Data streaming emerged as a new software category. It complements traditional middleware, data warehouse, and data lakes. Apache Kafka became the de facto standard. New players enter the market because of Kafka’s success. One of those is Redpanda, a lightweight Kafka-compatible C++ implementation. This blog post explores the differences between Apache Kafka and Redpanda, when to choose which framework, and how the Kafka ecosystem, licensing, and community adoption impact a proper evaluation.

Disclaimer: I work for Confluent. However, the post is not about comparing features but explaining the concepts behind the alternatives of using Apache Kafka (and related products, including Confluent) or Redpanda. I talk to enterprises across the globe every week. Below, I summarize common misunderstandings or missing knowledge about both technologies. I hope it helps you to make the right decision. Either choose to run open-source Apache Kafka, one of the various commercial Kafka offerings or cloud services, or Redpanda. All are great options with pros and cons…
Data streaming: A new software category
Data-driven applications are the new black. As part of this, data streaming is a new software category. If you don’t understand yet how it differs from other data management platforms like a data warehouse or data lake, check out the following blog series:
- Data Warehouse vs. Data Lake vs. Data Streaming – Friends, Enemies, Frenemies?
- Data Streaming for Data Ingestion into the Data Warehouse and Data Lake
- Data Warehouse Modernization: From Legacy On-Premise to Cloud-Native Infrastructure
- Case Studies: Cloud-native Data Streaming for Data Warehouse Modernization
- Lessons Learned from Building a Cloud-Native Data Warehouse
And if you wonder how Apache Kafka differs from other middleware, check out how Kafka fits into comparison with ETL, ESB, and iPaas.
Apache Kafka: The de facto standard for data streaming
Apache Kafka became the de facto standard for data streaming similar to Amazon S3 is the de facto standard for object storage. Kafka is used across industries for many use cases.
The adoption curve of Apache Kafka
The growth of the Apache Kafka community in the last years is impressive:
- >100,000 organizations using Apache Kafka
- >41,000 Kafka Meetup attendees
- >32,000 Stack Overflow Questions
- >12,000 Jiras for Apache Kafka
- >31,000 Open Job Listings Request Kafka Skills
And look at the increased number of active monthly unique users downloading the Kafka Java client library with Maven:
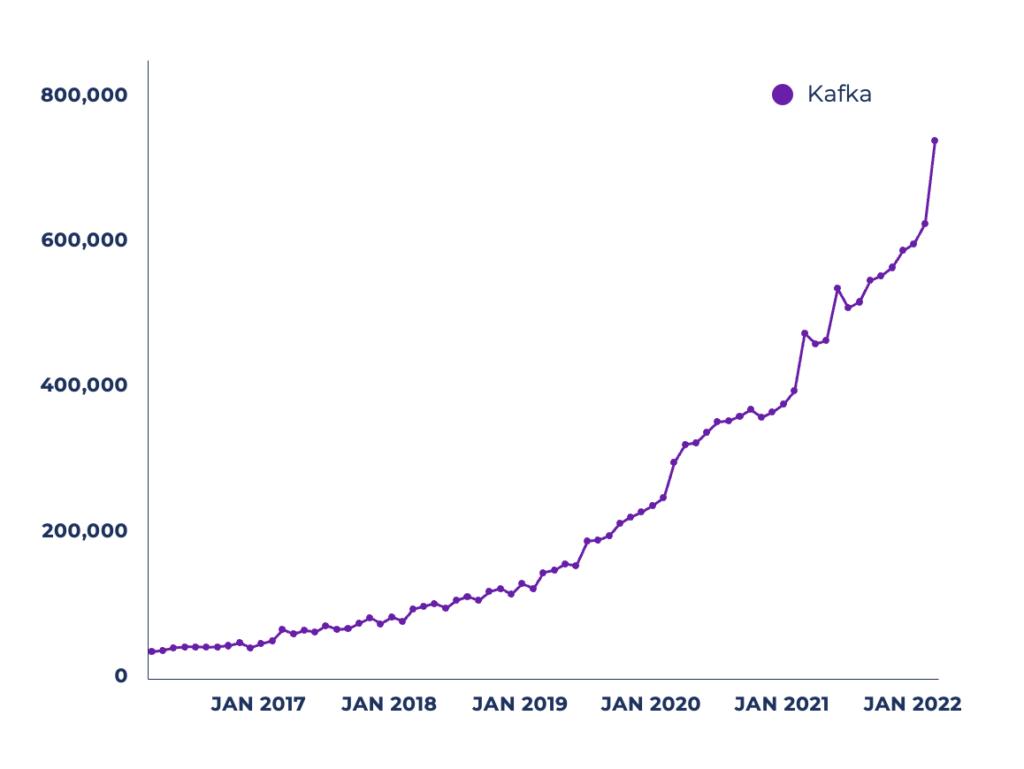
The numbers grow exponentially. That’s no surprise to me as the adoption pattern and maturity curve for Kafka are similar in most companies:
- Start with one or few use cases (that prove the business value quickly)
- Deploy the first applications to production and operate them 24/7
- Tap into the data streams from many domains, business units, and technologies
- Move to a strategic central nervous system with a decentralized data hub
Kafka use cases by business value across industries
