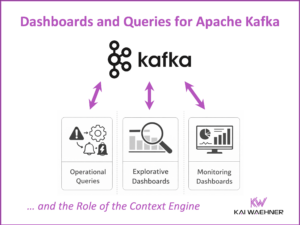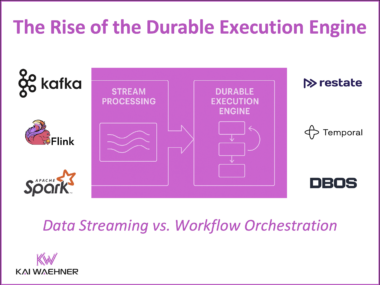
The Rise of the Durable Execution Engine (Temporal, Restate) in an Event-driven Architecture (Apache Kafka)
Durable execution engines like Temporal and Restate are redefining how developers orchestrate long-running, stateful workflows in distributed systems. Unlike traditional BPM tools focused on human-centric tasks, these engines automate machine-to-machine processes with built-in durability, retries, and fault-tolerant coordination. When integrated with event-driven platforms like Apache Kafka, they enable scalable, resilient architectures—handling complex business logic such as order processing, fraud detection, and multi-step transactions. This blog explores their capabilities, differences from stream processing tools like Apache Flink, Kafka Streams or Spark Structured Streaming, and the emerging role they play in modern enterprise infrastructure.