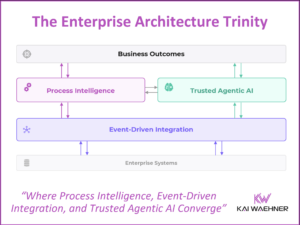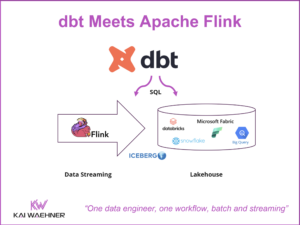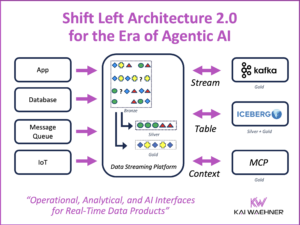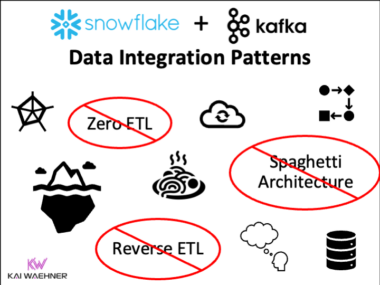
Snowflake Integration Patterns: Zero ETL and Reverse ETL vs. Apache Kafka
Snowflake is a leading cloud-native data warehouse. Integration patterns include batch data integration, Zero ETL and near real-time data ingestion with Apache Kafka. This blog post explores the different approaches and discovers its trade-offs. Following industry recommendations, it is suggested to avoid anti-patterns like Reverse ETL and instead use data streaming to enhance the flexibility, scalability, and maintainability of enterprise architecture.