The main reason for the incredible growth of Kafka’s adoption curve is the variety of potential use cases for data streaming. The potential is almost endless. Kafka’s characteristics of combing low latency, scalability, reliability, and true decoupling establish benefits across all industries and use cases:
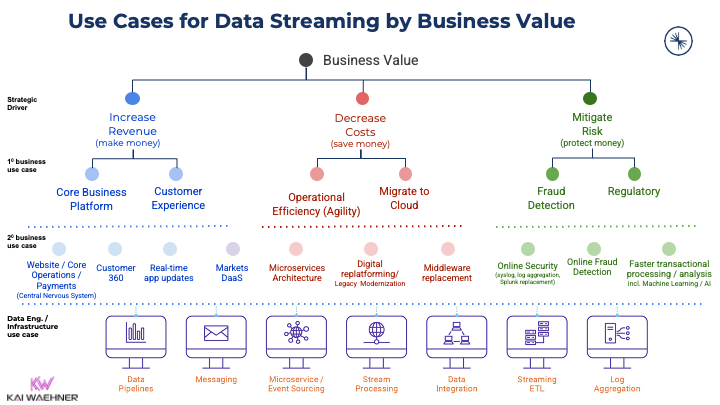
Search my blog for your favorite industry to find plenty of case studies and architectures. Or to get started, read about use cases for Apache Kafka across industries.
The emergence of many Kafka vendors
The market for data streaming is enormous. With so many potential use cases, it is no surprise that more and more software vendors add Kafka support to their products. Most vendors use Kafka or implement its protocol because Kafka has become the de facto standard for data streaming.
Learn more about the various data streaming vendors in the following blog posts:
- Comparison of on-premise Kafka vendors and cloud services
- Open Source Apache Pulsar vs. Apache Kafka
- Confluent Cloud versus Amazon MSK Serverless
- Why companies migrate from Amazon SQS and Kinesis to Apache Kafka
To be clear: An increasing number of Kafka vendors is a great thing! It proves the creation of a new software category. Competition pushes innovation. The market share is big enough for many vendors. And I am 100% convinced that we are still in a very early stage of the data streaming hype cycle…
After a lengthy introduction to set the context, let’s now review a new entrant into the Kafka market: Redpanda…
Introducing Redpanda: Kafka-compatible data streaming
Redpanda is a data streaming platform. Its website explains its positioning in the market and product strategy as follows (to differentiate it from Apache Kafka):
- No Java: A JVM-free and ZooKeeper-free infrastructure.
- Designed in C++: Designed for a better performance than Apache Kafka.
- A single-binary architecture: No dependencies to other libraries or nodes.
- Self-managing and self-healing: A simple but scalable architecture for on-premise and cloud deployments.
- Kafka-compatible: Out-of-the-box support for the Kafka protocol with existing applications, tools, and integrations.
This sounds great. You need to evaluate whether Redpanda is the right choice for your next project or if you should stick with “real Apache Kafka”.
How to choose the proper “Kafka” implementation for your project?
A recommendation that some people find surprising: Qualify out first! That’s much easier. Similarly, like I explained when NOT to use Apache Kafka.
As part of the evaluation, the question is if Kafka is the proper protocol for you. And for Kafka, pick different offerings and begin with the comparison.
Start your evaluation with the business case requirements and define your most critical needs like uptime SLAs, disaster recovery strategy, enterprise support, operations tooling, self-managed vs. fully-managed cloud service, capabilities like messaging vs. data ingestion vs. data integration vs. applications, and so on. Based on your use cases and requirements, you can start qualifying out vendors like Confluent, Redpanda, Cloudera, Red Hat / IBM, Amazon MSK, Amazon Kinesis, Google Pub Sub, and others to create a shortlist.
