud strategy is to avoid dependence on a single cloud provider and to leverage the strengths of different providers for various needs. Cost efficiency and regional laws (like operating in the United States or China) required different deployment strategies. Some countries do not provide a public cloud. A private cloud is the only option then.
New Relic: Multi-cloud Kafka deployments at extreme scale for real-time observability
New Relic is a software analytics company that provides monitoring and performance management solutions for applications and infrastructure. It’s designed to help organizations gain insights into the performance of their software and systems, allowing them to optimize and troubleshoot issues efficiently.
Observability has two key requirements: first, monitor data in real-time at any scale. Second, deploy the monitoring solution where the applications are running. The obvious consequence for New Relic is to process data with Apache Kafka, and multi-cloud where the customers are.

Hybrid and multi-cloud data replication for cost-efficiency, low latency, or disaster recovery
Multi-cloud deployments of Apache Kafka have become the norm rather than an exception. Several scenarios require multi-cluster solutions with specific requirements and trade-offs:
- Regional separation because of legal requirements
- Independence of a single cloud provider
- Disaster recovery
- Aggregation for analytics
- Cloud migration
- Mission-critical stretched deployments
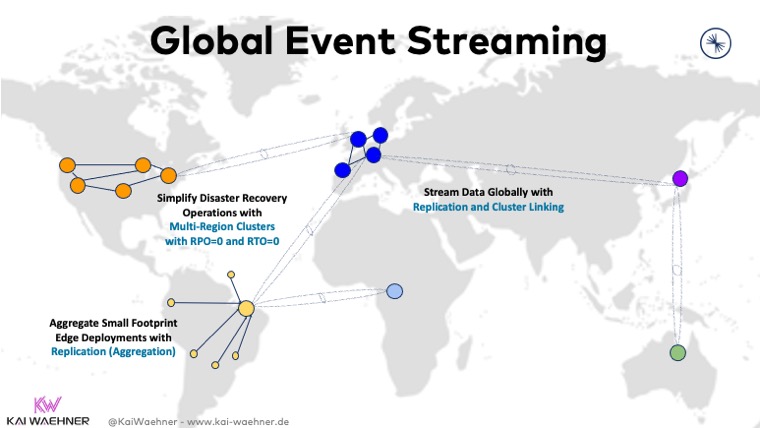
The blog post “Architecture Patterns for Distributed, Hybrid, Edge and Global Apache Kafka Deployments” explores various architectures and best practices.
Reliable Generative AI (GenAI) with accurate context to avoid hallucination
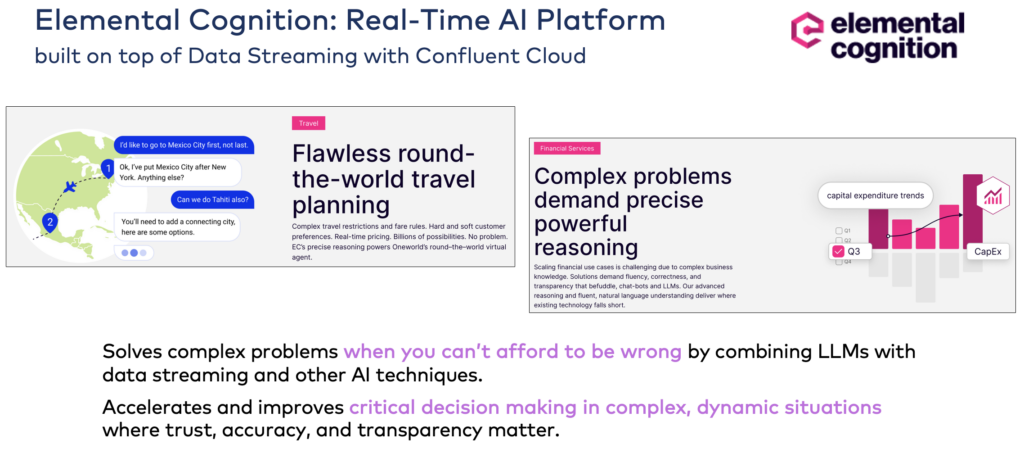
Elemental Cognition: GenAI platform powered by Apache Kafka
Elemental Cognition’s AI platform develops responsible and transparent AI that helps solve problems and deliver expertise that can be understood and trusted.
Confluent Cloud powers the AI platform to enable scalable real-time data and data integration use cases. I recommend looking at their website to learn from various impressive use cases.
Apache Kafka as data fabric for GenAI using RAG, vector database and semantic search
Apache Kafka serves thousands of enterprises as the mission-critical and scalable real-time data fabric for machine learning infrastructures. The evolution of Generative AI (GenAI) with large language models (LLM) like ChatGPT changed how people think about intelligent software and automation. The relationship between data streaming and GenAI has enormous opportunities.
“Apache Kafka as Mission Critical Data Fabric for GenAI” explores the use cases for combining data streaming with Generative AI.
