
Compacted Topic is a feature of Apache Kafka to persist and query the latest up-to-date event of a Kafka Topic. The log compaction and key/value search is simple, cost-efficient and scalable. This blog post shows in a success story of Intersport how some use cases store data long term in Kafka with no other database. The retailer requires accurate stock info across the supply chain, including the point of sale (POS) in all international stores.

What is Intersport?
Intersport International Corporation GmbH, commonly known as Intersport, is headquartered in Bern, Switzerland, but its roots trace back to Austria. Intersport is a global sporting goods retail group that operates a network of stores selling sports equipment, apparel, and related products. It is one of the world’s largest sporting goods retailers and has a presence in many countries around the world.
Intersport stores typically offer a wide range of products for various sports and outdoor activities, including sports clothing, footwear, equipment for sports such as soccer, tennis, skiing, cycling, and more. The company often partners with popular sports brands to offer a variety of products to its customers.

Intersport actively promotes sports and physical activity and frequently sponsors sports events and initiatives to encourage people to lead active and healthy lifestyles. The specific products and services offered by Intersport may vary from one location to another, depending on local market demand and trends.
The company automates and innovates continuously with software capabilities like fully automated replenishment, drop shipping, personalized recommendations for customers, and other applications.
How does Intersport leverage Data Streaming with Apache Kafka?
Intersport presented its data streaming success story together with the system integrator DCCS at the Data in Motion Tour 2023 in Vienna, Austria.
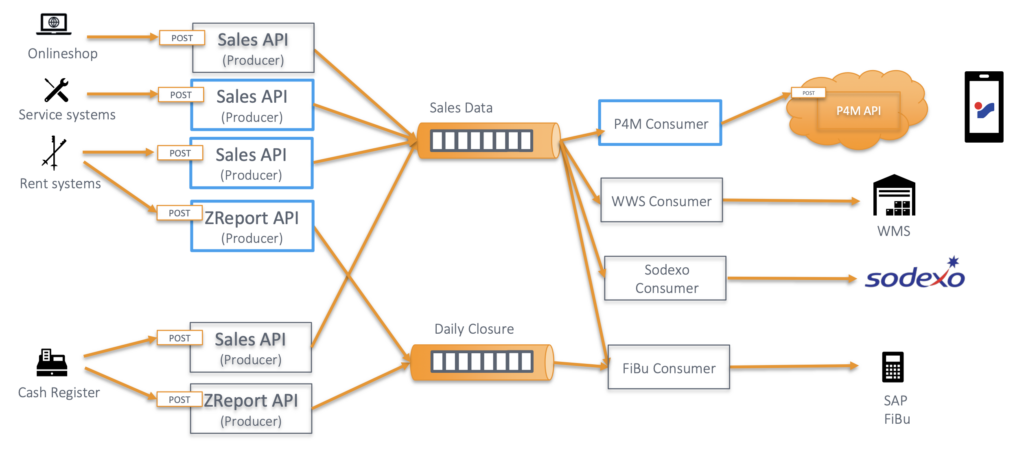
Here is a summary about the deployment, use cases, and project lifecycle at Intersport:
- Apache Kafka as the strategic integration hub powered by fully managed Confluent Cloud
- Central nervous system to enable data consistency between real-time data and non-real-time data, i.e., batch systems, files, databases, and APIs.
- Loyalty platform with real-time bonus point system
- Personalized marketing and hybrid omnichannel customer experience across online and stores
- Integration with SAP ERP, financial accounting (SAP FI) and 3rd Party B2B like bike rental, 100s of POS, and legacy like FTP and XML interfaces
- Fast time-to-market because of the fully managed cloud: The pilot project with 100 stores and 200 Point of Sale (POS) was finished in 6 months. The entire production rollout took only 12 months.