The following sections compare the open-source project Apache Kafka versus the re-implementation of the Kafka protocol of Redpanda. You can use these criteria (and information from other blogs, articles, videos, and so on) to evaluate your options.
Similarities between Redpanda and Apache Kafka
The high-level value propositions are the same in Redpanda and Apache Kafka:
- Data streaming to process data in real-time at scale continuously
- Decouple applications and domains with a distributed storage layer
- Integrate with various data sources and data sinks
- Leverage stream processing to correlate data and take action in real-time
- Self-managed operations or consuming a fully-managed cloud offering
However, the devil is in the details and facts. Don’t trust marketing, but look deeper into the various products and cloud services.
Deployment options: Self-managed vs. cloud service
Data streaming is required everywhere. While most companies across industries have a cloud-first strategy, some workloads must stay at the edge for different reasons: Cost, latency, or security requirements. My blog about use cases for Apache Kafka at the edge is still one of the most read articles I have written in recent years.
Besides operating Redpanda by yourself, you can buy Redpanda as a product and deploy it in your environment. Instead of just self-hosting Redpanda, you can deploy it as a data plane in your environment using Kubernetes (supported by the vendor’s external control plane) or leverage a cloud service (fully managed by the vendor).
The different deployment options for Redpanda are great. Pick what you need. This is very similar to Confluent’s deployment options for Apache Kafka. Some other Kafka vendors only provide either self-managed (e.g., Cloudera) or fully managed (e.g., Amazon MSK Serverless) deployment options.
What I miss from Redpanda: No official documentation about SLAs of the cloud service and enterprise support. I hope they do better than Amazon MSK (excluding Kafka support from their cloud offerings). I am sure you will get that information if you reach out to the Redpanda team, who will probably soon incorporate some information into their website.
Bring your own Cluster (BYOC)
There is a third option besides self-managing a data streaming cluster and leveraging a fully managed cloud service: Bring your own Cluster (BYOC). This alternative allows end users to deploy a solution partially managed by the vendor in your own infrastructure (like your data center or your cloud VPC).
Here is Redpanda’s marketing slogan: “Redpanda clusters hosted on your cloud, fully managed by Redpanda, so that your data never leaves your environment!”
This sounds very appealing in theory. Unfortunately, it creates more questions and problems than it solves:
- How does the vendor access your data center or VPC?
- Who decides how and when to scale a cluster?
- When to act on issues? How and when do you roll a cluster to incorporate bug fixes or version upgrades?
- What about cost management? What is the total cost of ownership? How much value does the vendor solution bring?
- How do you guarantee SLAs? Who has to guarantee them, you or the vendor?
- For regulated industries, how are security controls and compliance supported? How are you sure about what the vendor does in an environment you ostensibly control? How much harder will a bespoke third-party risk assessment be if you aren’t using pure SaaS?
For these reasons, cloud vendors only host managed services in the cloud vendor’s environment. Look at Amazon MSK, Azure Event Hubs, Google Pub Sub, Confluent Cloud, etc. All fully managed cloud services are only in the VPC of the vendor for the above reasons.
There are only two options: Either you hand over the responsibility to a SaaS offering or control it yourself. Everything in the middle is still your responsibility in the end.
Community vs. commercial offerings
The sales approach of Redpanda looks almost identical to how Confluent sells data streaming. A free community edition is available, even for production usage. The enterprise edition adds enterprise features like tiered storage, automatic data balancing, or 24/7 enterprise support.
No surprise here. And a good strategy, as data streaming is required everywhere for different users and buyers.
Technical differences between Apache Kafka and Redpanda
There are plenty of technical and non-functional differences between Apache Kafka products and Redpanda. Keep in mind that Redpanda is NOT Kafka. Redpanda uses the Kafka protocol. This is a small but critical difference. Let’s explore these details in the following sections.
Apache Kafka vs. Kafka protocol compatibility
Redpanda is NOT an Apache Kafka distribution like Confluent Platform, Cloudera, or Red Hat. Instead, Redpanda re-implements the Kafka protocol to provide API compatibility. Being Kafka-compatible is not the same as using Apache Kafka under the hood, even if it sounds great in theory.