An excellent example, especially for Generative AI, is context-specific customer service. The following diagram shows an enterprise architecture leveraging event-driven data streaming for data ingestion and processing across the entire GenAI pipeline:
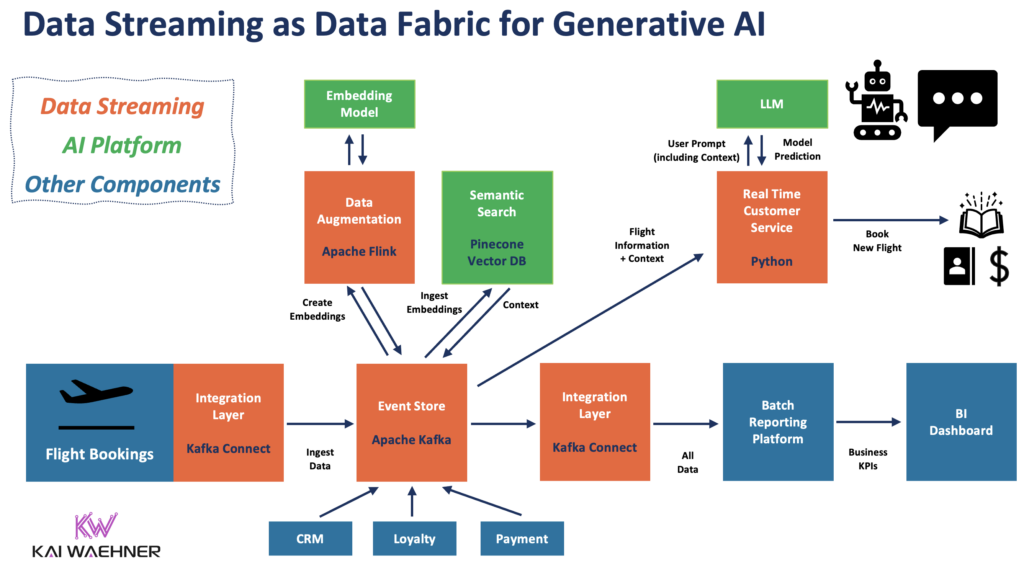
Stateful stream processing with Apache Flink and GenAI using a Large Language Model (LLM)
Stream processing with Kafka and Flink enables data correlation of real-time and historical data. A stateful stream processor takes existing customer information from the CRM, loyalty platform, and other applications, correlates it with the query from the customer into the chatbot, and makes an RPC call to an LLM.
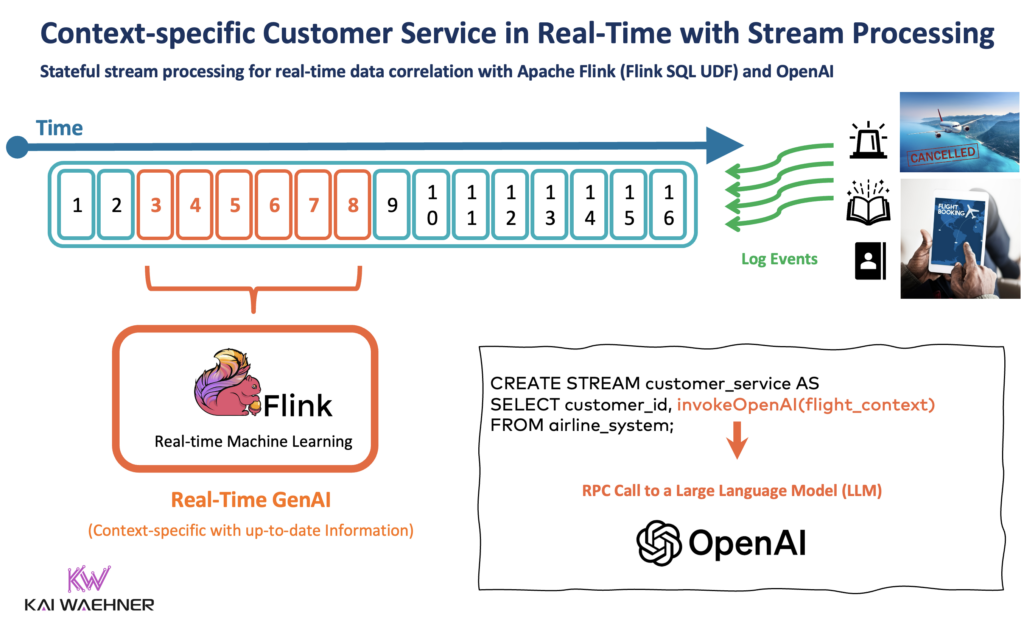
The article “Apache Kafka + Vector Database + LLM = Real-Time GenAI” explores possible architectures, examples, and trade-offs between event streaming and traditional request-response APIs and databases.
Slides and video recording for the data streaming trends in 2024 with Kafka and Flink
Do you want to look at more details? This section provides the entire slide deck and a video walking you through the content.
Slide deck
Here is the slide deck from my presentation:
Fullscreen ModeVideo recording
And here is the video recording of my presentation:

2024 makes data streaming more mature, and Apache Flink becomes mainstream
I have two conclusions for data streaming trends in 2024:
- Data streaming goes up in the maturity curve. More and more projects build streaming applications instead of just leveraging Apache Kafka as a dumb data pipeline between databases, data warehouses, and data lakes.
- Apache Flink becomes mainstream. The open source framework shines with a scalable engine, multiple APIs like SQL, Java, and Python, and serverless cloud offerings from various software vendors. The latter makes building applications much more accessible.
Data sharing with data contracts is mandatory for a successful enterprise architecture with microservices or a data mesh. And data streaming is the foundation for innovation with technology trends like Generative AI. Therefore, we are just at the tipping point of adopting data streaming technologies such as Apache Kafka and Apache Flink.
What are your most relevant and exciting data streaming trends with Apache Kafka and Apache Flink in 2024 to set data in motion? What are your strategy and timeline? Do you use serverless cloud offerings or self-managed infrastructure? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