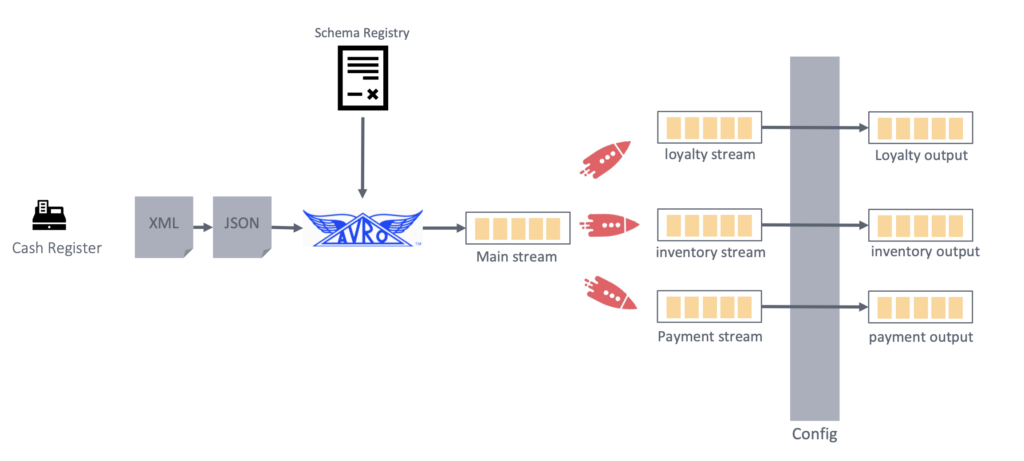
Is Apache Kafka a Database? No. But…
No, Apache Kafka is NOT a database. Apache Kafka is a distributed streaming platform that is designed for building real-time data pipelines and streaming applications. Users frequently apply it for ingesting, processing, and storing large volumes of event data in real time.
Apache Kafka does not provide the traditional features associated with databases, such as random access to stored data or support for complex queries. If you need a database for storage and retrieval of structured data, you would typically use a database system like MySQL, PostgreSQL, MongoDB, or others with Kafka to address different aspects of your data processing needs.
However, Apache Kafka is a database if you focus on cost-efficient long-term storage and the replayability of historical data. I wrote a long article about the database characteristics of Apache Kafka. Read it to understand when (not) to use Kafka as a database. The emergence of Tiered Storage for Kafka created even more use cases.
In this blog post, I want to focus on one specific feature of Apache Kafka for long-term storage and query functionality: Compacted Topics.
What is a Compacted Topic in Apache Kafka?
Kafka is a distributed event streaming platform, and topics are the primary means of organizing and categorizing data within Kafka. “Compacted Topic” in Apache Kafka refers to a specific type of Kafka Topic configuration that is used to keep only the most recent value for each key within the topic.
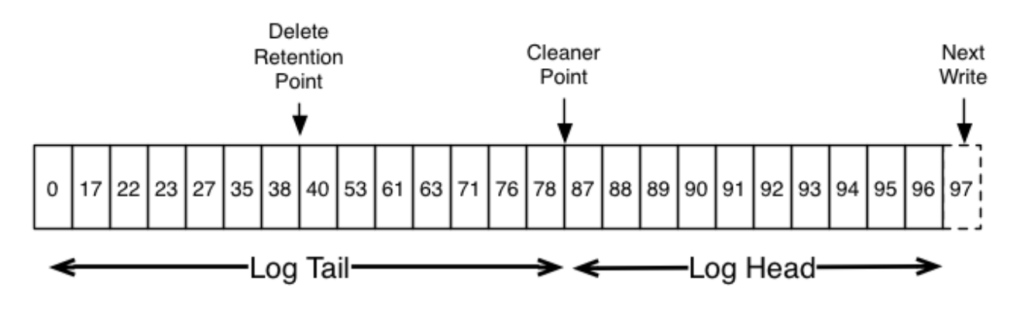
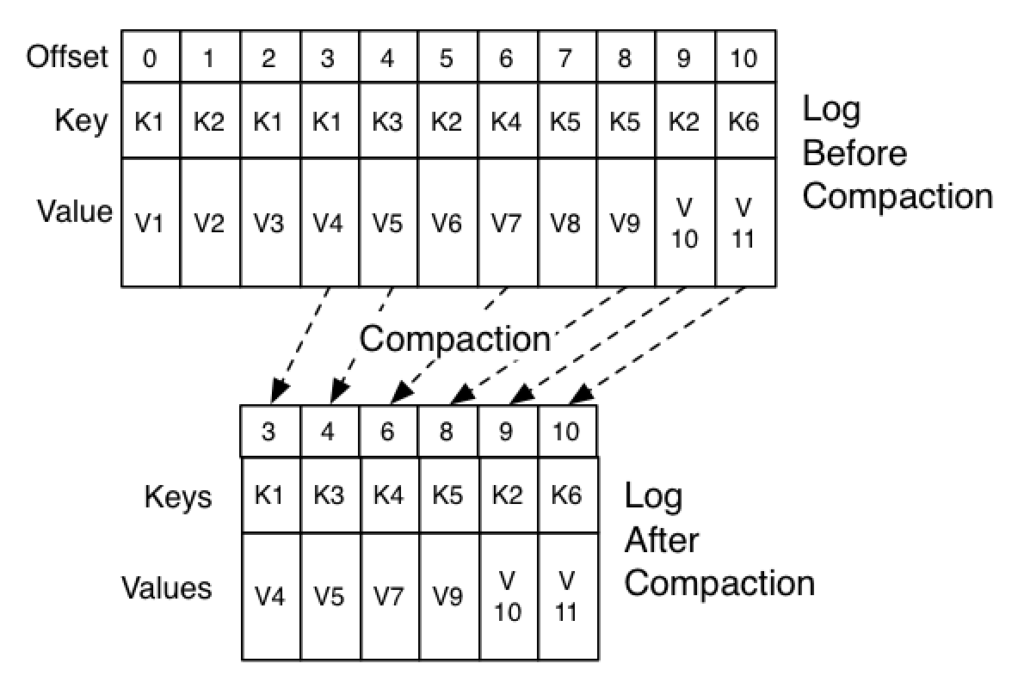
In a compacted topic, Kafka ensures that, for each unique key, only the latest message (or event) associated with that key is retained. The system effectively discards older messages with the same key. A Compacted Topic is often used for scenarios where you want to maintain the latest state or record for each key. This can be useful in various applications, such as maintaining the latest user profile information, aggregating statistics, or storing configuration data.