Two other examples of Kafka-compatible offerings:
- Azure Event Hubs: A Kafka-compatible SaaS cloud service offering from Microsoft Azure. The service itself works and performs well. However, its Kafka compatibility has many limitations. Microsoft lists a lot of them on its website. Some limitations of the cloud service are the consequence of a different implementation under the hood, like limited retention time and message sizes.
- Apache Pulsar: An open-source framework competing with Kafka. The feature set overlaps a lot. Unfortunately, Pulsar often only has good marketing for advanced features to compete with Kafka or to differentiate. And one example is its Kafka mapper to be compatible with the Kafka protocol. Contrary to Azure Event Hubs as a serious implementation (with some limitations), Pulsar’s compatibility wrapper provides a basic implementation that is compatible with only minor parts of the Kafka protocol. So, while alleged “Kafka compatibility” sounds nice on paper, one shouldn’t seriously consider this for migrating your running Kafka infrastructure to Pulsar.
We have seen compatible products for open-source frameworks in the past. Re-implementations are usually far away from being complete and perfect. For instance, MongoDB compared the official open source protocol to its competitor Amazon DocumentDB to pinpoint the fact that DocumentDB only passes ~33% of the MongoDB integration test chain.
In summary, it is totally fine to use these non-Kafka solutions like Azure Event Hubs, Apache Pulsar, or Redpanda for a new project if they fulfill your requirements better than Apache Kafka. But keep in mind that it is not Kafka. There is no guarantee that additional components from the Kafka ecosystem (like Kafka Connect, Kafka Streams, REST Proxy, and Schema Registry) behave the same when integrated with a non-Kafka solution that only uses the Kafka protocol with its own implementation.
How good is Redpanda’s Kafka protocol compatibility?
Frankly, I don’t know. Probably and hopefully, Redpanda has better Kafka compatibility than Pulsar. The whole product is based on this value proposition. Hence, we can assume that the Redpanda team spends plenty of time on compatibility. Redpanda has NOT achieved 100% API compatibility yet.
Time will tell when we see more case studies from enterprises across industries that migrated some Apache Kafka projects to Redpanda and successfully operated the infrastructure for a few years. Why wait a few years to see? Well, I compare it to what I see from people starting with Amazon MSK. It is pretty easy to get started. However, after a few months, the first issues happen. Users find out that Amazon MSK is not a fully-managed product and does not provide serious Kafka SLAs. Hence, I see too many teams starting with Amazon MSK and then migrating to Confluent Cloud after some months.
But let’s be clear: If you run an application against Apache Kafka and migrate to a re-implementation supporting the Kafka protocol, you should NOT expect 100% the same behavior as with Kafka!
Some underlying behavior will differ even if the API is 100% compatible. This is sometimes a benefit. For instance, Redpanda focuses on performance optimization with C++. This is only possible in some workloads because of the re-implementation. C++ is superior compared to Java and the JVM for some performance and memory scenarios.
Redpanda = Apache Kafka – Kafka Connect – Kafka Streams
Apache Kafka includes Kafka Connect for data integration and Kafka Streams for stream processing.
Like most Kafka-compatible projects, Redpanda does exclude these critical pieces from its offering. Hence, even 100 percent protocol compatibility would not mean a product re-implements everything in the Apache Kafka project.
Lower latency vs. benchmarketing
Always think about your performance requirements before starting a project. If necessary, do a proof of concept (POC) with Apache Kafka, Apache Pulsar, and Redpanda. I bet that in 99% of scenarios, all three of them will show a good enough performance for your use case.
Don’t trust opinionated benchmarks from others! Your use case will have different requirements and characteristics. And performance is typically just one of many evaluation dimensions.
I am not a fan of most “benchmarks” of performance and throughput. Benchmarks are almost always opinionated and configured for a specific problem (whether a vendor, independent consultant or researcher conducts them).
My colleague Jack Vanlightly explained this concept of benchmarketing with excellent diagrams:

Here is one concrete example you will find in one of Redpanda’s benchmarks: Kafka was not built for very high throughput producers, and this is what Redpanda is exploiting when they claim that Kafka’s throughput is inferior to Redpanda. Ask yourself this question: Of 1GB/s use cases, who would create that throughput with just 4 producers? Benchmarketing at its finest.
Hence, once again, start with your business requirements. Then choose the right tool for the job. Benchmarks are always built for winning against others. Nobody will publish a benchmark where the competition wins.
Soft real-time vs. hard real-time
When we speak about real-time in the IT world, we mean end-to-end data processing pipelines that need at least a few milliseconds. This is called soft real-time. And this is where Apache Kafka, Apache Pulsar, Redpanda, Azure Event Hubs, Apache Flink, Amazon Kinesis, and similar platforms fit into. None of these can do hard real time.
Hard real-time requires a deterministic network with zero latency and no spikes. Typical scenarios include embedded systems, field buses, and PLCs in manufacturing, cars, robots, securities trading, etc. Time-Sensitive Networking (TSN) is the right keyword if you want more research.
I wrote a dedicated blog post about why data streaming is NOT hard real-time. Hence, don’t try to use Kafka or Redpanda for these use cases. That’s OT (operational technology), not IT (information technology). OT is plain C or Rust on embedded software.
No ZooKeeper with Redpanda vs. no ZooKeeper with Kafka
Besides being implemented in C++ instead of using the JVM, the second big differentiator of Redpanda is no need for ZooKeeper and two complex distributed systems… Well, with Apache Kafka 3.3, this differentiator is gone. Kafka is now production-ready without ZooKeeper! KIP-500 was a multi-year journey and an operation at Kafka’s heart.
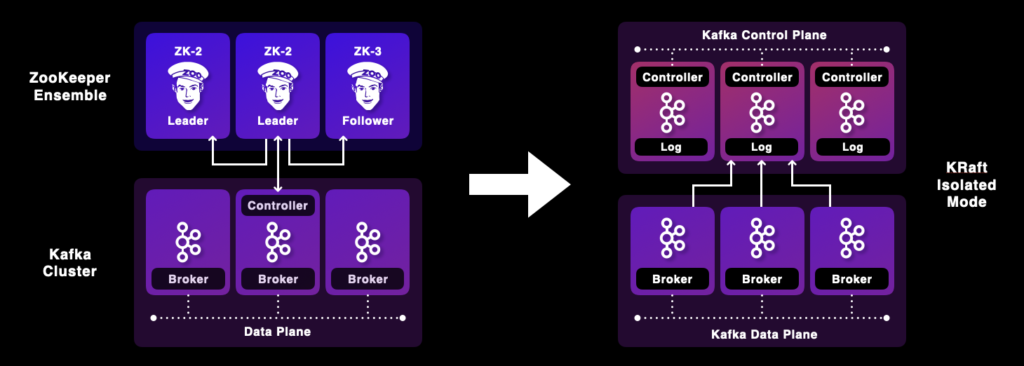
To be fair, it will still take some time until the new ZooKeeper-less architecture goes into production. Also, today, it is only supported by new Kafka clusters. However, migration scenarios with zero downtime and without data loss will be supported in 2023, too. But that’s how a severe release cycle works for a mature software product: Step-by-step implementation and battle-testing instead of starting with marketing and selling of alpha and beta features.
ZooKeeper-less data streaming with Kafka is not just a massive benefit for the scalability and reliability of Kafka but also makes operations much more straightforward, similar to ZooKeeper-less Redpanda.
By the way, this was one of the major arguments why I did not see the value of Apache Pulsar. The latter requires not just two but three distributed systems: Pulsar broker, ZooKeeper, and BookKeeper. That’s nonsense and unnecessary complexity for virtually all projects and use cases.
Lightweight Redpanda + heavyweight ecosystem = middleweight data streaming?
Redpanda is very lightweight and efficient because of its C++ implementation. This can help in limited compute environments like edge hardware. As an additional consequence, Redpanda has fewer latency spikes than Apache Kafka. That are significant arguments for Redpanda for some use cases!
However, you need to look at the complete end-to-end data pipeline. If you use Redpanda as a message queue, you get these benefits compared to the JVM-based Kafka engine. You might then pick a message queue like RabbitMQ or NATs instead. I don’t start this discussion here as I focus on the much more powerful and advanced data streaming use cases.
Even in edge use cases where you deploy a single Kafka broker, the hardware, like an industrial computer (IPC), usually provides at least 4GB or 8GB of memory. That is sufficient for deploying the whole data streaming platform around Kafka and other technologies.
Data streaming is more than messaging or data ingestion
My fundamental question is, what is the benefit of a C++ implementation of the data hub if all the surrounding systems are built with JVM technology or even worse and slow technologies like Python?