Here are some key characteristics and use cases for compacted topics in Kafka:
- Key-Value Semantics: A compacted topic supports scenarios where you have a key-value data model, and you want to query the most recent value for each unique key.
- Log Compaction: Kafka uses a mechanism called “log compaction” to ensure that only the latest message for each key is retained in the topic. This means that Kafka will retain the entire history of changes for each key, but it will remove older versions of a key’s data once a newer version arrives.
- Stateful Processing: Compacted topics are often used in stream processing applications where maintaining the state is important. Stream processing frameworks like Apache Kafka Streams and ksqlDB leverage a compacted topic to perform stateful operations.
- Change-Data Capture (CDC): Change-data capture scenarios use compacted topics to track changes to data over time. For example, capturing changes to a database table and storing them in Kafka with the latest version of each record.
Compacted Topic at Intersport to Store all Retail Articles in Apache Kafka
Intersport stores all articles in Compacted Topics, i.e., with no retention time. Article records can change several times. Topic compaction cleans out outdated records. Only the most recent version is relevant.
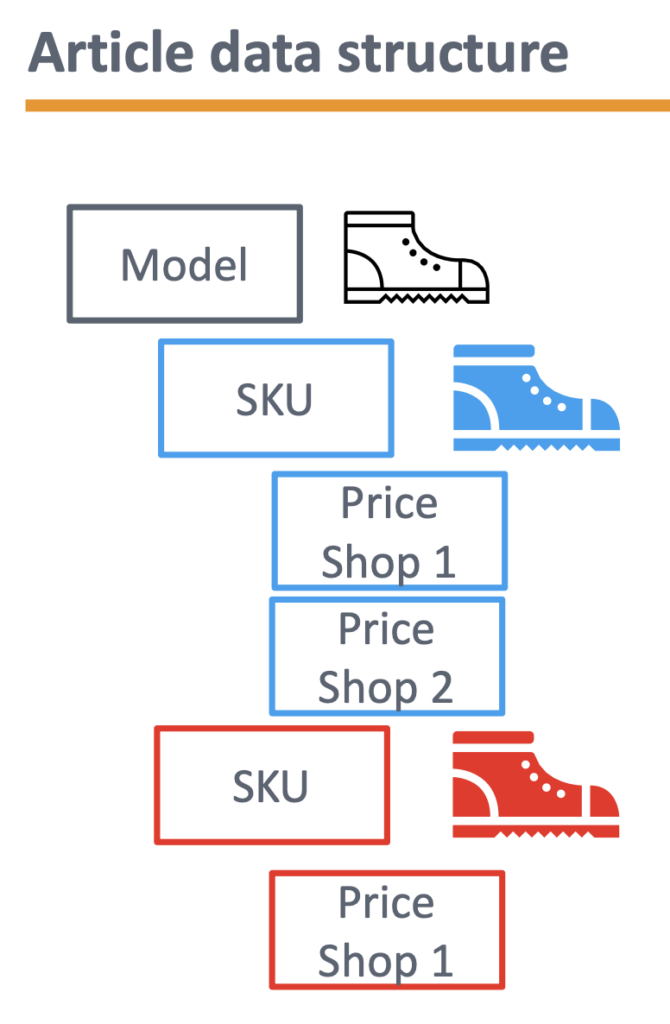
Article Data Structure
A model comprises several SKUS as a nested array:
- An SKU represents an article with its size and color
- Every SKU has shop based prices (purchase price, sales price, list price)
- Not every SKU is available in every shop
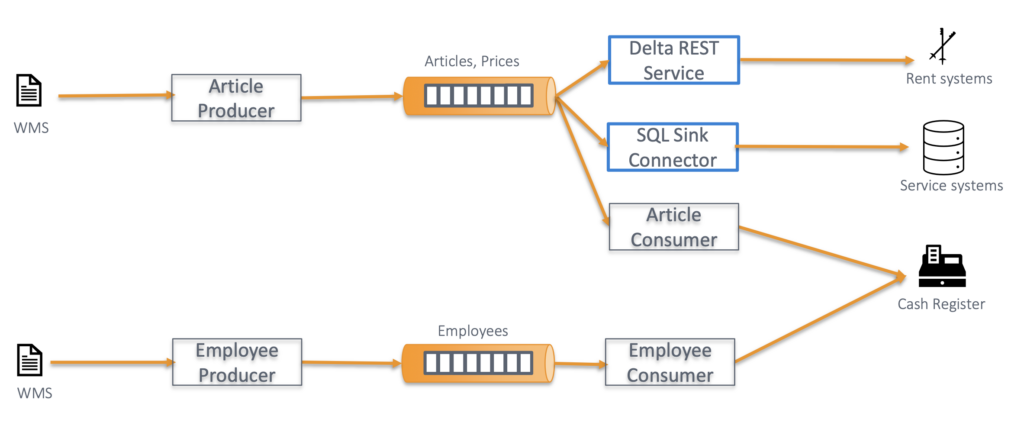
Accurate Stock Information across the Supply Chain