Kafka-compatible tools like Redpanda integrate well with the Kafka ecosystem, as they use the same protocol. Hence, tools like Kafka Connect, Kafka Streams, KSQL, Apache Flink, Faust, and all other components from the Kafka ecosystem work with Redpanda. You will find such an example for almost every existing Kafka tool on the Redpanda blog.
However, these combinations kill almost all the benefits of having a C++ layer in the middle. All integration and processing components would also need to be as efficient as Redpanda and use C++ (or Go or Rust) under the hood. These tools do not exist today (likely, as they are not needed by many people). And here is an additional drawback: The debugging, testing, and monitoring infrastructure must combine C++, Python, and JVM platforms if you combine tools like Java-based Kafka Connect and Python-based Faust with C++-based Redpanda. So, I don’t get the value proposition here.
Data replication across clusters
Having more than one Kafka cluster is the norm, not an exception. Use cases like disaster recovery, aggregation, data sovereignty in different countries, or migration from on-premise to the cloud require multiple data streaming clusters.
Replication across clusters is part of open-source Apache Kafka. MirrorMaker 2 (based on Kafka Connect) supports these use cases. More advanced (proprietary) tools from vendors like Confluent Replicator or Cluster Linking make these use cases more effortless and reliable.
Data streaming with the Kafka ecosystem is perfect as the foundation of a decentralized data mesh:
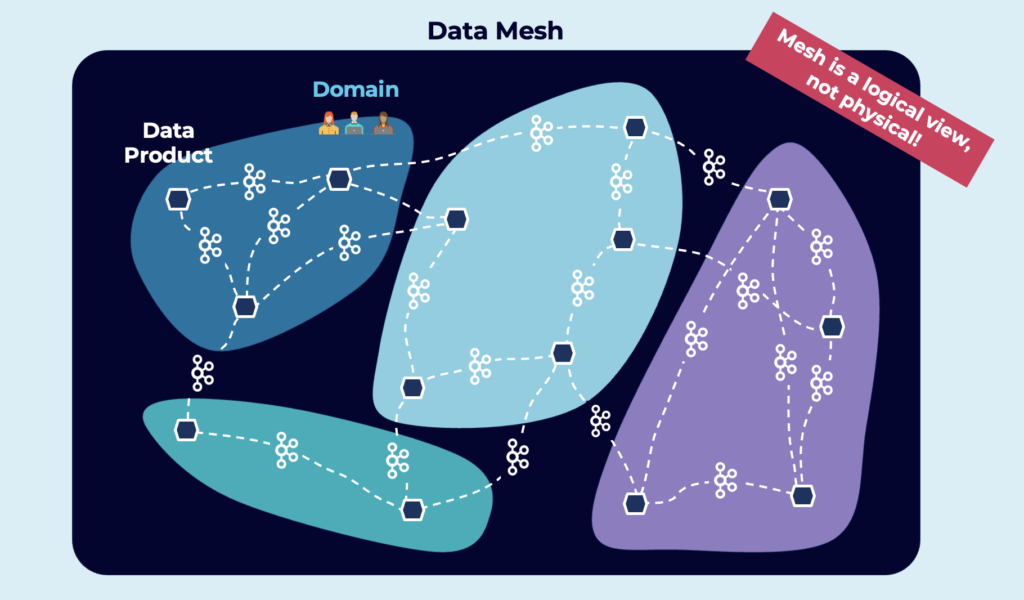
How do you build these use cases with Redpanda?
It is the same story as for data integration and stream processing: How much does it help to have a very lightweight and performant core if all other components rely on “3rd party” code bases and infrastructure? In the case of data replication, Redpanda uses Kafka’s Mirrormaker.
And make sure to compare MirrorMaker to Confluent Cluster Linking – the latter uses the Kafka protocol for replications and does not need additional infrastructure, operations, offset sync, etc.
Non-functional differences between Apache Kafka and Redpanda
Technical evaluations are dominant when talking about Redpanda vs. Apache Kafka. However, the non-functional differences are as crucial before making the strategic decision to choose the data streaming platform for your next project.
Licensing, adoption curve and the total cost of ownership (TCO) are critical for the success of establishing a data streaming platform.
Open source (Kafka) vs. source available (Redpanda)
As the name says, Apache Kafka is under the very permissive Apache license 2.0. Everyone, including cloud providers, can use the framework for building internal applications, commercial products, and cloud services. Committers and contributions are spread across various companies and individuals.
Redpanda is released under the more restrictive Source Available License (BSL). The intention is to deter cloud providers from offering Redpanda’s work as a service. For most companies, this is fine, but it limits broader adoption across different communities and vendors. The likelihood of external contributors, committers, or even other vendors picking the technology is much smaller than in Apache projects like Kafka.
This has a significant impact on the (future) adoption curve…
Maturity, community and ecosystem
The introduction of this article showed the impressive adoption of Kafka. Just keep in mind: Redpanda is NOT Apache Kafka! It just supports the Kafka protocol.
Redpanda is a brand-new product and implementation. Operations are different. The behavior of the engine is different. Experts are not available. Job offerings do not exist. And so on.
Kafka is significantly better documented, has a tremendously larger community of experts, and has a vast array of supporting tooling that makes operations more straightforward.
There are many local and online Kafka training options, including online courses, books, meetups, and conferences. You won’t find much for Redpanda beyond the content of the vendor behind it.
And don’t trust marketing! That’s true for every vendor, of course. If you read a great feature list on the Redpanda website, double-check if the feature truly exists and in what shape it is. Example: RBAC (role-based access control) is available for Redpanda. The devil lies in the details. Quote from the Redpanda RBAC documentation: “This page describes RBAC in Redpanda Console and therefore manages access only for Console users but not clients that interact via the Kafka API. To restrict Kafka API access, you need to use Kafka ACLs.” There are plenty of similar examples today. Just try to use the Redpanda cloud service. You will find many things that are more alpha than beta today. Make sure not to fall into the same myths around the marketing of product features as some users did with Apache Pulsar a few years ago.
The total cost of ownership and business value
When you define your project’s business requirements and SLAs, ask yourself how much downtime or data loss is acceptable. The RTO (recovery time objective) and RPO (recovery point objective) impact a data streaming platform’s architecture and overall process to ensure business continuity, even in the case of a disaster.
The TCO is not just about the cost of a product or cloud service. Full-time engineers need to operate and integrate the data streaming platform. Expensive project leads, architects, and developers build applications.
Project risk includes the maturity of the product and the expertise you can bring in for consulting and 24/7 support.
Similar to benchmarketing regarding latency, vendors use the same strategy for TCO calculations! Here is one concrete example you always hear from Redpanda: “C++ does enable more efficient use of CPU resources.”
This statement is correct. However, the problem with that statement is that Kafka is rarely CPU-bound and much more IO-bound. Redpanda has the same network and disk requirements as Kafka, which means Redpanda has limited differences from Kafka in terms of TCO regarding infrastructure.
When to choose Redpanda instead of Apache Kafka?
You need to evaluate whether Redpanda is the right choice for your next project or if you should stick with the “real Apache Kafka” and related products or cloud offerings. Read articles and blogs, watch videos, search for case studies in your industry, talk to different competitive vendors, and build your proof of concept or pilot project. Qualifying out products is much easier than evaluating plenty of offerings.
When to seriously consider Redpanda?
- You need C++ infrastructure because your ops team cannot handle and analyze JVM logs – but be aware that this is only the messaging core, not the data integration, data processing, or other capabilities of the Kafka ecosystem
- The slight performance differences matter to you – and you still don’t need hard real-time
- Simple, lightweight development on your laptop and in automated test environments – but you should then also run Redpanda in production (using different implementations of an API for TEST and PROD is a risky anti-pattern)
You should evaluate Redpanda against Apache Kafka distributions and cloud services in these cases.
This post explored the trade-offs Redpanda has from a technical and non-functional perspective. If you need an enterprise-grade solution or fully-managed cloud service, a broad ecosystem (connectors, data processing capabilities, etc.), and if 10ms latency is good enough and a few p99 spikes are okay, then I don’t see many reasons why you would take the risk of adopting Redpanda instead of an actual Apache Kafka product or cloud service.
The future will tell us if Redpanda is a severe competitor…
I didn’t even cover the fact that a startup always has challenges finding great case studies, especially with big enterprises like fortune 500 companies. The first great logos are always the hardest to find. Sometimes, startups never get there. In other cases, a truly competitive technology and product are created. Such a journey takes years. Let’s revisit this blog post in one, two, and five years to see the evolution of Redpanda (and Apache Kafka).
What are your thoughts? When do you consider using Redpanda instead of Apache Kafka? Are you using Redpanda already? Why and for what use cases? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.