Intersport and DCCS presented their important points and benefits of leveraging Kafka. The central integration hub uses compacted topics for storing and retrieving articles:
- Customer facing processes demand real time
- Stock info needs to be accurate
- Distribute master data to all relevant sub system as soon as it changes
- Scale flexible on high load (shopping weekends before Christmas)
Providing the right information at the right time is crucial across the supply chain. Data consistency matters, as not every system is real-time. This is one of the most underestimated sweet spots of Apache Kafka combining real-time messaging with a persistent event store.
Log Compaction in Kafka does NOT Replace BUT Complement other Databases
Intersport is an excellent example in the retail industry for persisting information long-term in Kafka Topics leveraging Kafka’s feature “Compacted Topics“. The benefits are simple usage, cost-efficient event store of the latest up-to-date information, and fast key/value queries, and no need for another database. Hence, Kafka can replace a database for some specific scenarios, like storing and querying the inventory of each store at Intersport.
If you want to learn about other use cases and success stories for data streaming with Kafka and Flink in the retail industry, check out these articles:
- The State of Data Streaming in the Retail Industry
- Use Cases for Apache Kafka in Retail
- Real-Time Supply Chain with Apache Kafka in the Food and Retail Industry
- Kafka for Live Commerce to Transform the Retail and Shopping Metaverse
- Omnichannel Retail and Customer 360 in Real Time with Apache Kafka
- A Hybrid Streaming Architecture for Smart Retail Stores with Apache Kafka
- Apache Kafka is the New Black at the Edge in Industrial IoT, Logistics and Retailing
How do you use data streaming with Kafka and Flink? What retail use cases did you implement? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
